






从看一篇论文开始:Performance Evaluation of TCP BBRv3 in Networks with Multiple Round Trip Times,结论比较悲观:
- 虽然 BBRv2/3 试图解决 BBRv1 的公平性问题,但结果依旧不够理想,BBR 的迭代依旧任重而道远。
BBR 即使到了 v3 也依然不能论证稳定收敛,也因此它没办法成为默认拥塞控制算法。工程界和学界虽越发成为熟人社会卷得厉害,以前也不入流的东西最后可能通过类似 “送礼”,“互捧”,“交易” 的途径就能标准化,但下限至少是能基本论证稳定和收敛,BBR 目前还差点。
总体而言,此文观点很明确且有用,比提出个优化点,实验室用 mininet,ns3,tc 模拟仿真一下吊打原生算法几十个百分点,然后水一篇论文强很多,说实话那些东西也只是像我这样没事写篇随笔发个朋友圈的水准。也许稍微好一点,也许还不如我,谁知道呢。
本文剩下的部分主要谈 BBR 内部公平性,展示它的难度,最后以描述外部公平性同样难甚至更难结尾。
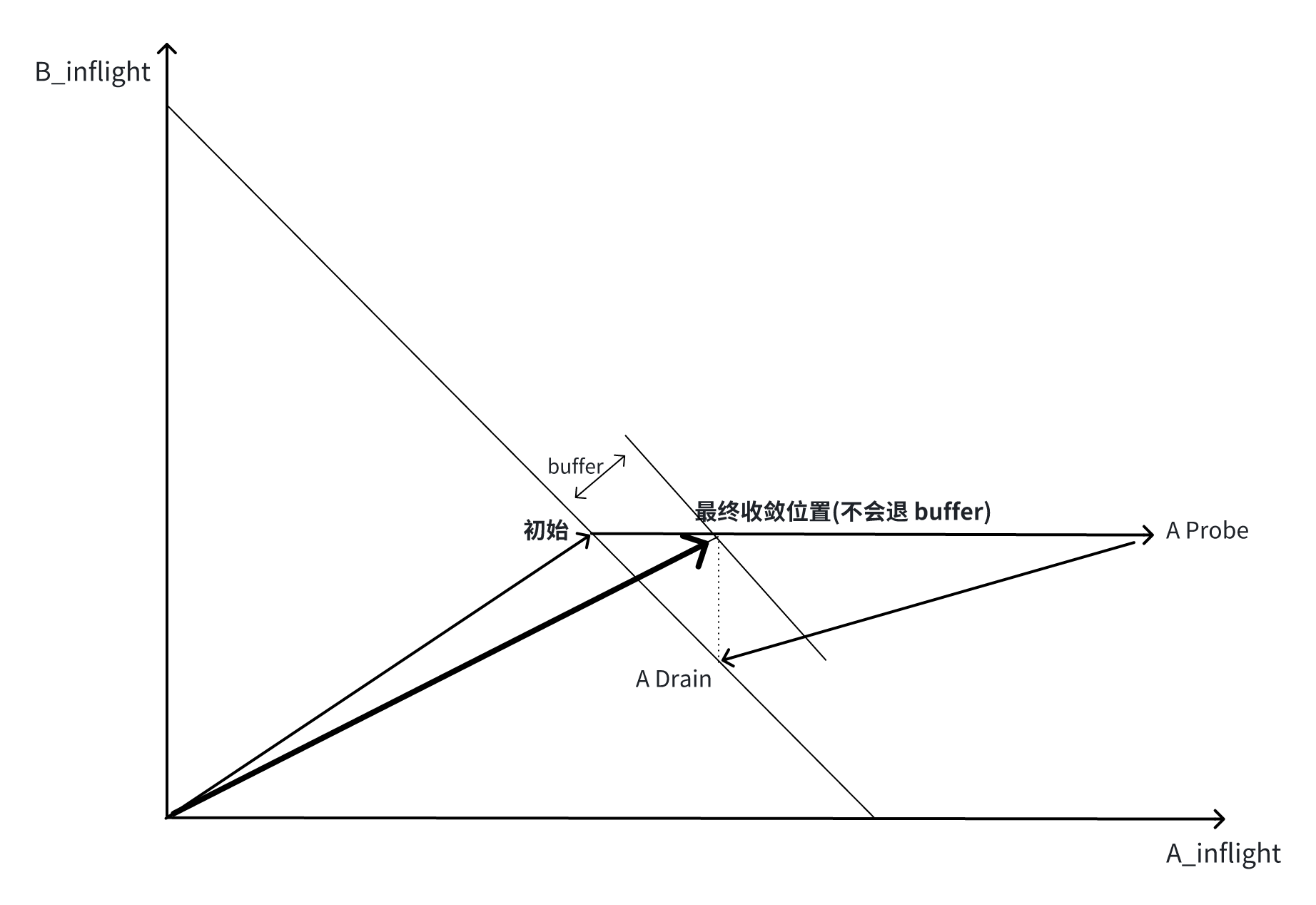
作为常识,公平性必须靠 buffer 动力学驱动,在 buffer 挤兑中获得,遗憾的是,BBR 的 Probe 行为不但没有利用 buffer 制造多流收敛,反而放大了差异,倾向于利好 RTT 偏大的流,这是不公平性的根源。就好像一个胖子一点点把瘦子挤到边边一样,在不断接触中,一次挪一点。
来看看 Why。
此前我分析过,若不是 ProbeRTT 主动清空 buffer 堆积,实践中的 BBR 将占 buffer 越来越多(虽然在理论分析中,BBR 从不堆积 buffer 制造队列),这事实即使不看 draft 和代码,稍微想一下就能明白。这里我再重复讲一次(不啰嗦这些,本文也不剩啥了)。
只要 BBR 多流共存,任意一条当前 pacing rate 为 B1 的流只要 Probe 就一定能获得更大的 buffer 占比,从而一定能挤占出哪怕一丁点带宽 B2,且 B2 > B1 作为新的 maxbw 被 max-filter 记住,它随后的 Drain phase 仅能 drain 掉 inflight 中比 B2 · minrtt 多出来的那部分,剩下的 B2 · minrtt - B1 · minrtt 的部分就留在了 buffer 中。
现在用控制变量法,让其它流不进行 Probe,由于已经完成 Probe 的流挤出了更大的 B2,剩下的流即使保持各自当前 pacing rate,buffer 占用仍会增加,一直到这些流的 maxbw 纷纷过期,buffer 才停止增长。现在释放控制变量,让其自由 Probe,不等式传递原理,这种真实情况下一定比假设的情况占用更多 buffer。如此反复,随着 BBR 流持续,buffer 占用将越来越大。
Probe 停止,maxbw 会过期并跌落,buffer 会停涨,但它不会自动清空,只是维持。类似河流经过已经填满的湖泊,除非枯水不会自动排空湖泊一样。更何况,Probe 不会停止,因此 buffer 会一直涨下去:
若没有 ProbeRTT,buffer 将类似上图指示,从终点不断堆积下去。但在 ProbeRTT 之前,还得先看下 cwnd gain 对 inflight 的约束。
不知是有意还是无意(也许 Google BBR 团队从最开始真的就没意识到这个问题),BBR 增加了 cwnd_gain 作为约束,限制 inflight 最大只能到 2 · BDP,以限制 buffer 的疯涨,但这个限制让 RTT 更小的流的处境更加雪上加霜。
