






4. 结合图解Spark书进行应用与优化
《图解Spark:核心技术与案例实战》一书以Spark2.0版本为基础进行编写,系统介绍了Spark核心及其生态圈组件技术。其内容包括Spark生态圈、实战环境搭建和编程模型等,重点介绍了作业调度、容错执行、监控管理、存储管理以及运行架构,同时还介绍了Spark生态圈相关组件,包括了Spark SQL的即席查询、Spark Streaming的实时流处理、MLlib的机器学习、GraphX的图处理和Alluxio的分布式内存文件系统等。下面介绍京东预测系统如何进行资源调度,并描述如何使用Spark存储相关知识进行系统优化。
4.1 结合系统中的应用
在图解Spark书的第六章描述了Spark运行架构,介绍了Spark集群资源调度一般分为粗粒度调度和细粒度调度两种模式。粗粒度包括了独立运行模式和Mesos粗粒度运行模式,在这种情况下以整个机器作为分配单元执行作业,该模式优点是由于资源长期持有减少了资源调度的时间开销,缺点是该模式中无法感知资源使用的变化,易造成系统资源的闲置,从而造成了资源浪费。而细粒度包括了Yarn运行模式和Mesos细粒度运行模式,该模式的优点是系统资源能够得到充分利用,缺点是该模式中每个任务都需要从管理器获取资源,调度延迟较大、开销较大。
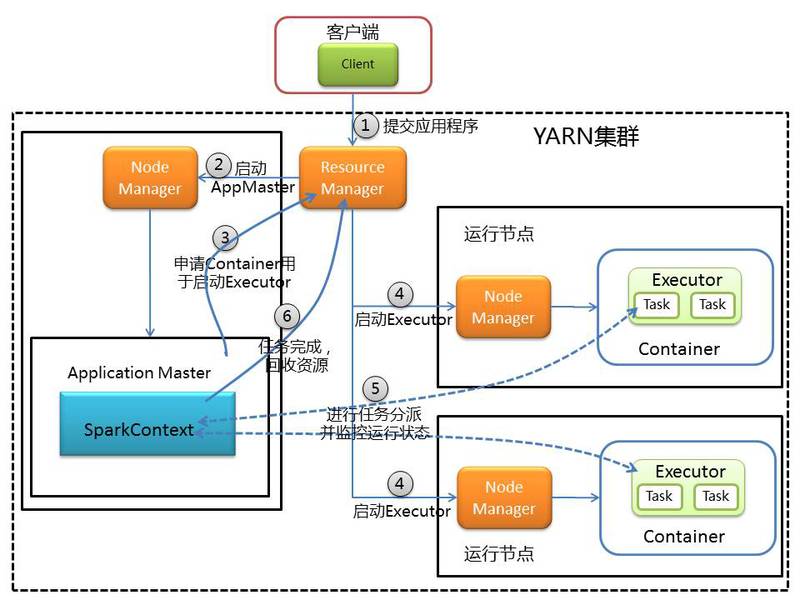
由于京东Spark集群属于基础平台,在公司内部共享这些资源,所以集群采用的是Yarn运行模式,在这种模式下可以根据不同系统所需要的资源进行灵活的管理。在YARN-Cluster模式中,当用户向YARN集群中提交一个应用程序后,YARN集群将分两个阶段运行该应用程序:第一个阶段是把Spark的SparkContext作为Application Master在YARN集群中先启动;第二个阶段是由Application Master创建应用程序,然后为它向Resource Manager申请资源,并启动Executor来运行任务集,同时监控它的整个运行过程,直到运行完成。下图为Yarn-Cluster运行模式执行过程:
4.2 结合系统的优化
我们都知道大数据处理的瓶颈在IO。我们借助Spark可以把迭代过程中的数据放在内存中,相比MapReduce写到磁盘速度提高近两个数量级;另外对于数据处理过程尽可能避免Shuffle,如果不能避免则Shuffle前尽可能过滤数据,减少Shuffle数据量;最后,就是使用高效的序列化和压缩算法。在京东预测系统主要就是围绕这些环节展开优化,相关Spark存储原理知识可以参见图解Spark书第五章的详细描述。
由于资源限制,分配给预测系统的Spark集群规模并不是很大,在有限的资源下运行Spark应用程序确实是一个考验,因为在这种情况下经常会出现诸如程序计算时间太长、找不到Executor等错误。我们通过调整参数、修改设计和修改程序逻辑三个方面进行优化:
4.2.1 参数调整
- 减少num-executors,调大executor-memory,这样的目的是希望Executor有足够的内存可以使用。
- 查看日志发现没有足够的空间存储广播变量,分析是由于Cache到内存里的数据太多耗尽了内存,于是我们将Cache的级别适当调成MEMORY_ONLY_SER和DISK_ONLY。
- 针对某些任务关闭了推测机制,因为有些任务会出现暂时无法解决的数据倾斜问题,并非节点出现问题。
- 调整内存分配,对于一个Shuffle很多的任务,我们就把Cache的内存分配比例调低,同时调高Shuffle的内存比例。
