







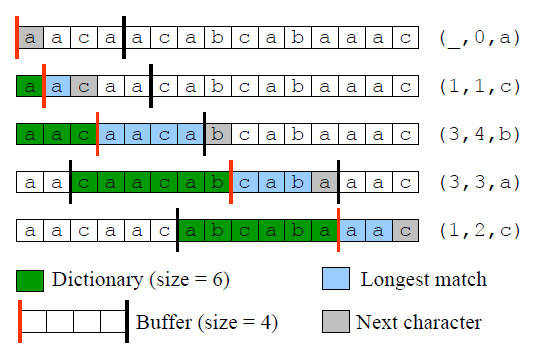
LZ77算法是一种基于词典压缩的方法,并且该词典不是静态的,而是自适应的动态词典。LZ77把已经压缩过的数据当成词典,未压缩的数据在已经压缩的数据中查找(即动态词典),然后把偏移量和匹配长度表示出来的一种方法。
介绍LZ77原理的文章很多,这里就不啰嗦了。其实算法思路也是比较简单。本着"纸上得来终觉浅"的观念,我这里实现最基本的LZ77的压缩和解压算法,实际上出于压缩效率的考虑,LZ77的压缩算法存在很多的变种。但是理解变种之前,先理解最原始的思路更有帮助,而且知道来龙去脉。如下是一个例子的简单图解。
#include <Windows.h>
#include <stdio.h>
#include "MyLZ77.h"
void TestMyLZ77()
{
//为了方便查看,使用字符串测试,MyLZ77Encode函数是支持二进制压缩的
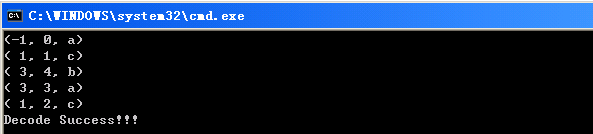
char *pTestStr = "aacaacabcabaaac";
int testStrLen = strlen(pTestStr);
PLZ77_ENCODE_LIST header = MyLZ77Encode((unsigned char*)pTestStr,testStrLen);//最后一个字节看能会多出来,暂时未处理
PLZ77_ENCODE_LIST p = header;
if(header)
{
while(p)
{
printf("(%2d,%2d,%2c)\r\n",p->item->searchResult->pos,p->item->searchResult->matchLen,p->item->nextChar);
p = p->next;
}
}
else
{
printf("Error: MyLZ77Encode return NULL\r\n");
}
char decodeBuf[1024] = {'\0'};
int decodeLen = MyLZ77Decode(header,(unsigned char*)decodeBuf); //最后一个字节看能会多出来,暂时未处理
if(decodeLen != testStrLen)
{
printf("Error:Decode len is not match data len before encode.May be add a byte in the end!!!\r\n");
}
if(strncmp(pTestStr,decodeBuf,testStrLen))
{
printf("Error:Decode data is not match data len before encode\r\n");
}
else
{
printf("Decode Success!!!\r\n");
}
}
int main(int agrc,char* argv[])
{
TestMyLZ77();
getchar();
return 0;
}和图解的例子一样,测试结果如下:
#ifndef _MYLZ77_H_
#define _MYLZ77_H_
typedef struct _t_LZ77_ENCODE_SEARCH_RESULT
{
_t_LZ77_ENCODE_SEARCH_RESULT()
{
pos = -1;
matchLen = 0;
}
short pos;//字典匹配的起始位置,相对待编码数据的偏移
short matchLen;//字典匹配的长度
}LZ77_ENCODE_SEARCH_RESULT,*PLZ77_ENCODE_SEARCH_RESULT;
typedef struct _t_LZ77_ENCODE_ITEM
{
PLZ77_ENCODE_SEARCH_RESULT searchResult;
unsigned char nextChar;//匹配后的下一个未匹配的字符
}LZ77_ENCODE_ITEM,*PLZ77_ENCODE_ITEM;
typedef struct _t_LZ77_ENCODE_LIST
{
PLZ77_ENCODE_ITEM item;
_t_LZ77_ENCODE_LIST* next;
}LZ77_ENCODE_LIST,*PLZ77_ENCODE_LIST;
//标准的LZ77编码输出,这里使用链表保存编码的结果
PLZ77_ENCODE_LIST MyLZ77Encode(unsigned char* data,int dataLen);
//标准的LZ77解码输出,输入需要编码后的链表,输出解码后的字节数
int MyLZ77Decode(PLZ77_ENCODE_LIST header,unsigned char *pDecodeOut);
#endif#include <Windows.h>
#include "MyLZ77.h"
#define MY_LZ77_DICTIONARY_LEN 0x06 //动态字典的长度设置为6字节
#define MY_LZ77_ENCODE_BUFFER_LEN 0x04 //动态编码的buf长度设备为4字节
//更新链表
PLZ77_ENCODE_LIST UpdataLZ77Link(PLZ77_ENCODE_LIST *lz77Header,PLZ77_ENCODE_LIST *pCur,PLZ77_ENCODE_ITEM item)
{
PLZ77_ENCODE_LIST p = new LZ77_ENCODE_LIST;
if(!p)
{
return NULL;
}
p->item = item;
p->next = NULL;
if(!*pCur)
{
*pCur = p;
*lz77Header = p;
}
else
{
(*pCur)->next = p;
*pCur = p;
}
return p;
}
//通过m*n的时间复杂度搜索最长匹配,可以优化该函数
PLZ77_ENCODE_SEARCH_RESULT MyLZ77Search(unsigned char *pDictionary,
unsigned short dictionarySize,
unsigned char* pEncodeBuffer,
unsigned short encodeBufferSize)
{
PLZ77_ENCODE_SEARCH_RESULT searchResult =(PLZ77_ENCODE_SEARCH_RESULT)new LZ77_ENCODE_SEARCH_RESULT;