BDP = bw · RTT,先看 bw,BBR 流的 bw 通过 Qp = 1.25 · maxbw · minrtt 的 Probe 量在 buffer 挤占出来, 可见 minrtt 越小,Qp 越小,再看 RTT,由于 buffer 占用持续增长,RTT = RTprop + RTwait 持续增长,管道容量增加,inflight = maxbw · (minrtt + RTwait) > 2 · maxbw · minrtt 更容易首先满足 minrtt 小的流,因此 minrtt 小的流首先被 cwnd 限制。
不光如此,这个 cwnd-limited 问题甚至限制 Probe,越是被压制的流越是被继续压制。由于 minrtt 更小流的 BDP 组分中 RTwait 占比很大,即使它的 Probe 加速比更高,其 bw 增量也不足以弥补 RTwait,maxbw 涨太慢,RTwait 值太大,BDP = maxbw · (minrtt + RTwait) 很快遭遇它的上限 2 · maxbw2 · minrtt。BBR 团队和讨论组早就发现这个问题,BBRv3 进行了修正,Probe 期间的 cwnd_gain 从 2 提升到了 2.25,但并没解决本质问题。
所以,BBR 高度依赖 ProbeRTT,但主动突然排空 buffer 的行为让 BBR 的 ProbeBW 状态被中断,buffer 队列没了,但只是把队列转到了 sender 的发送缓冲区,在端到端的数据生成处看来,数据只是 bufferbloat 在了尚未进入网络协议栈的第 0 跳,ProbeRTT 远没有解决问题,只是转移了问题。
核心问题还是要让算法自动感知 RTT 的升高,无论是 RTwait 的升高还是 minrtt 本来就高,这两种情况下,算法都要倾向于抑制 Probe,无论是缩短 Probe 时间,还是降低 pacing gain。
再一次,第一个想到的还得是靠 sigmoid 做激发函数,不过这次先简单点,直接用两个 sigmoid 来线性叠加,背后的意思是提供两个负反馈:
- 队列越长,即 RTT - minrtt 越大,越倾向于抑制 Probe;
- RTprop 越长,越倾向于抑制 Probe;
- 用 sigmoid 函数去量纲,归一。
操作如下:
S i g m o i d ( x , α , β , γ ) = α 1 + e β ⋅ x + γ \mathrm{Sigmoid}(x,\alpha,\beta,\gamma)=\dfrac{\alpha}{1+e^{\beta\cdot x}}+\gamma Sigmoid(x,α,β,γ)=1+eβ⋅xα+γ
A = B = 1 A=B=1 A=B=1
K = A ⋅ S i g m o i d ( R T T − R T p r o p , α 1 , β 1 , γ 1 ) + B ⋅ S i g m o i d ( R T p r o p , α 2 , β 2 , γ 2 ) K=A\cdot\mathrm{Sigmoid}(\mathrm{RTT-RTprop},\alpha_1,\beta_1,\gamma_1)+B\cdot\mathrm{Sigmoid}(\mathrm{RTprop},\alpha_2,\beta_2,\gamma_2) K=A⋅Sigmoid(RTT−RTprop,α1,β1,γ1)+B⋅Sigmoid(RTprop,α2,β2,γ2)
