







 本文探讨了在游戏编程中如何利用神经网络技术,通过详细阐述神经网络的工作原理和算法,展示了其在游戏智能行为、角色学习和环境交互等方面的重要作用。通过实例,解释了如何结合vector运算来实现更复杂的决策过程,提升游戏体验。
本文探讨了在游戏编程中如何利用神经网络技术,通过详细阐述神经网络的工作原理和算法,展示了其在游戏智能行为、角色学习和环境交互等方面的重要作用。通过实例,解释了如何结合vector运算来实现更复杂的决策过程,提升游戏体验。
游戏编程中的人工智能技术
.
.
<神经网络入门>
.
(连载之一)
用平常语言介绍神经网络
(Neural Networks in Plain English)
(Neural Networks in Plain English)
|
因为我们没有很好了解大脑,我们经常试图用最新的技术作为一种模型来解释它。在我童年的时候,我们都坚信大脑是一部电话交换机。(否则它还能是什么呢?)我当时还看到英国著名神经学家谢林顿把大脑的工作挺有趣地比作一部电报机。更早些时候,弗罗伊德经常把大脑比作一部水力发电机,而莱布尼茨则把它比作了一台磨粉机。我还听人说,古希腊人把大脑功能想象为一付弹弓。显然,目前要来比喻大脑的话,那只可能是一台数字电子计算机了。 -
John R.Searle [注1]
|
神经网络介绍(Introduction to Neural Networks
)
曾有很长一个时期,人工神经网络对我来说是完全神秘的东西。当然,有关它们我在文献中已经读过了,我也能描述它们的结构和工作机理,但我始终没有能“啊哈!”一声,如同你头脑中一个难于理解的概念有幸突然得到理解时的感觉那样。我的头上好象一直有个榔头在敲着,或者像电影Animal House(中文片名为“动物屋”)中那个在痛苦地尖叫“先生,谢谢您,再给我一个啊!”的可怜家伙那样。我无法把数学概念转换成实际的应用。有时我甚至想把我读过的所有神经网络的书的作者都抓起来,把他们缚到一棵树上,大声地向他们吼叫:“不要再给我数学了,快给我一点实际东西吧!”。但无需说,这是永远不可能发生的事情。我不得不自己来填补这个空隙...由此我做了在那种条件下唯一可以做的事情。我开始干起来了。<一笑>
曾有很长一个时期,人工神经网络对我来说是完全神秘的东西。当然,有关它们我在文献中已经读过了,我也能描述它们的结构和工作机理,但我始终没有能“啊哈!”一声,如同你头脑中一个难于理解的概念有幸突然得到理解时的感觉那样。我的头上好象一直有个榔头在敲着,或者像电影Animal House(中文片名为“动物屋”)中那个在痛苦地尖叫“先生,谢谢您,再给我一个啊!”的可怜家伙那样。我无法把数学概念转换成实际的应用。有时我甚至想把我读过的所有神经网络的书的作者都抓起来,把他们缚到一棵树上,大声地向他们吼叫:“不要再给我数学了,快给我一点实际东西吧!”。但无需说,这是永远不可能发生的事情。我不得不自己来填补这个空隙...由此我做了在那种条件下唯一可以做的事情。我开始干起来了。<一笑>
这样几个星期后,在一个美丽的日子里,当时我在苏格兰海边度假,当我越过一层薄雾凝视着狭长的海湾时,我的头脑突然受到一个冲击。一下子悟到了人工神经网络是怎样工作的。我得到“啊哈!”的感觉了!但我此时身边只有一个帐篷和一个睡袋,还有半盒子的脆玉米片,没有电脑可以让我迅速写出一些代码来证实我的直觉。Arghhhhh!这时我才想到我应该买一台手提电脑。不管怎样,几天后我回到家了,我立刻让我的手指在键盘上飞舞起来。几个小时后我的第一人工神经网络程序终于编成和运行了,并且工作得挺好!自然,代码写的有点乱,需要进行整理,但它确实已能工作了,并且,更重要的是,我还知道它为什么能工作!我可以告诉你,那天我是一位非常得意的人。
我希望本书传递给你的就是这种“啊哈!”感觉。当我们学完遗传算法时,你可能已尝到了一点感觉,但你希望这种感觉是美妙的话,那就要等把神经网络部分整个学完。
生物学的神经网络-大脑
(A Biological Neural Network–The Brain)
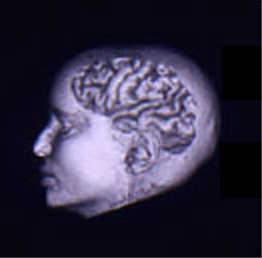
