






 本文深入探讨了VRF(虚拟路由转发)技术的原理及其在Linux系统中的实现细节。从VRF的基本概念出发,分析了VRF与策略路由的关系,以及如何解决传统策略路由带来的网卡隔离问题。此外,还介绍了Linux VRF的使用方法和配置技巧,以及其在不同内核版本中的实现差异。
本文深入探讨了VRF(虚拟路由转发)技术的原理及其在Linux系统中的实现细节。从VRF的基本概念出发,分析了VRF与策略路由的关系,以及如何解决传统策略路由带来的网卡隔离问题。此外,还介绍了Linux VRF的使用方法和配置技巧,以及其在不同内核版本中的实现差异。
动机
明天,是2017年9月24日,两年前的明天,我从上海第一次来到深圳参加面试,两年前的今天,此时我还在上海虹桥机场等候延误的飞机,两年前的今晚,我在深圳南山区南新路片区徘徊,企图能在南方城市找到一家东北烧烤,并且欣赏这座城市(最终我找到了!),两年前的明晚,我喝了一瓶750ml的威士忌,次日返回上海…面试后,我感觉我被录取了,然后做了一个决定,举家再次搬迁,来到了深圳,在上海留下了我的空房和我的足迹…这是个值得纪念的日子。
本文依旧是一篇聊点技术的散文。
马上要放长假了,放假前的最后一个周末,总结了一个没有深度但很常用的主题,这便是VRF(虚拟路由转发),第一次接触这个概念是在2004年底,也就是在大学的前几堂课(我相信本科是不会讲这个的,我们是真正的技校,就业为导向,所以我们讲这个,不过我承认,我那99.99%的同学们直到现在可能就接触过这仅有的一次VRF概念…),后面就喜欢上了网络和通信,不过说实话真正使用VRF的时候并不多,毕竟作为程序员能接触到的网络环境非常有限,即便如此,我还是希望这篇文章能帮到想深入了解VRF的人们。
写这篇文章的另外一个动机来自于愤怒,因为当我希望学习一点新东西的时候,我总是找不到中文资料(我的英文水平比较Low,相信大多数人也比我好不到哪去),所以我必须自己写一篇或者持续写几篇,比如nftables,BBR这种…对于Linux的VRF实现而言,它来自于Linux 4.3内核,到如今已经有段时间了,然而网上依然没有中文资料,这是写作本文的最大动机。
Linux实现VRF之前
VRF是一个基本上玩网络的人都懂的概念,同时作为一个Linux粉的话,你肯定会问一个问题,Linux如何配置VRF?毕竟Linux诞生于网络,其网络技术一直都是紧随业界潮流的。
然而搜到的答案几乎千篇一律是使用net namespace,诚然,net namespace几乎没有什么它做不到的,它都可以在你的一台机器上模拟出多个完整的协议栈,还有什么做不到的呢?问题是,这么做有没有必要?!
提前剧透一点,VRF就是一台物理设备虚拟成多台路由器,net namespace可以把整个协议栈都给虚拟了,难道还不能虚拟一台路由器吗?然而我们知道的一个事实却是,路由器不需要完整的协议栈的,只需要虚拟到第三层就可以了,因此,net namespace对于VRF而言,太重了。我们看下net namespace的结构:
