







 本文介绍了Cart算法的基本原理,通过Gini系数评估节点的纯度,并使用此标准选择最佳属性进行划分。文章详细展示了如何计算属性的差异性损失,以及如何处理数值型属性。通过一个具体的例子,解释了如何构建Cart决策树,最终得出分类结果。
本文介绍了Cart算法的基本原理,通过Gini系数评估节点的纯度,并使用此标准选择最佳属性进行划分。文章详细展示了如何计算属性的差异性损失,以及如何处理数值型属性。通过一个具体的例子,解释了如何构建Cart决策树,最终得出分类结果。
ID3使用信息增益作为属性选择标准,c4.5使用信息增益率作为属性选择标准。Cart算法使用GIni系数来度量对某个属性变量测试输出的狼族取值的差异性,理想的分组应该尽量使两组中样本输出变量的差异性总和达到最小,即“纯度”最大,也就是是两组输出变量取值的差异性下降最快,“纯度”增加最快。
设t为分类回归树中的某个节点,称函数
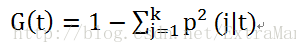
为Gini系数,k为当前属性下测试输出的类别数,p(j|t)为节点t中样本测试输出取类别j的概率。对节点t而言,G(t)越小,意味着该节点中所包含的样本越集中在某一类上,即该节点越纯,否则说明越不纯,差异性就越大。当节点样本的测试输出均取同一类别值时,输出变量取值的差异性最小,Gini系数为0,而当各类别取概率值相等时,测试输出取值的差异性最大,GIni系数也最大,为1-(1/k),其中k为目标变量的类别数。
设t为一个节点,§为该节点的一个属性分枝条件,该分支条件将该节点t中样本分别到左分支Sl和右分支Sr中,则称
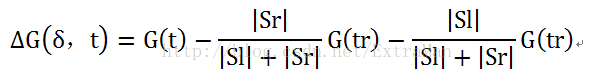
为在分支条件下节点t的差异性损失,其中,G(t)为划分前测试输出的GIni系数,|Sr|和|Sl|分辨表示划分后的左右分支的样本个数。为了使节点t尽可能的纯,我们需要选择某个属性分支条件,使该节点的差异性宣誓尽可能大。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









