






多核查找-顺序查找也疯狂
在去年的软件开发2.0技术大会上,我讲了一个支持动态负载均衡的多核查找设计方法。基本思想是采用数据结构分拆的方法,使用了多级的数据结构设计。下面先简要介绍一下这种多级数据结构的设计思路,然后给出一个采用数组顺序查找作为查找表实现的多级数据结构类CDHashArray。
在CDHashArray中,对数组的插入和删除都是顺序化的操作,查找也是近似于顺序化的操作,看起来似乎会很慢。实际上对于小数组,比如只有几个或十来个数组,其效率并不慢,这使得以前在单核时代无法用于大型查找的数组顺序查找,在多核时代却可以得到很好应用前景。
二级查找结构基本思想
要了解多级数据结构设计,首先得知道基本的二级查找数据结构设计思想。
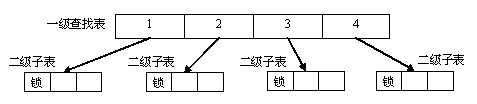
二级查找结构就是在第1级查找时找到二级子表的位置,然后在找到的二级子表中进行第二次查找来找到对应的目标数据。
典型的二级查找结构示意图如下:
|
1 |
|
2 |
|
3 |
|
4 |
|
锁 |
|
一级查找表 |
|
二级子表 |
|
二级子表 |
|
二级子表 |
|
|
|
|
|
锁 |
|
|
|
|
|
锁 |
|
|
|
|
|
锁 |
|
|
|
|
|
二级子表 |
图16.2.1: 二级查找结构示意图
二级查找结构由一级查找表和二级子表构成,一个查找表中的每个节点指向一个二级查找子表。查找时,先将关键词映射成一级查找表的位置,然后将对应位置的二级子表取出,在子表中找到对应的查找目标数据。
Intel Threading Building Blocks(TBB)开源项目中,其中的concurrent_hash_map使用的就是一种最简单的二级查找结构。它使用了哈希表式的数据结构,并给哈希表的每个桶设一把锁。
对于普通的查找,这种简单的二级查找结构也许够用了,但是对于一些大型的查找,这种简单的二级查找结构并不能满足。首先的问题是如果子表数量过多,则锁的数量也非常多,锁本身需要占用大量的内存开销。
如果子表数量过少,那么又会引起另外一个重要的问题,那就是负载平衡问题。因为这种情况中有可能各个二级子表中的数据数量相差非常大,这将导致某些子表的访问量很少,而某些子表的访问量很大。这些访问量大的表很容易发生多个线程同时访问的情况,从而导致集中式锁竞争情况的发生。
为了解决二级查找结构中的不足,下面来看看多级查找结构的设计思想。
多级查找结构设计思想
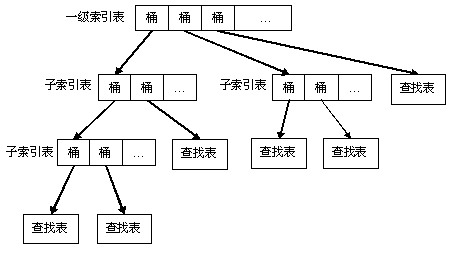
多级查找结构是在二级查找结构的基础上设计的,当某个子表中数据个数过多时,可以将其拆分成两个或更多个子表,同时新建一个索引表来指向这几个拆分候的子表,指向原来子表的指针指向新建的索引表。
如果拆分后的子表内插入的数据过多时,可以继续将其分拆,这样一直分拆下去,将形成一个多级的查找数据结构,下图就是一个多级查找结构示意图。
|
桶 |
|
桶 |
|
… |
|
查找表
|
|
一级索引表 |
|
子索引表 |
|
桶 |
|
桶 |
|
桶 |
|
… |
|
桶 |
|
桶 |
|
… |
|
桶 |
|
桶 |
|
… |
|
查找表
|
|
查找表
|
|
查找表
|
|
查找表
|
|
查找表
|
|
子索引表 |
|
子索引表 |
在多级查找结构中进行操作时,所有索引表的操作都是不用锁的,只有访问查找表时才用锁,这使得它的查找效率并不会比二级查找结构降低。并且由于它是负载均衡的,每个查找子表的数量都是小于设定值的,这样每个查找表中查找的时间都是有保证的。而二级查找结构中并不能给出这种保证,比如链式的哈希表,如果哈希函数设计不好,某个桶中的元素个数过多,在这个桶中的查找将变慢。
在这种多级查找结构的设计中,查找表必须是可以分拆的,一般来说,比较易于分拆的查找数据结构有AVL树、数组等。
下面以数组为例来实现一个多级查找结构。由于基本算法思想在去年的软件开发大会上讲过,这里就不再详述了。如果没有听过讲座的也可以从下面的代码中去体会算法的基本思想。
使用数组作为查找表,可能很多人会认为速度很慢,因为数组的插入和删除速度看起来似乎很慢。但是实际上,如果数组设置得很小,比如只有几个或十几个数据,那么其插入和删除的速度并不慢,另外使用数组还有一个好处是容易进行CACHE行对齐,以避免伪共享问题(即多个线程操作的不同数据却位于同一Cache行的问题)。
对于这种小数组的查找,并不需要用到二分查找,可以采用近似于顺序查找的方法来进行查找,其查找效率也非常高效。
CDHashArray源代码
下面是使用数组作查找表的多级查找结构CDHashArray类的源代码。为方便起见,代码中对数据的比较等没有使用回调函数或仿函数,直接使用大于、等于或小于号进行比较。
template <class T>
struct INDEXNODE {
FASTLOCK lock;
T Key;
LONG volatile lType; //FIND_TABLE or INDEX_TABLE;
void *pSubTable; //sub table pointer,if lType is
// DARRAYSEARCH_FIND_TABLE, pSubTable is a Search Array,