G a i n = S i g m o i d ( K , α , β , γ ) \mathrm{Gain}=\mathrm{Sigmoid}(K,\alpha,\beta,\gamma) Gain=Sigmoid(K,α,β,γ)
用实际现网数据训练,求出最佳拟合的几个 α,β,γ 就可以了。那句废话 A = B = 1 旨在表明一个点,两个并列的 Sigmoid 函数没必要加权,也许你会觉得 “单纯 RTprop 大” 和 “单纯 RTwait 大” 需要区别对待,其实不必,因为 Sigmoid 有个激发特性,只要 RTprop 和 RTwait 没有一起大,它们和的 Sigmoid 函数就可以很小,只需调整 α2,β2,γ2 让其向右偏,这意味着 RTprop 的作用力比 RTwait 更大,反之向左偏就倾向于 RTwait 的作用力更大。
如果不想实现复杂函数(特别是内核中),可分析现网数据后直接用 python 生成一张算好的表,将其粘贴在代码里,代码里查表大概就跟我一个函数几千个 if 分支差不多的意思了。
为了能抵抗并容忍 minrtt 噪声,前几天刚发明一个 minrtt 采集算法,参考 BBR minrtt 的采集,两个算法叠加,让人不明觉厉,可以水一篇论文了。
但且慢,这些启发式把戏难道不是我一直嗤之以鼻的吗,我一再强调 RTT 的不准确性,算不准就别算,所以除却这些可能适合论文或蒙骗经理的把戏,还有一个更加实用的方法。
参考 L4S & TCP Prague,TCP Prague 的 draft 提到一种 极简主义算法 来去除 RTT 相关性,从而解决 AIMD 场景的 RTT 不公平性。模仿该思想,一个正确实用的算法就来了:
P r o b e Q u o t a = M a x B W ⋅ R T p r o p + 0.25 ⋅ min ( R T p r o p , δ ) \mathrm{ProbeQuota}=\mathrm{MaxBW}\cdot \mathrm{RTprop}+0.25\cdot\min(\mathrm{RTprop},\delta) ProbeQuota=MaxBW⋅RTprop+0.25⋅min(RTprop,δ)
其中 δ 为一个经验的,统计意义上的 RTprop 中位数或其它的典型值,在不同网络中有不同的典型值。
修改下面的函数即可:
static void bbr_update_cycle_phase(struct sock *sk,
const struct rate_sample *rs,
struct bbr_context *ctx)
{
...
case BBR_BW_PROBE_UP:
总之,BBR 的公平性之路还有很长的路要走,不仅仅是 BBR 内部的公平性,还有与 cubic 等 AIMD 算法共存时的外部公平性。
外部公平性,这很大程度上是因为存量 TCP 多数使用久经考验和论证的 cubic 等 AIMD 算法,想当年 Reno AIMD 算法上线时,它是一个从零到一的过程,并不需要考虑外部公平性,而内部公平性非常好论证,随后的 bic,cubic 也只是简单迭代,可一旦涉及完全不同的机制,比如 Vegas,考虑到部署后的公平性,基本就是胎死腹中。看,BBR 为了外部公平性,又回到了老路,哪怕只是为了兼容,可能它必须兼容。
浙江温州皮鞋湿,下雨进水不会胖。

















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