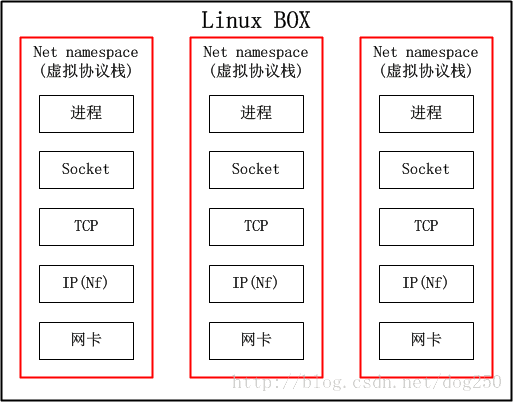
说白了,如果不考虑内存,CPU等其它共享的资源,仅仅从网络的角度来看,net namespace就跟个虚拟机一样,这样的隔离对于VRF来讲实属无必要!因此,Linux一定可以有更好的方案实现VRF。不过遗憾的是,直到Linux 4.3内核,VRF都没有得到实现,我曾经长期基于Linux 2.6.8和2.6.32内核工作,没有发现VRF,因此我不得不用复杂的策略路由配合同样复杂的iptables规则来模拟VRF的表现,工作量之巨大让我放弃了多少个周末和假期…
事实上,我在2012年底的时候就想在Linux实现一个完备的VRF,因为我实在要用到它。后续我用超级复杂的iptables,策略路由,自定义Netfilter模块实现了类似VRF的功能,也就不再想这个事了,再后来,我彻底离开了这个领域,就几乎把它忘掉了,然而在我例行Review新内核新特性的时候,我发现Linux如今的VRF已经实现得相当好
了。
这就是我写本文的前奏背景,以下是正文。
VRF的原理
由于本节仅仅介绍原理,为了简单起见,我是仅仅把Linux BOX当成转发设备看待的,这更容易理解,所以我忽略本机始发并路由出去的流量的。因此这部分流量的处理逻辑我并没有画在图中,特此声明。
考虑下面的拓扑:
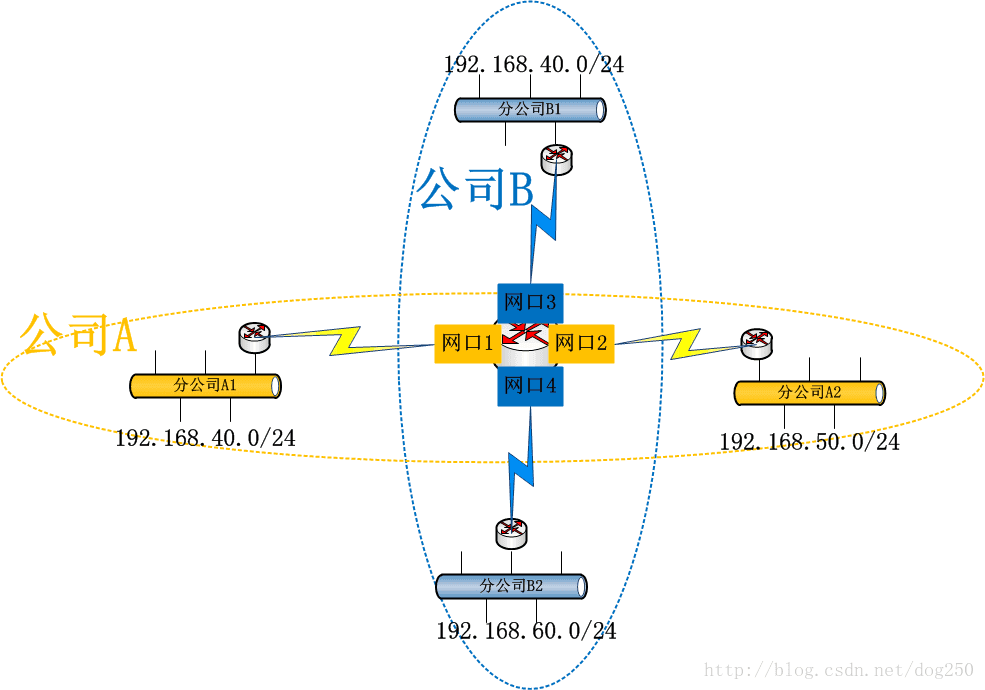
A和B是两个独立的公司,通过某种VPN技术来互联,但是A的分公司A1,A2和B的分公司B1,B2都使用192.168.0.0/16这个私有网段,并且它们的流量全部都通过公共路由器R,这让路由器R如何抉择哪个192.168/16段的IP地址是A分公司的,哪个是B分公司的…
也许你会说,这种IP地址分配方案是不合理的,毕竟IP地址的唯一性是构建可路由的IP网络的首要前提啊!但是,你有所不知,VPN的本旨就是要做到专网专用,它本来
可能就没打算在公网上路由流量,只是逻辑上小机构互通即可,公网对于VPN而言只是一个载体。逻辑上互通的机构可能在地理位置上有所交叉重叠,所以就会带来上述的问题,如何解决呢?那势必是策略路由啦!
首先我们来看一下策略路由的原理:
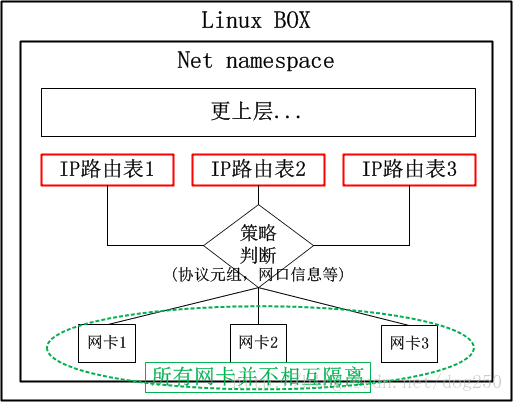
对于上述的场景,很显然,我们需要以下的策略路由:
in 网口1 table A
in 网口2 table A
in 网口3 table B
in 网口4 table B系统内置了两张路由表,公司A和公司B分别有一张路由表,数据从特定网卡收到后,各查各的路由表即可。貌似很不错的一个解决方案,有没有什么问题呢?