if(!searchResult)
{
return NULL;
}
//在字典中搜索
for(int i=0;i<dictionarySize;i++)
{
int pos = i;
int index = i;
for(int j=0;j<encodeBufferSize;j++)
{
if(pEncodeBuffer[j] == pDictionary[index])
{
++index;
continue;
}
else
{
break;
}
}
int matchLen = index - i;
if(matchLen && matchLen>searchResult->matchLen)
{
searchResult->pos = dictionarySize-i;
searchResult->matchLen = matchLen;
}
}
return searchResult;
}
//标准的LZ77编码输出,这里使用链表保存编码的结果
PLZ77_ENCODE_LIST MyLZ77Encode(unsigned char* data,int dataLen)
{
if(!data || dataLen<=0)
{
return NULL;
}
int hasbeenEncodeSize = 0;//已经编码的数据大小
PLZ77_ENCODE_LIST lz77Header = NULL;
PLZ77_ENCODE_LIST pCur = NULL;
unsigned short dictionarySize = 0;//开始时字典长度为0
unsigned short encodeBufferSize = MY_LZ77_ENCODE_BUFFER_LEN;
if(dataLen<MY_LZ77_ENCODE_BUFFER_LEN)
{
encodeBufferSize = dataLen;
}
unsigned char *pDictionary = data;
unsigned char *pEncodeBuffer = data;
while(encodeBufferSize>0)
{
PLZ77_ENCODE_SEARCH_RESULT pResult = MyLZ77Search(pDictionary,dictionarySize,pEncodeBuffer,encodeBufferSize);
if(!pResult)
{
break;
}
PLZ77_ENCODE_ITEM item = new LZ77_ENCODE_ITEM;
if(!item)
{
break;
}
item->searchResult = pResult;
item->nextChar = pEncodeBuffer[pResult->matchLen];
hasbeenEncodeSize += (pResult->matchLen+1);//已编码的字节数同步增加
//更新链表
if(!UpdataLZ77Link(&lz77Header,&pCur,item))
{
break;
}
//更新动态字典
dictionarySize += pResult->matchLen+1;
if(dictionarySize>MY_LZ77_DICTIONARY_LEN)
{
dictionarySize = MY_LZ77_DICTIONARY_LEN;
pDictionary = (pEncodeBuffer+pResult->matchLen+1)-MY_LZ77_DICTIONARY_LEN;
}
//更新待编码的buffer指针,往后移动
pEncodeBuffer += (pResult->matchLen+1);
//未编码的数据已经不足MY_LZ77_ENCODE_BUFFER_LEN,更新未编码的数据,否则未编码的buffer大小仍然设置为MY_LZ77_ENCODE_BUFFER_LEN
if(dataLen-hasbeenEncodeSize<MY_LZ77_ENCODE_BUFFER_LEN)
{
encodeBufferSize = ((dataLen-hasbeenEncodeSize)>=0)?(dataLen-hasbeenEncodeSize):0;
}
}
return lz77Header;
}
//标准的LZ77解码输出,输入需要编码后的链表,输出解码后的字节数
int MyLZ77Decode(PLZ77_ENCODE_LIST header,unsigned char *pDecodeOut)
{
int decodeLen = 0;
PLZ77_ENCODE_LIST p = header;
unsigned char* pCursorData = pDecodeOut;
while(p)
{
unsigned char *pCopy = pCursorData-p->item->searchResult->pos;
for(int i=0;i<p->item->searchResult->matchLen;i++)
{
*pCursorData = *pCopy;
pCursorData++;
pCopy++;
}
*pCursorData = p->item->nextChar;
pCursorData++;
decodeLen += (p->item->searchResult->matchLen+1);
p = p->next;
}
return decodeLen;
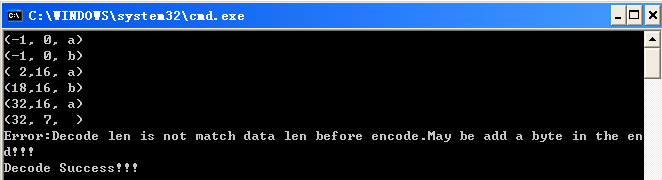
}这个例子可以看到,其实标准的原始LZ77很多时候压缩比率并不高。而在实际运用中,动态字典长度和待编码的长度都会比较长,这样压缩效果会更好。
我们修过如下:
#define MY_LZ77_DICTIONARY_LEN 32 //动态字典的长度设置为32字节
#define MY_LZ77_ENCODE_BUFFER_LEN 16 //动态编码的buf长度设备为16字节
测试字符串修过为:
char *pTestStr = "abababababababababababababababababababababababababababababab";
那么,测试结果为:















 6319
6319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









