







文章列表
1.深度学习基础模型算法原理及编程实现–01.感知机.
2.深度学习基础模型算法原理及编程实现–02.线性单元 .
3.深度学习基础模型算法原理及编程实现–03.全链接 .
4.深度学习基础模型算法原理及编程实现–04.改进神经网络的方法 .
5.深度学习基础模型算法原理及编程实现–05.卷积神经网络.
6.深度学习基础模型算法原理及编程实现–06.循环神经网络.
9.深度学习基础模型算法原理及编程实现–09.自编码网络.
…
深度学习基础模型算法原理及编程实现–03.全链接
神经网络是由MP神经元(如下图所示)构成,MP神经元是一种多输入单输出的信息处理单元,其实前面讲到的感知机以及线性单元都是MP神经元的一种特例,只是激活函数不同,常见的激活函数有sigmoid、tanh、ReLU、softplus等,后面用到的时候会慢慢介绍各自的特点及差异。
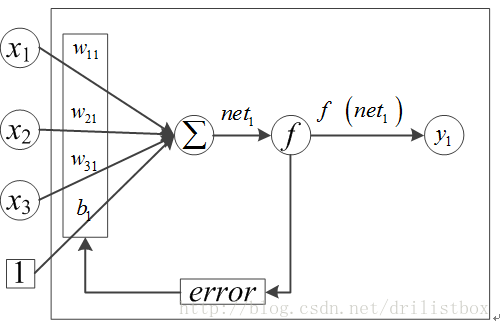
图 1 MP神经元模型
将神经元按一定的规则排列可以形成神经网络,首先介绍最基本的全连接神经网络。全链接神经网络可以处理多类分类问题和回归问题,其拓扑结构为单/多隐层、全连接且有向无环,依据拓扑结构及神经元的数学模型构建输入信息与输出标签的映射关系,以标签向量与输出向量差的均方误差(或MSE)为损失函数,通过梯度下降寻找映射关系中各参数信息。
将MP神经元看成一个节点,自然会想到类似于生命体身上的神经链络,近乎于随意连接。但在实际应用中,出于简化问题及高效计算的考虑,主流神经网络模型都是以层为基本单位的,将多个神经元节点并行排列,且同一层中各个节点之间没有连接,我们将这样的组合方式称为“层”。按功能差异,层可细分为“输入层”、“中间层(或隐藏层)”及“输出层”,下图展示了只有一个隐藏层的神经网络模型示意图,它是由多个MP神经网络排列而成,其拓扑结构为:单隐层、全连接且有向无环,也可称其为单隐层前馈神经网络。其中xi(i=1,2,3)为输入层训练数据中i第个标记的值,由于中间层及输出层的结构形式一致(均为数个神经元按列排列而成),且输入层为直接读入的样本数据,所以下面在讨论到第几层中的层仅指中间层及输出层。Hornik等人已经证明:若输出层采用线性激活函数,隐层采用sigmoid函数,则单隐层神经网络能够以任意进度逼近任何有理函数。
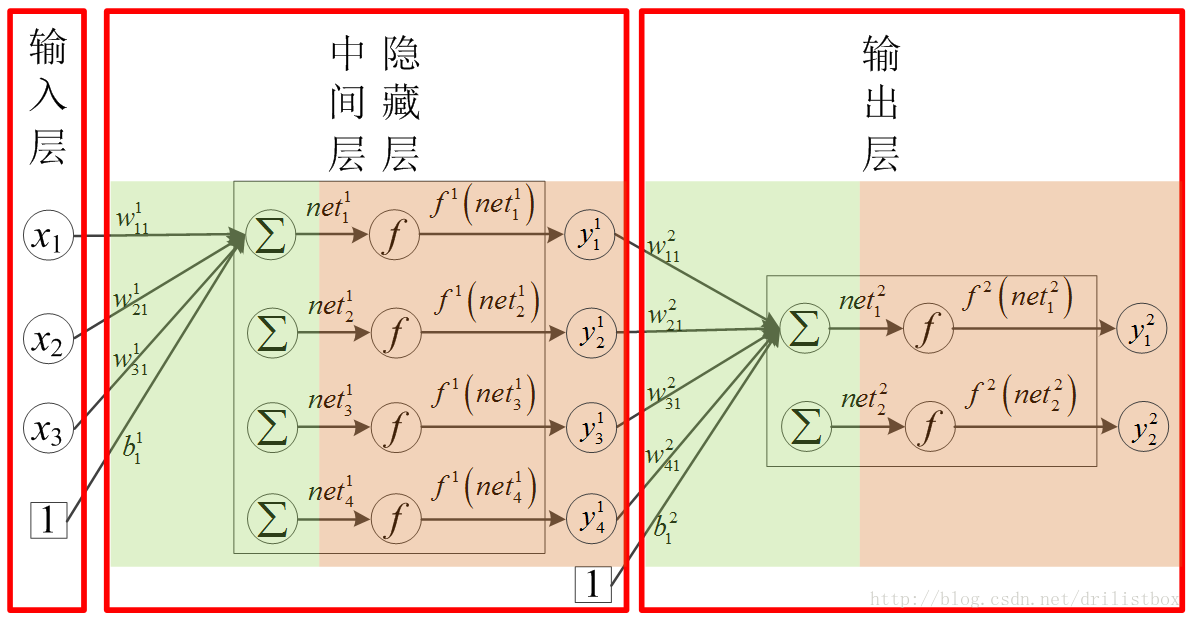
图 2 单隐层全链接神经网络示意
全链接神经网络出现之前,图像分类算法依赖于复杂的特征工程。常用的特征提取方法包括SIFT(尺度不变特征转换)、HOG(方向梯度直方图)、LBP(局部二值模式)等,常用的分类算法为SVM。虽然全连接在MNIST数据识别上效果不错,但由于全链接神经网络中参数太多,并且有层数限制,没有考虑图像局部的相关性等,一般不适合用来识别图像,也许以后在硬件或算法上有新的突破。
1.1 全连接神经网络的训练
设
Nk
N
k
为第
k
k
层中神经元的个数;为第
k
k
层中第个节点的加权输入值,维数为
1∗Nk
1
∗
N
k
;
wkij
w
i
j
k
为第
k−1
k
−
1
层中第
i
i
个节点到第层第
j
j
个节点的加权系数输入值,维数为(我个人觉得这样更顺眼,因为由前往后,与前馈神经网络前向传输顺序一致);
fk
f
k
为第k层中的激活函数;
bkj
b
j
k
为第k层中的偏置项到第k层第j个节点的偏置系数,维数为
1∗Nk
1
∗
N
k
;
ykj
y
j
k
为第
k
k
层中第个节点的训练输出值,维数为
1∗Nk
1
∗
N
k
则对第
k
k
层有:

