







前言
KNN算法
什么是KNN(K-Nearest Neighbor algorithm)
NN距离度量表示法
前言-远近有别
欧氏距离
来源:几何学
叙述:

//unixfy:计算欧氏距离
double euclideanDistance(const vector<double>& v1, const vector<double>& v2)
{
assert(v1.size() == v2.size());
double ret = 0.0;
for (vector<double>::size_type i = 0; i != v1.size(); ++i)
{
ret += (v1[i] - v2[i]) * (v1[i] - v2[i]);
}
return sqrt(ret);
}曼哈顿距离
来源:城市交通
 norm (see Lp space), city block distance, Manhattan distance, or Manhattan length, with corresponding variations in the name of the geometry.
norm (see Lp space), city block distance, Manhattan distance, or Manhattan length, with corresponding variations in the name of the geometry.
叙述:


切比雪夫距离(Chebyshev distance/ Tchebychev distance/chessboard distance)
来源:国际象棋

叙述:



闵可夫斯基距离(Minkowski Distance)
来源:
叙述:



标准化欧氏距离 (Standardized Euclidean distance )
来源:
标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。至于均值和方差标准化到多少,先复习点统计学知识。
假设样本集X的数学期望或均值(mean)为m,标准差(standard deviation,方差开根)为s,那么X的“标准化变量”X*表示为:(X-m)/s,而且标准化变量的数学期望为0,方差为1。
即,样本集的标准化过程(standardization)用公式描述就是:

标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:

马氏距离(Mahalanobis Distance)
来源:计算两个位置样本集的相似度
马氏距离是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。
叙述: The Mahalanobis distance of an observation


Mahalanobis distance (or "generalized squared interpoint distance" for its squared value) can also be defined as a dissimilarity measure between two random vectors 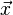 and
and  of the samedistribution with the covariance matrix S:
of the samedistribution with the covariance matrix S:

If the covariance matrix is the identity matrix, the Mahalanobis distance reduces to the Euclidean distance. If the covariance matrix is diagonal, then the resulting distance measure is called anormalized Euclidean distance:

where si is the standard deviation of the xi and yi over the sample set.















 3804
3804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