如果说配置管理员不小心把“网卡1”写成了“网卡3”怎么办?特别是,如果网卡特别多,接入的企业也非常多,岂不是更加难以管理和维护吗?问题就出在:
这些网卡相互之间并非隔离的,依靠策略隔离的仅仅是路由表
那么,如何解决这个问题呢?换句话说,有没有什么解决方案是专门保证三层隔离的前提下隔离网卡的呢?答案当然汗牛充栋,比如net namespace就可以,但对于路由器而言,这种方式过于重量级了,对于路由器而言,只需要一个Layer 3的隔离方案即可!在网络技术中,有一个叫做VRF的概念正好就是做这个的。什么是VRF?
VRF顾名思义就是虚拟路由转发(Virtual Routing Forwarding),简单点来讲,就是把一台路由器当多台虚拟路由器来用,这种技术在二层就是VLan技术,或者更加通用的虚拟交换机(在多网卡的Linux BOX上,创建多个bridge设备并把不同的网卡加入其中,就是一台携带多个虚拟交换机的物理交换机),我把二层的方案列如下:

那么,三层的VRF自然而然就是下面的样子咯:
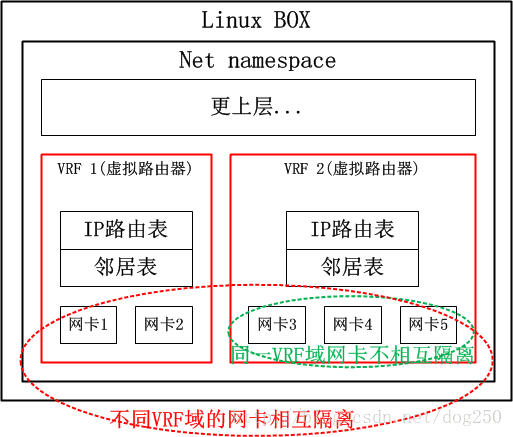
现在考虑一个非常常见的场景,即OpenVPN典型的多处理拓扑,在一台服务器上会构建超级多的TAP网卡,每个TAP服务一个特定的VPN客户端,有了VRF的支撑后,不同的VPN节点便可以使用相同的IP网段了,所要做的仅仅是将不同的TAP网卡置入不同的VRF域即可。
大致明白了VRF的原理之后,我们来看一下VRF和策略路由的关系。
我们已经知道VRF是一台物理路由器当多台虚拟路由器使用的,那么在这多台虚拟路由器之间就必须做到从物理层到三层路由的全部隔离(请注意,路由器是个三层设备),而策略路由仅仅是路由表的隔离,甚至在仅仅使能了策略路由的路由器上,其二层三层之间的邻居表都是共享的。不过,策略路由确实是实现VRF的组件之一,它确实可以完成VRF的路由表隔离,本文的后续可以看到,Linux正是使用策略路由来实现VRF路由表隔离的。
但是仅仅依靠策略路由机制是无法构建完整的VRF体系的,为了实现二层隔离以及网卡的隔离,还需要另外的技术,Linux的VRF实现中,采用了一种叫做L3mdev的技术来支持一种三层的虚拟网卡,利用这种虚拟网卡来隐藏网卡之间的可见性。
欲知详情,请继续阅读。
Linux VRF的使用和配置
本节是例行的一节,如果你都没让系统跑起来就去研究它的原理,那势必是本末倒置的,研究技术的目的是更好地使用技术,所以必然要先用起来VRF。
但我不准备在本节着墨太多,因此我选择了引用的方式。因为几个老外已经把使用和配置写得淋漓尽致了,这些东西,我再写也只是复制粘贴,显得毫无意义,因此我引用他们写好的东西,同时,作为补充,本节以下我写一些他们没有提到的东西。
本节的重点就是下面几个链接,文章都不长,全部都是Step by step式的Howto,请把它们看完,你将学会Linux VRF的使用方法!
- Virtual Routing and Forwarding (VRF) Document:https://www.kernel.org/doc/Documentation/networking/vrf.txt
- Virtual Routing and Forwarding (VRF):https://github.com/Mellanox/mlxsw/wiki/Virtual-Routing-and-Forwarding-(VRF)
- Lwn-net: VRF support:https://lwn.net/Articles/632522/
- Working with VRF on Linux:http://www.routereflector.com/2016/11/working-with-vrf-on-linux/
- Using VRFs with linux:https://andir.github.io/posts/linux-ip-vrf/
这些文章详细描述了Linux VRF的配置技巧,同时提到了一些版本实现的差异所带来的后果,你必须看完并且亲自动手实践了,然后再去了解Linux VRF的实现。
以下的内容是为懒人准备的,如果你看了Linux VRF的实现没有看明白,或者说根本就不想看,那么请接着看本文下面的部分。
Linux VRF实现概览
要说实现,虚拟网卡!虚拟网卡!还是虚拟网卡!不然的话我也不会写下本文的,我是在Review新特性的时候,例行扫描drivers/net目录时扫到了vrf.c说是实现了一块虚拟网卡,然后才进一步分析的。
我很喜欢这目录里的玩意儿,从OpenVPN使用Tap/Tun,IPSec VTI,到Bridge,Bonding,VLan,VXLan…这些在Linux系统中,全部基于虚拟网卡来实现!总体来讲,所有这些虚拟网卡,最终都要有真实的东西附着在上面,比如:
- 附着字符设备在上面的:OpenVPN的Tun/Tap网卡
- 附着物理网卡的:Bridge,Bonding,VLan
- 附着加密引擎的:VTI
…
本文提到的VRF也是基于虚拟网卡实现,每一个VRF域都表现为一个虚拟网卡,然后将具体的物理网卡(或者是别的虚拟网卡)添加到特定的VRF虚拟网卡,从而实现隔离:

可见,VRF虚拟网卡实现了三层逻辑,该三层逻辑就是VRF路由表隔离,具体的实现细节下面的小节会结合代码详述,本节只是给出概览。
Linux VRF的实现细节
Linux内核在4.3版本中引入了VRF的支持,说实话这让我等了好久,等到Linux真的提供了VRF机制时,我早已不做这东西了!