// if lType is DARRAYSEARCH_INDEX_TABLE,
// then pSubTable pointer to a INDEXNODE array .
};
template <class T, class SearchArray>
class CDHashArray {
PRIVATE:
INDEXNODE<T> * m_pIndexNode;
int m_nBucketCount;
int m_nSplitCount;
HASHFUNC m_HashFunc;
void SubTableInsert(INDEXNODE<T> *pNode, T &Data);
void SubTableDelete(INDEXNODE<T> *pNode, T &Data);
void SubTableFind(INDEXNODE<T> *pNode, T &Data, T &OutData);
public:
CDHashArray(int nBucketCount, HASHFUNC HashFunc);
virtual ~CDHashArray();
void Insert(T &Data);
void Delete(T &Data);
void Find(T &Data, T &OutData);
};
/** 子表插入函数
@param INDEXNODE<T> *pNode - 要查找的索引节点
@param T &Data - 要查找的数据
@return void - 无
*/
template <class T, class SearchArray>
void CDHashArray<T, SearchArray>::SubTableInsert(
INDEXNODE<T> *pNode, T &Data)
{
FastLockAcquire(&(pNode->lock));
LONG lType = pNode->lType;
if ( lType == CDHASHARRAY_FIND_TABLE )
{
//将子表地址转换成一个索引表指针;
SearchArray *pArray = (SearchArray *)pNode->pSubTable;
pArray->Insert(Data);
if ( pArray->m_nCount == pArray->m_nSize )
{
CIndexTable<T, SearchArray> *pTable = new CIndexTable<T, SearchArray>;
pTable-> Split (pArray);
pNode->pSubTable = pTable;
//查找表的子表类型= 索引表(原子操作);
AtomicIncrement(&(pNode->lType));
}
}
else
{
//将查找表指针转换为索引表指针;
CIndexTable<T, SearchArray> *pTable
= (CIndexTable<T, SearchArray> *)pNode->pSubTable;
//在索引表中找到对应的子表;
INDEXNODE<T> *pTempNode = pTable->UpperBound(Data);
//由于在获取锁前,其他线程将表的类型又查找表改为了索引表
//这种情况下有可能有很多其他线程访问这个索引表时是不需要使用锁的
//因此这里需要递归调用,防止找到的查找子表又发生大量插入而变为索引表
//这样会发生多级加锁解锁操作,不过发生这种情况的概率是非常低的
SubTableInsert(pTempNode, Data);
}
FastLockRelease(&(pNode->lock));
return ;
}
/** 分布式搜索数组的插入数据函数
@param T &Data - 要插入的数据
@return void - 无
*/
template <class T, class SearchArray>
void CDHashArray<T, SearchArray>::Insert(T &Data)
{
int nPos = (*m_HashFunc)((void *)Data, m_nBucketCount);
INDEXNODE<T> *pNode = &(m_pIndexNode[nPos]);
LONG lType = pNode->lType;
while ( lType == CDHASHARRAY_INDEX_TABLE )
{
//将子表地址转换成一个索引表指针;
CIndexTable<T, SearchArray> *pIndexTable
= (CIndexTable<T, SearchArray> *)pNode->pSubTable;
//最终子表=在索引表中进行二分查找到对应的索引节点;
pNode = pIndexTable->UpperBound(Data);
//子表类型=索引节点的子表类型;
lType = pNode->lType;
}
SubTableInsert(pNode, Data);
return;
}
/** 分布式搜索数组的子表查找数据函数
@param INDEXNODE<T> *pNode - 要删除数据的索引节点
@param T &Data - 要查找的数据
@param T &OutData - 存放找到的数据