....你的大脑是一块灰色的、像奶冻一样的东西。它并不像电脑中的CPU那样,利用单个的处理单元来进行工作。如果你有一具新鲜地保存到福尔马林中的尸体,用一把锯子小心地将它的头骨锯开,搬掉头盖骨后,你就能看到熟悉的脑组织皱纹。大脑的外层象一个大核桃那样,全部都是起皱的 [图0左],这一层组织就称皮层(Cortex)。如果你再小心地用手指把整个大脑从头颅中端出来,再去拿一把外科医生用的手术刀,将大脑切成片,那么你将看到大脑有两层 [图0右]: 灰色的外层(这就是“灰质”一词的来源,但没有经过福尔马林固定的新鲜大脑实际是粉红色的。) 和白色的内层。灰色层只有几毫米厚,其中紧密地压缩着几十亿个被称作neuron(神经细胞、神经元)的微小细胞。白色层在皮层灰质的下面,占据了皮层的大部分空间,是由神经细胞相互之间的无数连接组成。皮层象核桃一样起皱,这可以把一个很大的表面区域塞进到一个较小的空间里。这与光滑的皮层相比能容纳更多的神经细胞。人的大脑大约含有1OG(即100亿)个这样的微小处理单元;一只蚂蚁的大脑大约也有250,OOO个。
生物学的神经网络-大脑
(A Biological Neural Network–The Brain)
....你的大脑是一块灰色的、像奶冻一样的东西。它并不像电脑中的CPU那样,利用单个的处理单元来进行工作。如果你有一具新鲜地保存到福尔马林中的尸体,用一把锯子小心地将它的头骨锯开,搬掉头盖骨后,你就能看到熟悉的脑组织皱纹。大脑的外层象一个大核桃那样,全部都是起皱的 [图0左],这一层组织就称皮层(Cortex)。如果你再小心地用手指把整个大脑从头颅中端出来,再去拿一把外科医生用的手术刀,将大脑切成片,那么你将看到大脑有两层 [图0右]: 灰色的外层(这就是“灰质”一词的来源,但没有经过福尔马林固定的新鲜大脑实际是粉红色的。) 和白色的内层。灰色层只有几毫米厚,其中紧密地压缩着几十亿个被称作neuron(神经细胞、神经元)的微小细胞。白色层在皮层灰质的下面,占据了皮层的大部分空间,是由神经细胞相互之间的无数连接组成。皮层象核桃一样起皱,这可以把一个很大的表面区域塞进到一个较小的空间里。这与光滑的皮层相比能容纳更多的神经细胞。人的大脑大约含有1OG(即100亿)个这样的微小处理单元;一只蚂蚁的大脑大约也有250,OOO个。
以下
表l显示了人和几种动物的神经细胞的数目。
 |
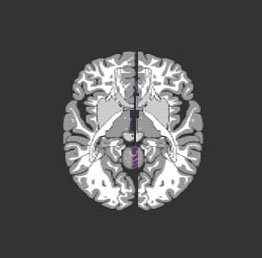 |
| 图0-1 大脑半球像核桃 | 图0-2 大脑皮层由灰质和白质组成 |
图0 大脑的外形和切片形状
表l 人和几种动物的神经细胞的数目
|
动 物
|
神经细胞的数目(数量级)
|
|
蜗 牛
|
10,000 (=10^4)
|
|
蜜 蜂
|
100,000 (=10^5)
|
|
蜂 雀
|
10,000,000 (=10^7)
|
|
老 鼠
|
100,000,000 (=10^8)
|
|
人 类
|
10,000,000,000 (=10^10)
|
|
大 象
|
100,000,000,000 (=10^11)
|
 |
|
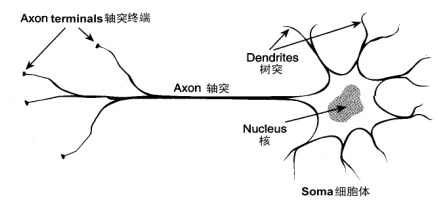
图1神经细胞的结构
|
在人的生命的最初9个月内,这些细胞以每分钟25,000个的惊人速度被创建出来。神经细胞和人身上任何其他类型细胞十分不同,每个神经细胞都长着一根像电线一样的称为轴突(axon)的东西,它的长度有时伸展到几厘米[译注],用来将信号传递给其他的神经细胞。神经细胞的结构如 图1所示。它由一个细胞体(soma)、一些树突(dendrite) 、和一根可以很长的轴突组成。神经细胞体是一颗星状球形物,里面有一个核(nucleus)。树突由细胞体向各个方向长出,本身可有分支,是用来接收信号的。轴突也有许多的分支。轴突通过分支的末梢(terminal)和其他神经细胞的树突相接触,形成所谓的突触(Synapse,图中未画出),一个神经细胞通过轴突和突触把产生的信号送到其他的神经细胞。
每个神经细胞通过它的树突和大约10,000个其他的神经细胞相连。这就使得你的头脑中所有神经细胞之间连接总计可能有l,000,000,000,000,000个。这比100兆个现代电话交换机的连线数目还多。所以毫不奇怪为什么我们有时会产生头疼毛病!