总体来讲,Linux的VRF机制的实现过程和Linux CFS调度器实现的过程非常类似,也是分了两个阶段:
CFS实现两阶段:
- 2.6.23内核~2.6.27内核:第一阶段基础版。复杂版的CFS
- 2.6.27内核以后:第二阶段完备版。朴素版的CFS
VRF实现两阶段:
- 4.3内核~4.8内核:第一阶段基础版。基础设施不完善,需要外部策略路由规则配合才可用
- 4.8内核以后:第二阶段完备版。引入了L3mdev,完善的基础设施支持
在第一阶段的实现中,VRF的实现非常简单。我先给出一个总的图景,再细说:
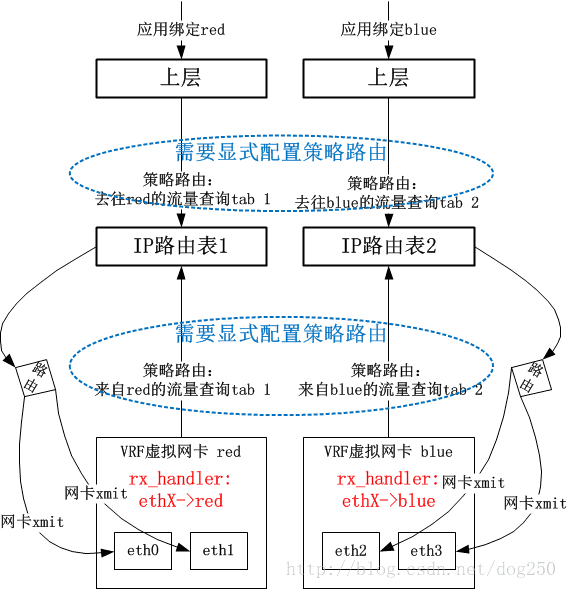
数据包在被物理网卡ethX接收后,在netif_receive_skb中,会有rx_handler回调来截获数据包。VRF会注册一个rx_handler回调,该回调中将skb的dev字段替换为VRF虚拟网卡Device对象,这个处理是和Bridge处理一致的。接下来,系统依赖以下的事实来实现VRF逻辑:
- 数据包skb的dev字段已经是VRF设备,表明数据包看起来是通过VRF X来接收的
- 用户显式配置的Policy Routing的rule要求来自VRF X接收的数据包要查询X号路由表
这就实现了VRF逻辑。
可以看到,用户需要自己来手工完成策略路由表的定向操作,这个配置是重点,没有它的话,便不会让VRF网卡接收的数据包查询策略路由表。
这明显是一种很初级但可用(我的做法确实Low,但是就是可用!这是Linux的一种典型的文化)的做法。很自然的,Linux 4.8内核开始,VRF有了第二阶段的实现方法,省略了用户自己手工配置策略路由这个步骤。
在Linux 4.8内核以及以后,系统提供了一种更加优雅的做法,即引入了一个叫做L3mdev(Layer 3 master device)的机制,有了这个L3mdev机制,便省去了显式配置策略路由的必要。在创建一个VRF虚拟网卡的时候,系统便将其与一个特定的策略路由表自动关联,L3mdev机制基于这种关联来完成策略路由表的定向操作。
这种L3mdev机制事实上相当于又一个3层的Hook,该Hook将感兴趣流量伪装成从一个虚拟网卡接收,用该虚拟网卡来实现一些特定于3层的处理逻辑,这种风格实际上只是利用了虚拟网卡,而并不是非用不可。
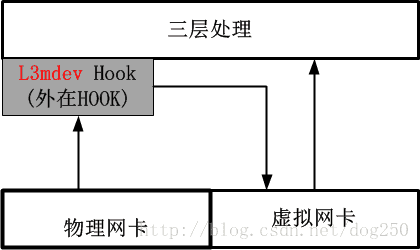
我们对比一下4.8内核之前的处理方法,就知道如今的L3mdev有多么高尚了,老的注册rx_handler回调的方法如下图:
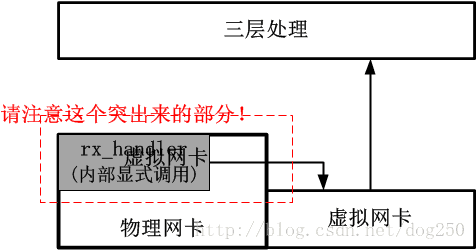
可以看出,4.8内核之后的方法十分优雅,它几乎不触动不影响不破坏任何既有的处理逻辑。新的实现是高尚的!