将其矢量化,有
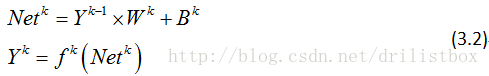
至此前向传导算法介绍完毕,式(3.2)给出其运算表达式。
权重矩阵及偏置项的理解:为了方便理解,假定激活函数都是线性函数(非线性函数可以理解成特征空间的扭变),对于分类问题而言,权重矩阵Wk中的每一列都是一个二分类分类器的系数,而偏差Bk中的每个元素表示分类器曲面相对于原点沿高维法向上的平移。如果偏差为0的话,那么所有分类器的曲面都将过高维空间中的同一点,这显然是不合理的。此外,经过激活函数处理后,设实例点到分类曲面的距离为L,输出的大小是分类准确度以及L的联合表征,所以在多分类问题的中,我们会通过比较输出层的大小来判定类别,因为输出值越大,表示该类有最好的准确度,并且L也最大。
也可将分类过程看做模板匹配:权重矩阵Wk中的每一列都是一个分类模板。通过使用内积(也叫点积)来计算图像与模板的相似度,然后找到相似度最高模板最相似;从另一个角度来看,可以认为还是在高效地使用k-NN(因为没有使用所有的训练图像来比较),每个类别只用了一张图片(Wk中的对应的一列reshape为图像的维度,这张图片是模型通过学习得到图像内在数据结构,不是训练集中的某一张,k-NN算法本身并没有学习到任何的数据内在结构信息)。
3.1.2 梯度计算
按照机器学习的通用套路,先确定损失函数,然后用(随机)梯度下降算法迭代寻优获取获取最佳的权重系数以及偏置系数,即损失函数最小时的参数值。不失一般性,取神经网络输出值方差的一半作为损失函数,即以标签向量与输出向量差的二范数平方和的一半做为损失函数,即有:
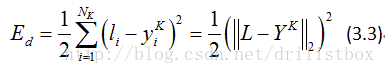
其中为训练标签向量,
Yk
Y
k
为输出层的输出向量
梯度下降法的关键就是求取每个参数的偏导数,可以利用链式求导计算损失函数对每个权重及偏置项的偏导数(即梯度),通过设置学习速率,利用梯度下降公式更新权重系数及偏置系数,具体实现流程如下:
3.1.2.1 偏导数计算
3.1.2.1.1 对权重系数的偏导数

式中
δkj
δ
j
k
称为误差项。误差项计算较为复杂,后面会在1.2.3小节中详细介绍。将上式整理成向量形式:

3.1.2.1.2 对偏置量的偏导数

整理成向量形式:

3.1.2.1.3 误差项
3.1.2.1.3.1输出层误差项
对于输出层,有k=K,且由下图不难发现,输出层的每个加权输入节点处的误差仅由对应节点的输出决定:
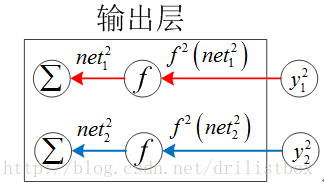
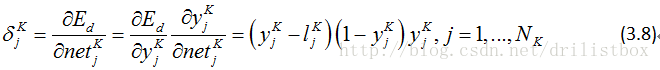
整理成向量形式:
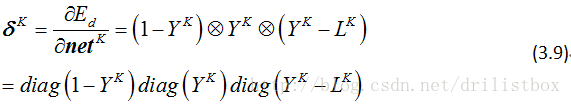
上式给出了损失函数为二次型误差项且输出层激活函数为sigmoid的情况,如果将误差项采用交叉项:

