







 本文详述了Python3.4爬虫的基础,包括HTTP协议介绍、爬取网页与图片、以及如何实现自动登录。通过实例展示了HTTP请求响应模型、常见的请求报头,并提供了伪装浏览器爬取受限页面的方法。同时,文章演示了如何保存爬取的报文及处理自动登录的过程。
本文详述了Python3.4爬虫的基础,包括HTTP协议介绍、爬取网页与图片、以及如何实现自动登录。通过实例展示了HTTP请求响应模型、常见的请求报头,并提供了伪装浏览器爬取受限页面的方法。同时,文章演示了如何保存爬取的报文及处理自动登录的过程。
摘要:本文将使用Python3.4爬网页、爬图片、自动登录。并对HTTP协议做了一个简单的介绍。在进行爬虫之前,先简单来进行一个HTTP协议的讲解,这样下面再来进行爬虫就是理解更加清楚。
一、HTTP协议
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP的请求响应模型
HTTP协议永远都是客户端发起请求,服务器回送响应。见下图:
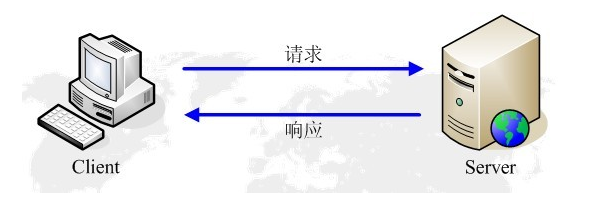
这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端。
HTTP协议是一个无状态的协议,同一个客户端的这次请求和上次请求是没有对应关系。
工作流程
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了
请求报头
请求报头允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。
常用的请求报头
Accept
Accept请求报头域用于指定客户端接受哪些类型的信息。eg:Accept:image/gif,表明客户端希望接受GIF图象格式的资源;Accept:text/html,表明客户端希望接受html文本。
Accept-Charset
Accept-Charset请求报头域用于指定客户端接受的字符集。eg:Accept-Charset:iso-8859-1,gb2312.如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
Accept-Encoding
Accept-Encoding请求报头域类似于Accept,但是它是用于指定可接受的内容编码。eg:Accept-Encoding:gzip.deflate.如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
Accept-Language
Accept-Language请求报头域类似于Accept,但是它是用于指定一种自然语言。eg:Accept-Language:zh-cn.如果请求消息中没
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6206
6206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