现在,我给出采用新的L3mdev机制的VRF实现框图(请与老的rx_handler回调方式做对比):
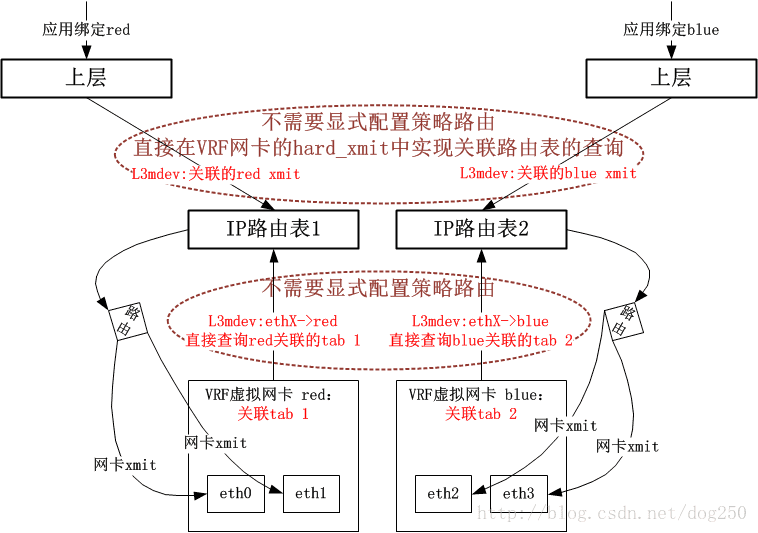
以上就是VRF实现的总体架构了,接下来我会给出一些细节,在分析这些细节之前,我先将VRF的实现分成了两个部分:
- 控制路径部分
这部分主要控制VRF虚拟网卡的创建,策略路由表的关联等。 - 数据路径部分
这部分主要描述数据时如何通过VRF路由的。
控制路径的实现逻辑
当我们创建了一个VRF域的时候,发生了什么?我想下图是可以解释的:
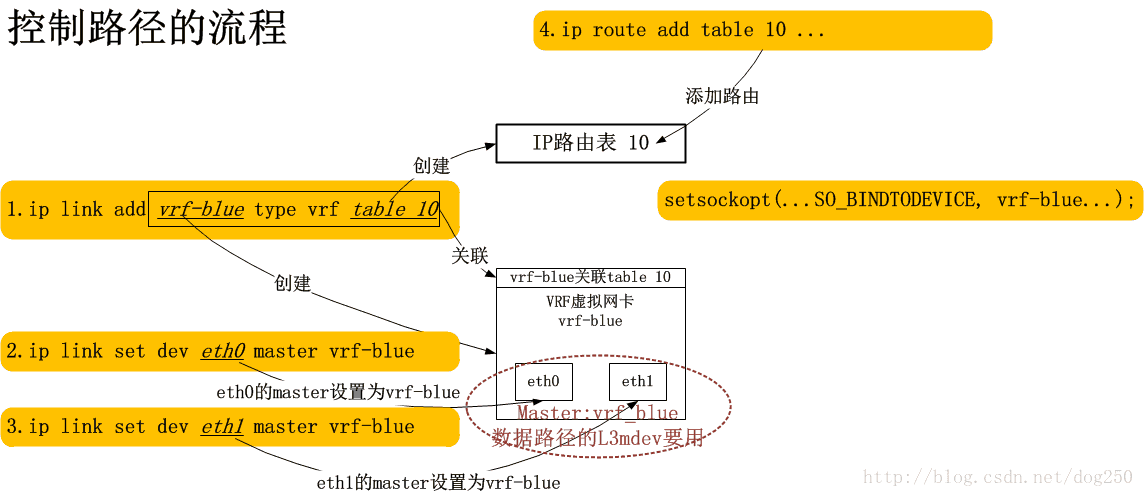
简单点说,每一条命令都为最终的数据通道基础设在施添砖加瓦,最终构建一条完备的数据通道。
数据路径的实现逻辑
以下(即Linux 4.8及以后的VRF内核实现)来用两个情景分析的方式阐述VRF的实现,通过这两个情景分析,基本上VRF的实现也就了然于胸了。(如果我这里的论述显得晦涩,那就权当是提纲吧,这部分代码很简单,自己走读一下即可)
网卡收包过程的VRF实现分析
从独立的物理网卡,比如eth0收到数据包,依次经过网卡驱动程序,netif_receive_skb,ip_rcv等调用,直到ip_rcv_finish被调用之前,VRF的逻辑和非VRF逻辑并没有任何不同支持,在ip_rcv_finish中,事情起了变化:
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
struct net_device *dev = skb->dev;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
// 这里增加了这么一个L3mdev调用,正是该L3mdev逻辑的处理,实现了VRF的核心:路由表使用与VRF域关联的策略路由表
skb = l3mdev_ip_rcv(skb);
// 后面的逻辑直到定位路由表,VRF逻辑和常规逻辑没有任何不同
...