4.2.2 修改设计
参数的调整虽然容易做,但往往效果不好,这时候需要考虑从设计的角度去优化:
- 原先在训练数据之前会先读取历史的几个月甚至几年的数据,对这些数据进行合并、转换等一系列复杂的处理,最终生成特征数据。由于数据量庞大,任务有时会报错。经过调整后当天只处理当天数据,并将结果保存到当日分区下,训练时按天数需要读取多个分区的数据做union操作即可。
- 将“模型训练”从每天执行调整到每周执行,将“模型参数选取”从每周执行调整到每月执行。因为这两个任务都十分消耗资源,并且属于不需要频繁运行,这么做虽然准确度会略微降低,但都在可接受范围内。
- 通过拆分任务也可以很好的解决资源不够用的问题。可以横向拆分,比如原先是将100个品类数据放在一个任务中进行训练,调整后改成每10个品类提交一次Spark作业进行训练。这样虽然整体执行时间变长,但是避免了程序异常退出,保证任务可以执行成功。除了横向还可以纵向拆分,即将一个包含10个Stage的Spark任务拆分成两个任务,每个任务包含5个Stage,中间数据保存到HDFS中。
4.2.3 修改程序逻辑
为了进一步提高程序的运行效率,通过修改程序的逻辑来提高性能,主要是在如下方面进行了改进:避免过多的Shuffle、减少Shuffle时需要传输的数据和处理数据倾斜问题等。
1. 避免过多的Shuffle
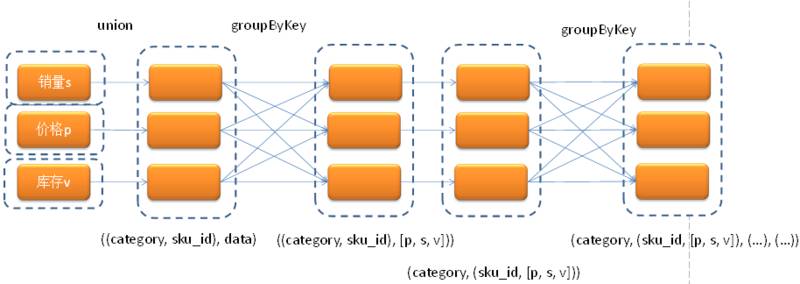
Spark提供了丰富的转换操作,可以使我们完成各类复杂的数据处理工作,但是也正因为如此我们在写Spark程序的时候可能会遇到一个陷阱,那就是为了使代码变的简洁过分依赖RDD的转换操作,使本来仅需一次Shuffle的过程变为了执行多次。我们就曾经犯过这样一个错误,本来可以通过一次groupByKey完成的操作却使用了两回。业务逻辑是这样的:我们有三张表分别是销量(s)、价格(p)、库存(v),每张表有3个字段:商品id(sku_id)、品类id(category)和历史时序数据(data),现在需要按sku_id将s、p、v数据合并,然后再按category再合并一次,最终的数据格式是:[category,[[sku_id, s , p, v], [sku_id, s , p, v], […],[…]]]。一开始我们先按照sku_id + category作为key进行一次groupByKey,将数据格式转换成[sku_id, category , [s,p, v]],然后按category作为key再groupByKey一次。后来我们修改为按照category作为key只进行一次groupByKey,因为一个sku_id只会属于一个category,所以后续的map转换里面只需要写一些代码将相同sku_id的s、p、v数据group到一起就可以了。两次groupByKey的情况:
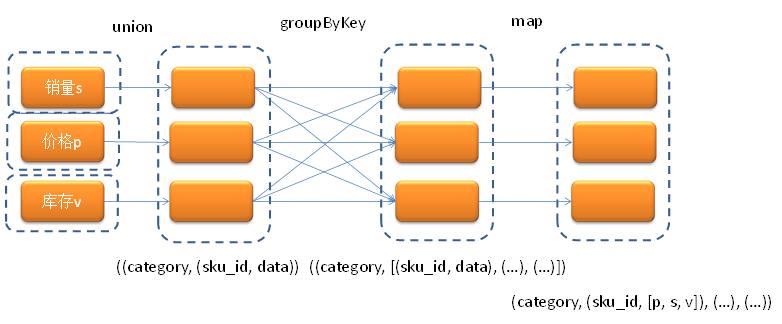
修改后变为一次groupByKey的情况:
多表join时,如果key值相同,则可以使用union+groupByKey+flatMapValues形式进行。比如:需要将销量、库存、价格、促销计划和商品信息通过商品编码连接到一起,一开始使用的是join转换操作,将几个RDD彼此join在一起。后来发现这样做运行速度非常慢,于是换成union+groypByKey+flatMapValue形式,这样做只需进行一次Shuffle,这样修改后运行速度比以前快多了。实例代码如下:

如果两个RDD需要在groupByKey后进行join操作,可以使用cogroup转换操作代替。比如, 将历史销量数据按品类进行合并,然后再与模型文件进行join操作,流程如下:

使用cogroup后,经过一次Shuffle就可完成了两步操作,性能大幅提升。
2. 减少Shuffle时传输的数据量
在Shuffle操作前尽量将不需要的数据过滤掉。
使用comebineyeByKey可以高效率的实现任何复杂的聚合逻辑。
comebineyeByKey属于聚合类操作,由于它支持map端的聚合所以比groupByKey性能好,又由于它的map端与reduce端可以设置成不一样的逻辑,所以它支持的场景比reduceByKey多,它的定义如下:

reduceByKey和groupByKey内部实际是调用了comebineyeByKey,
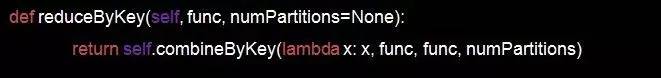
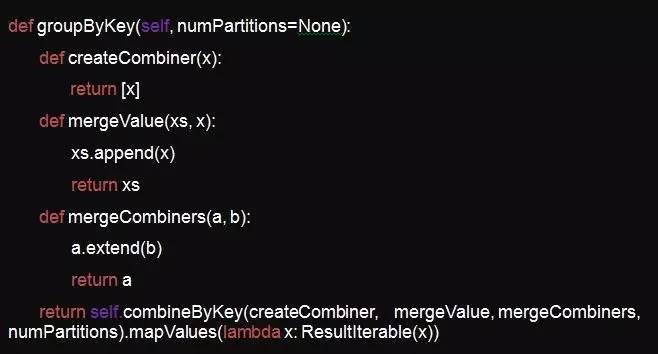
我们之前有很多复杂的无法用reduceByKey来实现的聚合逻辑都通过groupByKey来完成的,后来全部替换为comebineyeByKey后性能提升了不少。
3. 处理数据倾斜
有些时候经过一系列转换操作之后数据变得十分倾斜,在这样情况下后续的RDD计算效率会非常的糟糕,严重时程序报错。遇到这种情况通常会使用repartition这个转换操作对RDD进行重新分区,重新分区后数据会均匀分布在不同的分区中,避免了数据倾斜。如果是减少分区使用coalesce也可以达到效果,但比起repartition不足的是分配不是那么均匀。
5. 小结
虽然京东的预测系统已经稳定运行了很长一段时间,但是我们也看到系统本身还存在着很多待改进的地方,接下来我们会在预测准确度的提高、系统性能的优化、多业务支持的便捷性上进行改进。未来,随着大数据、人工智能技术在京东供应链管理中的使用越来越多,预测系统也将发挥出更大作用,对于京东预测系统的研发工作也将是充满着挑战与乐趣。














 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