|
有趣的事实 曾经有人估算过,如果将一个人的大脑中所有神经细胞的轴突和树突依次连接起来,并拉成一根直线,可从地球连到月亮,再从月亮返回地球。如果把地球上所有人脑的轴突和树突连接起来,则可以伸展到离开们最近的星系! |
神经细胞利用电-化学过程交换信号。输入信号来自另一些神经细胞。这些神经细胞的轴突末梢(也就是终端)和本神经细胞的树突相遇形成突触(synapse),信号就从树突上的突触进入本细胞。信号在大脑中实际怎样传输是一个相当复杂的过程,但就我们而言,重要的是把它看成和现代的计算机一样,利用一系列的0和1来进行操作。就是说,大脑的神经细胞也只有两种状态:兴奋(fire)和不兴奋(即抑制)。发射信号的强度不变,变化的仅仅是频率。神经细胞利用一种我们还不知道的方法,把所有从树突上突触进来的信号进行相加,如果全部信号的总和超过某个阀值,就会激发神经细胞进入兴奋(fire)状态,这时就会有一个电信号通过轴突发送出去给其他神经细胞。如果信号总和没有达到阀值,神经细胞就不会兴奋起来。这样的解释有点过分简单化,但已能满足我们的目的。
神经细胞利用电-化学过程交换信号。输入信号来自另一些神经细胞。这些神经细胞的轴突末梢(也就是终端)和本神经细胞的树突相遇形成突触(synapse),信号就从树突上的突触进入本细胞。信号在大脑中实际怎样传输是一个相当复杂的过程,但就我们而言,重要的是把它看成和现代的计算机一样,利用一系列的0和1来进行操作。就是说,大脑的神经细胞也只有两种状态:兴奋(fire)和不兴奋(即抑制)。发射信号的强度不变,变化的仅仅是频率。神经细胞利用一种我们还不知道的方法,把所有从树突上突触进来的信号进行相加,如果全部信号的总和超过某个阀值,就会激发神经细胞进入兴奋(fire)状态,这时就会有一个电信号通过轴突发送出去给其他神经细胞。如果信号总和没有达到阀值,神经细胞就不会兴奋起来。这样的解释有点过分简单化,但已能满足我们的目的。
神经细胞利用电-化学过程交换信号。输入信号来自另一些神经细胞。这些神经细胞的轴突末梢(也就是终端)和本神经细胞的树突相遇形成突触(synapse),信号就从树突上的突触进入本细胞。信号在大脑中实际怎样传输是一个相当复杂的过程,但就我们而言,重要的是把它看成和现代的计算机一样,利用一系列的0和1来进行操作。就是说,大脑的神经细胞也只有两种状态:兴奋(fire)和不兴奋(即抑制)。发射信号的强度不变,变化的仅仅是频率。神经细胞利用一种我们还不知道的方法,把所有从树突上突触进来的信号进行相加,如果全部信号的总和超过某个阀值,就会激发神经细胞进入兴奋(fire)状态,这时就会有一个电信号通过轴突发送出去给其他神经细胞。如果信号总和没有达到阀值,神经细胞就不会兴奋起来。这样的解释有点过分简单化,但已能满足我们的目的。
正是由于数量巨大的连接,使得大脑具备难以置信的能力。尽管每一个神经细胞仅仅工作于大约100Hz的频率,但因各个神经细胞都以独立处理单元的形式并行工作着,使人类的大脑具有下面这些非常明显的特点:
能实现无监督的学习。 有关我们的大脑的难以置信的事实之一,就是它们能够自己进行学习,而不需要导师的监督教导。如果一个神经细胞在一段时间内受到高频率的刺激,则它和输入信号的神经细胞之间的连接强度就会按某种过程改变,使得该神经细胞下一次受到激励时更容易兴奋。这一机制是50多年以前由Donard Hebb在他写的Organination of Behavior一书中阐述的。他写道:
能实现无监督的学习。 有关我们的大脑的难以置信的事实之一,就是它们能够自己进行学习,而不需要导师的监督教导。如果一个神经细胞在一段时间内受到高频率的刺激,则它和输入信号的神经细胞之间的连接强度就会按某种过程改变,使得该神经细胞下一次受到激励时更容易兴奋。这一机制是50多年以前由Donard Hebb在他写的Organination of Behavior一书中阐述的。他写道:
|
“当神经细胞 A的一个轴突重复地或持久地激励另一个神经细胞B后,则其中的一个或同时两个神经细胞就会发生一种生长过程或新陈代谢式的变化,使得励 B细胞之一的A细胞,它的效能会增加”
|