}具体来讲,l3mdev_ip_rcv的逻辑非常简单,对于VRF而言,实现l3mdev_l3_rcv回调函数完成的功能仅仅是:
- 将skb的dev字段重新修改为该dev的master设备,即该物理网卡附着的VRF虚拟网卡设备
仅此而已!
我们接下来看下上述的l3mdev_ip_rcv里做的关于skb的dev字段的修改在什么时候会用到。可以想象的是,当然是在定位策略路由表的时候用的咯,问题是,在代码层面这是怎么实现的。
我们跳过中间步骤,直达策略路由表的定位,在定位路由表的时候,实际上是在定位一个rule,系统会遍历所有的rules链表,比较典型的rules链表可以通过下面的命令查看:
ip rule ls一般情况下,我们会看到以下结果:
0: from all lookup local
32766: from all lookup main
32767: from all lookup default 然而,当我们配置了至少一个VRF域的时候,我们将会看到如下的结果:
0: from all lookup local
1000: from all lookup [l3mdev-table]
32766: from all lookup main
32767: from all lookup default 嗯,多了一个l3mdev-table,系统在遍历rules链表的时候,遇到[l3mdev-table]表的时候,采用的是一种隐式的处理方式。意思是说,即便你创建了多个VRF域,关联了多张策略路由表,系统中依然只能看到一张[l3mdev-table]表。既然这样,系统又是如何定位到与特定的VRF域关联的那张路由表呢?比如说,vrf-blue关联了路由表10,vrf-red关联了路由表20,此时正在处理的包属于vrf-blue,系统如何定位到要查找路由表10而不是路由表20呢?
为了了解[l3mdev-table]的工作方式,就需要看下fib_rule_match的逻辑:
static int fib_rule_match(struct fib_rule *rule, struct fib_rules_ops *ops,
struct flowi *fl, int flags,
struct fib_lookup_arg *arg)
{
int ret = 0;
...
// 前面的逻辑是常规的iif,oif,mark等匹配,以下的这个l3mdev不一般!
// rule->l3mdev即ip rule ls看到的那个[l3mdev-table]
if (rule->l3mdev && !l3mdev_fib_rule_match(rule->fr_net, fl, arg))
goto out;
ret = ops->match(rule, fl, flags);
out:
return (rule->flags & FIB_RULE_INVERT) ? !ret : ret;
}我们重点看下l3mdev_fib_rule_match:
int l3mdev_fib_rule_match(struct net *net, struct flowi *fl,
struct fib_lookup_arg *arg)
{
struct net_device *dev;
int rc = 0;
rcu_read_lock();
... // 我们仅仅分析iif情景
dev = dev_get_by_index_rcu(net, fl->flowi_iif);
// 如果这个dev是一个VRF master虚拟网卡设备
if (dev && netif_is_l3_master(dev) &&
dev->l3mdev_ops->l3mdev_fib_table) {
// 那么便通过其自身的回调函数取出和该VRF关联的策略路由表!
arg->table = dev->l3mdev_ops->l3mdev_fib_table(dev);
rc = 1;
goto out;
}
out:
rcu_read_unlock();
return rc;
}到此为止呢,我们的一幅图景就闭合了:
- 首先在ip_rcv_finish的l3mdev_ip_rcv调用中定位到与收包物理网卡关联的VRF master虚拟网卡
- 然后在fib_lookup内层的l3mdev_fib_rule_match调用中取出与VRF master虚拟网卡关联的策略路由表
- 最终在该特定的路由表中进行路由查找
毕!
本地始发包的VRF实现分析
接下来我们看下本地发包的情景。
由于本地的数据包全部来自于某个socket而不是网卡,socket是不和网卡关联的,所以IP层在查路由之前无法知道一个数据包和哪个网卡关联,就更别提去选择使用哪张路由表了…
因此,如若一个socket程序想使用VRF机制,就必须为一个socket去绑定一个特定的网卡:
setsockopt(sd, SOL_SOCKET, SO_BINDTODEVICE, vrf_dev, strlen(vrf_dev)+1);有了这个调用,在ip_queue_xmit中查找路由的时候,自然就会在fib_rule_match中定位到与参数vrf_dev关联的策略路由表了,然而,如果socket程序并不知情,它只是bind了一个隶属于该vrf_dev的slave物理网卡,比如eth0,那要怎么处理呢?