如果将激活函数改为softmax且误差项不变,这样的组合称为softmax-loss,那么输出层的误差项为:

可见对分类问题,对任意激活函数,采用交叉熵损失函数只要算一个神经元节点的偏导数即可,计算量减小;如果将激活函数再改为softmax函数,那么误差项只要一个相减操作,计算量更小。
3.1.2.1.3.2隐藏层误差项
对于隐藏层,有1≤k≤K-1,且由下图的拓扑结构不难发现,中间层的每个加权输入对下一层的所有节点都会产生影响,因此在求偏微分时,有:
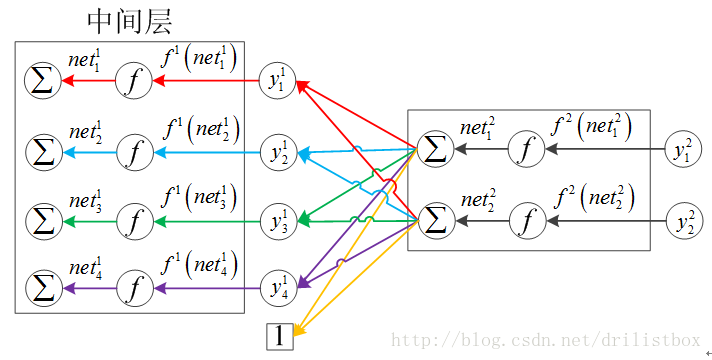
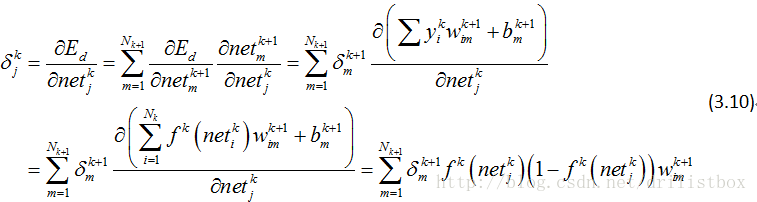
整理成向量形式:
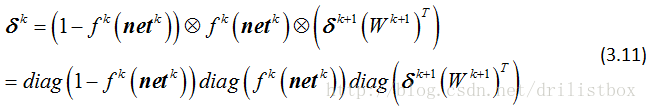
上式给出了隐藏层激活函数为sigmoid的情况,如果将激活函数改为softmax,那么输出层的误差项为:

可见,隐藏层用softmax做激活函数在计算上并没有太大的优势,但在输出层中,如果激活函数用softmax并配合交叉熵损失函数来使用,那么计算量会非常小。
3.1.3 系数更新:
梯度下降法,学习速率为
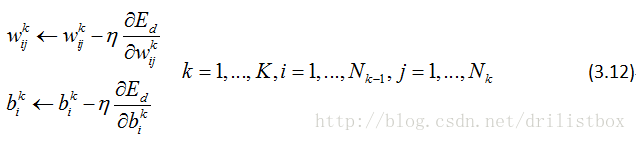
整理成向量形式:
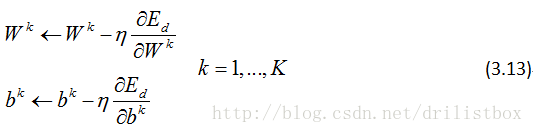
1.1.4小结
上面只是最简单的全连接神经网络,下一节会讲述改进神经网络的方法。
1.2 编程实现
现在尝试利用上面的全连接神经网络模型来识别手写数字,采用MNIST数据集来检测算法性能,MNIST数据集有60000个手写字母的训练样本,我们使用它训练我们的神经网络,然后再用训练好的模型去对MNIST数据集中的10000个测试样本进行测试。编程实现的全连接神经网络只有一个隐藏层,输入为1*784的向量数据(经28*28的图片转换而成),向量中的每个元素表示图像中对应像素的灰度值,输出为长度为10的向量,向量中最大的值所在位置及表示识别的数字,中间层神经元节点数目选为100。有几个经验公式可供参考:

单隐层前馈全连接神经网络实现起来较为简单,我已经将实现好的程序放在网上,只要有一定的C++及python语法基础都可以看懂程序,由于个人也是刚刚系统的接触深度学习,感觉程序跑的有点慢,有不对的地方还希望广大同学告诉我,希望大家多多指导。
python版本:https://pan.baidu.com/s/1qZLJ7Gg
C++版本:https://pan.baidu.com/s/1qZLJ7Gg
C++版本运算特别慢,应该是权重矩阵太大了,计算比较耗时,主要还是我自己编的不行;下篇卷积神经网络中矩阵比较小,计算速度会快很多。这里给出了python版本的测试数据准确率:94.6%
















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