与此相反的就是,如果一个神经细胞在一段时间内不受到激励,那么它的连接的有效性就会慢慢地衰减。这一现象就称可塑性(plasticity)。
对损伤有冗余性(tolerance)。大脑即使有很大一部分受到了损伤,它仍然能够执行复杂的工作。一个著名的试验就是训练老鼠在一个迷宫中行走。然后,科学家们将其大脑一部分一部分地、越来越大地加以切除。他们发现,即使老鼠的很大的一部大脑被切除后,它们仍然能在迷宫中找到行走路径。这一事实证明了,在大脑中,知识并不是保存在一个局部地方。另外所作的一些试验则表明,如果大脑的一小部分受到损伤,则神经细胞能把损伤的连接重新生长出来。
处理信息的效率极高。神经细胞之间电-化学信号的传递,与一台数字计算机中CPU的数据传输相比,速度是非常慢的,但因神经细胞采用了并行的工作方式,使得大脑能够同时处理大量的数据。例如,大脑视觉皮层在处理通过我们的视网膜输入的一幅图象信号时,大约只要100ms的时间就能完成。考虑到你的神经细胞的平均工作频率只有100Hz,100ms的时间就意味只能完成10个计算步骤!想一想通过我们眼睛的数据量有多大,你就可以看到这真是一个难以置信的伟大工程了。
善于归纳推广。大脑和数字计算机不同,它极擅长的事情之一就是模式识别,并能根据已熟悉信息进行归纳推广(generlize)。例如,我们能够阅读他人所写的手稿上的文字,即使我们以前从来没见过他所写的东西。
它是有意识的。意识(consciousness)是神经学家和人工智能的研究者广泛而又热烈地在辩论的一个话题。有关这一论题已有大量的文献出版了,但对于意识实际究竟是什么,至今尚未取得实质性的统一看法。我们甚至不能同意只有人类才有意识,或者包括动物王国中人类的近亲在内才有意识。一头猩猩有意识吗?你的猫有意识吗?上星期晚餐中被你吃掉的那条鱼有意识吗?
因此,一个人工神经网络(Artificial neural network,简称ANN)就是要在当代数字计算机现有规模的约束下,来模拟这种大量的并行性,并在实现这一工作时,使它能显示许多和生物学大脑相类似的特性。下面就让我们瞧瞧它们的表演吧!
游戏编程中的人工智能技术
.
.
<神经网络入门>
.(连载之二)
3 数字版的神经网络 (The Digital Version)
上面我们看到了生物的大脑是由许多神经细胞组成,同样,模拟大脑的人工神经网络ANN是由许多叫做人工神经细胞(Artificial neuron,也称人工神经原,或人工神经元)的细小结构模块组成。人工神经细胞就像真实神经细胞的一个简化版,但采用了电子方式来模拟实现。一个人工神经网络中需要使用多少个数的人工神经细胞,差别可以非常大。有的神经网络只需要使用10个以内的人工神经细胞,而有的神经网络可能需要使用几千个人工神经细胞。这完全取决于这些人工神经网络准备实际用来做什么。
| 有趣的事实 有一个叫 Hugo de Garis的同行,曾在一个雄心勃勃的工程中创建并训练了一个包含1000,000,000个人工神经细胞的网络。这个人工神经网络被他非常巧妙地建立起来了,它采用蜂房式自动机结构,目的就是为一机器客户定制一个叫做CAM BrainMachine(“CAM大脑机器”) 的机器(CAM就是Cellular Automata Machine的缩写)。此人曾自夸地宣称这一人工网络机器将会有一只猫的智能。许多神经网络研究人员认为他是在“登星”了,但不幸的是,雇用他的公司在他的梦想尚未实现之前就破产了。此人现在犹他州,是犹他州大脑工程(Utah Brain Project)的领导。时间将会告诉我们他的思想最终是否能变成实际有意义的东西。[译注] |
我想你现在可能很想知道,一个人工神经细胞究竟是一个什么样的东西?但是,它实际上什么东西也不像; 它只是一种抽象。还是让我们来察看一下图2吧,这是表示一个人工神经细胞的一种形式。
[译注]Hugo de Garis现在为犹他州立大学教授,有关他和他的CAM机器,可在该校网站的一个网页上看到报道,其上有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