显然SO_BINDTODEVICE参数会为数据包在__ip_route_output_key_hash调用中的路由查找失败而负责,为其暂时绑定一个dummy dst_entry,从而逻辑可以到达__ip_local_out:
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
/* if egress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_out(sk, skb);
...
}和网卡收包过程的l3mdev调用一样,我们看下这个与l3mdev_ip_rcv相对的l3mdev_ip_out调用里做了什么文章,实现对应回调函数的是vrf_ip_out:
static struct sk_buff *vrf_ip_out(struct net_device *vrf_dev,
struct sock *sk,
struct sk_buff *skb)
{
struct net_vrf *vrf = netdev_priv(vrf_dev);
...
// 取出VRF关联的那个唯一的dst_entry,以便将数据包定向到vrf_xmit
rth = rcu_dereference(vrf->rth);
if (likely(rth)) {
dst = &rth->dst;
dst_hold(dst);
}
...
skb_dst_set(skb, dst);
return skb;
}很简单,在这里仅仅是将skb的那个dummy dst_entry换成了和VRF设备绑定的那个dst_entry。
事实上,与VRF设备绑定的dst_entry只有一个且只做一件事,那就是,调用VRF设备的dev_hard_xmit回调函数,VRF机制正是在该dev_hard_xmit回调函数中实现了真正的路由查询,在dev_hard_xmit回调中真正做事的函数是vrf_process_v4_outbound:
static netdev_tx_t vrf_process_v4_outbound(struct sk_buff *skb,
struct net_device *vrf_dev)
{
struct iphdr *ip4h = ip_hdr(skb);
int ret = NET_XMIT_DROP;
struct flowi4 fl4 = {
/* needed to match OIF rule */
// 这个会让l3mdev_fib_rule_match定位到正确的路由表
.flowi4_oif = vrf_dev->ifindex,
.flowi4_iif = LOOPBACK_IFINDEX,
.flowi4_tos = RT_TOS(ip4h->tos),
.flowi4_flags = FLOWI_FLAG_ANYSRC | FLOWI_FLAG_SKIP_NH_OIF,
.daddr = ip4h->daddr,
};
struct net *net = dev_net(vrf_dev);
struct rtable *rt;
// 真实查路由
rt = ip_route_output_flow(net, &fl4, NULL);
...
// 真实发送skb
ret = vrf_ip_local_out(dev_net(skb_dst(skb)->dev), skb->sk, skb);
...
}整个流程就这样结束了!
到此为止,我可以给出一幅整个的图景了,结合源代码观摩,定有收获:
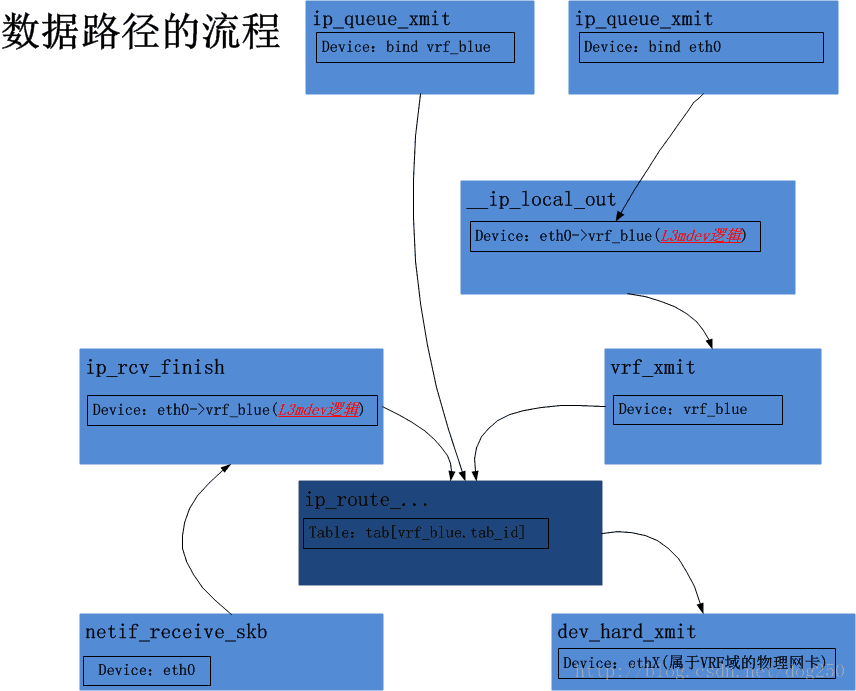
关于Linux VRF的小Trick
突然觉得Linux自2.6.32以来真的更新了太多,和本文相关的,有两个问题,首先是local路由表的问题,其次是TCP Listener的问题,和本文不相关的还有一个命令行问题,听我细说。
Local路由表问题
早在几年前的时候,我曾经抱怨说:
数据包来了之后首先要看看是不是本地接收的
要想理解这个,首先你得知道Linux系统中策略路由表匹配的原理。很简单,就是一个典型的switch-case语句:
switch elements:
case rule1:
table=tab1
break;
case rule1:
table=tab1
//fall through; 即匹配下一条rule
case rule1:
table=tab1
break;
default:
unreachable? // 或者任意别的什么...这在Linux的网络协议栈实现中体现为要先强制查询Local路由表,然后再查Main路由表…这个顺序并不意味着什么大不了的事,关键在于,曾经Local路由表全系统仅此一张,因此,如果本机的应用层有两个属于不同VRF域但是却侦听同一个IP地址的服务,势必会造成混乱,早先的系统中,唯一的Local路由表是IP路由系统第一个无条件要查询的,它可以绕过任何其它的路由判断,包括策略路由表,即Local路由表必须在策略路由表之前被匹配,如果不成功才Fall through到后面的路由表。
然而,在引入VRF后,Local表不再是全局唯一的了,每一个VRF域都有一张Local路由表,当你把一个网卡添加进一个VRF域的时候,此网卡相关的Local路由将全部重置到此VRF域的Local路由表中。
然而,全局来看,系统中还是会有一张Local路由表,它看起来在所有rule匹配之前被匹配,不过事情起了变化。当你看到下面的策略路由表时:
0: from all lookup local
1000: from all lookup [l3mdev-table]
32766: from all lookup main
32767: from all lookup default你可通过下面的命令删除Local表(请注意,这在低版本的内核以及iproute2中是不允许的):
ip rule del pref 0但为了避免你使用的ssh即时中断(其实是为了做到无缝切换),你要在del之前先add,因此整个切换过程的脚本变成了下面的样子:
ip rule add pref 30000 table local
ip rule del pref 0即你在添加一条策略路由前,必须先添加一条。
这也是人之常情了。然后,你会发现,事情的局面变成了下面的样子(当你再次执行ip rule ls时):
1000: from all lookup [l3mdev-table]
30000: from all lookup local
32766: from all lookup main
32767: from all lookup default 了解了这个事实之后,我们明白了,解决之道当然是隔离。看懂了这个ip rule ls的显式,我们的心情安顿了,是的,Linux的VRF做到了完全的三层隔离。
TCP Listener问题
对于本地始发的流量,我们知道,必须要为其通过显式的setsockopt调用绑定一个VRF设备才能终安,道理是这样,事实也是这样。
由于绑定VRF虚拟网卡设备的setsockopt是针对特定socket的,如果我们仅仅针对Listener socket做了这样的setsocketopt(事实上我们也仅仅能这么做),那么对于别的那些被这个Listener socket给Accept的那些socket,谁来负责呢(需要一种机制,让所有相关的socket都绑定VRF网卡)?
嗯,我们实在没有必要在accept返回后为每一个返回的client socket都去bind一个VRF device,系统可以自动做到这一点:
sysctl -w net.ipv4.tcp_l3mdev_accept=0OK,这就好了!
该内核参数的另一个作用是,自动识别那些从隶属于某个VRF域的网卡上收到的数据包所属的具体VRF域
VRF的命令行
不像net namespcace那样,可以在任意namespace运行网络程序,比如:
ip netns exec ns1 ping 1.1.1.1它的意思是,在命名空间ns1运行ping 1.1.1.1这个命令,然而我无法说出下面的祈使句:
在VRF vrf-blue这个虚拟路由器里运行ssh root@1.1.1.1
至少,目前为止我没有看到有类似:
ip vrf exec vrf-blue ssh root@1.1.1.1这样的命令行。如果有了,请告诉我…
后记
写完这篇笔记已经是接近中午了,本周六是我很少见的一次竟然睡到了6点多,这次跟小小一起起床,显然这只是培养学霸的开始,小小在看书学习,我在写文章…
不过,我坚决反对小小如此地热爱学习,她应该做的是做一些学校里不教的有意义的东西,我不反对看书,但我反对看教科书,我也反对做作业,看书,应该看一些有意义的书。我并不认为大早上起来去写作业或者很晚了不睡在背诵课文就是所谓的好学生,我的态度正好相反。
也许吧,是我的行为潜移默化的结果…
本周末,感慨太多,摇滚乐相伴,看着小小健康成长,心底感谢所有的老师教我知识,所有的领导给我机会,爸爸,妈妈伴我成长,曾经楼下便利店的老板带着微笑卖给我香烟啤酒…昨晚和老同事聊天到深夜,再次听了《漂洋过海来看你》(李宗盛,李宗师的版本[原作者]总是最好的,别的都扯淡装逼),深谙了理查德.克莱德曼的《星空》,回忆了往事,流了泪,手刃了步进马达,就差给我妈打个电话…这就是人生吧,嗯,这就是人生,不需要练习。

















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