@return void - 无
*/
template <class T, class SearchArray>
void CDHashArray<T, SearchArray>::SubTableFind(
INDEXNODE<T> *pNode, T &Data, T &OutData)
{
FastLockAcquire(&(pNode->lock));
if (pNode->lType == CDHASHARRAY_FIND_TABLE)
{
SearchArray *pArray = (SearchArray *)pNode->pSubTable;
//在查找表中查找包含Data的节点;
pArray->Find(Data, OutData);
}
else
{
//将查找表指针转换为索引表指针;
CIndexTable<T, SearchArray> *pTable
= (CIndexTable<T, SearchArray> *)pNode->pSubTable;
//在索引表中进行二分查找到对应的子表;
pNode = pTable->UpperBound(Data);
//由于在获取锁前,其他线程将表的类型又查找表改为了索引表
//这种情况下有可能有很多其他线程访问这个索引表时是不需要使用锁的
//因此递归调用,防止找到的查找子表又发生大量插入而变为索引表
//不过这样会发生多级加锁解锁操作,不过发生这种情况的概率是非常低的
SubTableFind(pNode, Data, OutData);
}
FastLockRelease(&(pNode->lock));
return;
}
/** 分布式搜索数组的查找数据函数
@param T &Data - 要查找的数据
@param T &OutData - 存放找到的数据
@return void - 无
*/
template <class T, class SearchArray>
void CDHashArray<T, SearchArray>::Find(T &Data, T &OutData)
{
int nPos = (*m_HashFunc)((void *)Data, m_nBucketCount);
INDEXNODE<T> *pNode = &(m_pIndexNode[nPos]);
LONG lType = pNode->lType;
while ( lType == CDHASHARRAY_INDEX_TABLE )
{
//将子表地址转换成一个索引表指针;
CIndexTable<T, SearchArray> *pIndexTable
= (CIndexTable<T, SearchArray> *)pNode->pSubTable;
//最终子表=在索引表中进行二分查找到对应的索引节点;
pNode = pIndexTable->UpperBound(Data);
//子表类型=索引节点的子表类型;
lType = pNode->lType;
}
SubTableFind(pNode, Data, OutData);
return;
}
索引表CIndexTable的代码
#define MAX_NODE_COUNT_FOR_SPLIT 128
#define CINDEXTABLE_NODE_COUNT 2
template <class T, class SearchArray>
class CIndexTable {
public:
INDEXNODE<T> m_Node[CINDEXTABLE_NODE_COUNT]; //index node array
~CIndexTable()
{
if ( m_Node[0].lType == CDHASHARRAY_FIND_TABLE )
{
SearchArray *p = (SearchArray *)m_Node[0].pSubTable;
delete p;
FastLockClose(&(m_Node[0].lock));
}
else
{
CIndexTable<T, SearchArray> *pTable
= (CIndexTable<T, SearchArray> *)m_Node[0].pSubTable;
pTable->~CIndexTable();
}
if ( m_Node[1].lType == CDHASHARRAY_FIND_TABLE )
{
SearchArray *p = (SearchArray *)m_Node[1].pSubTable;
delete p;
FastLockClose(&(m_Node[1].lock));
}
else
{
CIndexTable<T, SearchArray> *pTable
= (CIndexTable<T, SearchArray> *)m_Node[1].pSubTable;
pTable->~CIndexTable();
}
}
INDEXNODE<T> *UpperBound( T &Data)
{
if ( Data <= m_Node[0].Key )
{
return &(m_Node[0]);
}
else
{
return &(m_Node[1]);
}
}
void Split (SearchArray *pArray)
{
SearchArray *pNewArray = pArray-> Split ();
T Key;
pArray->GetMax(Key);
m_Node[0].Key = Key;
FastLockInit(&(m_Node[0].lock));
FastLockInit(&(m_Node[1].lock));
m_Node[0].pSubTable = pArray;
m_Node[1].pSubTable = pNewArray;
m_Node[0].lType = CDHASHARRAY_FIND_TABLE;
m_Node[1].lType = CDHASHARRAY_FIND_TABLE;
return ;
}
};
CSearchArray类的代码
#define DEFAULT_SEARCH_ARRAY_SIZE 14 //对于32位整数,CSearchArray刚好
//Cache行对齐
template <class T>
class CSearchArray {
PRIVATE:
T * m_pData;
int m_nCount;
int m_nSize;
public:
CSearchArray(int nSize);
virtual ~CSearchArray();
void Insert(T &Data);
void Delete(T &Data);
void Find(T &Data, T &OutData);
void GetMax(T &Data);
CSearchArray<T> * Split ();
};
template <class T>
CSearchArray<T>::CSearchArray(int nSize)
{
m_pData = new T[nSize];
m_nCount = 0;
m_nSize = nSize;
}
template <class T>
CSearchArray<T>::~CSearchArray()
{
delete [] m_pData;
}
template <class T>
void CSearchArray<T>::Find(T &Data, T &OutData)
{
int i;
int nMid = m_nCount >> 1; //除以2
if ( m_pData[nMid] > Data )
{
for ( i = 0; i < nMid; i++ )
{
if ( m_pData[i] == Data )
{
OutData = m_pData[i];
break;
}
}
}
else
{
for ( i = nMid; i < m_nCount; i++ )
{
if ( m_pData[i] == Data )
{
OutData = m_pData[i];
break;
}
}
}
}
template <class T>
void CSearchArray<T>::Insert(T &Data)
{
int i, j;
for ( i = 0; i < m_nCount; i++ )
{
if ( Data <= m_pData[i] )
{
break;
}
}
for ( j = m_nCount; j > i; j-- )
{
m_pData[j] = m_pData[j-1];
}
m_pData[i] = Data;
m_nCount += 1;
}
template <class T>
void CSearchArray<T>::Delete(T &Data)
{
int i,j;
for ( i = 0; i < m_nCount; i++ )
{
if ( m_pData[i] == Data )
{
break;
}
}
for ( j = i; j < m_nCount - 1; j++)
{
m_pData[j] = m_pData[j+1];
}
m_nCount -= 1;
}
template <class T>
void CSearchArray<T>::GetMax(T &Data)
{
Data = m_pData[m_nCount-1];
}
/** 将一个SearchArray类劈成两个CSearchArray类
劈开后的两个类,一个为自身,另外一个通过返回值返回
@return CSearchArray<T> * - 返回一个被劈开的新的CSearchArray类指针
*/
template <class T>
CSearchArray<T> * CSearchArray<T>:: Split ()
{
CSearchArray<T> *pArray
= new CSearchArray<T>(DEFAULT_SEARCH_ARRAY_SIZE);
int nCount = m_nCount >> 1; //除以2
int i;
for ( i = nCount; i< m_nCount; i++ )
{
pArray->Insert(m_pData[i]);
}
m_nCount -= nCount;
return pArray;
}















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









