







上几节讲述了真实数据集在回归问题以及分类问题上的总流程,但是对于模型的选择及参数的选择仍然一知半解,因此本节开始讲述关于模型的一些知识,本节会略过一些比较基础的知识,将一些较为深入的知识。如果在哪个方面没有看懂,可以在网上查询,网上基础资料也比较多,也可以在下方评论。
五、训练模型
1、线性模型
线性模型形如:
Normal Equation
使用数学方法推导能直接求得参数 θ 的方法为Normal Equation。而对于线性模型,数学方法为:最小二乘法。
通过最小二乘法能直接得到线性模型:
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
lin_reg.intercept_, lin_reg.coef_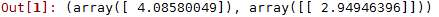
可以看到得到的结果接近4和3,没有达到准确值是由于加入了随机噪声的原因。
虽然能够精确的得到结果,但是这个算法的复杂度很高,计算
XTX
的逆的算法复杂度就为
O(n2.4)−O(n3)
,如果训练样本非常大,则运行时间会很长。而且这只是只有一种特征的情况,则运行时间会更长。
因此这种方法适合数据量较小的情况,能够找到精确解。
梯度下降法(Gradient Descent)
为了处理训练样本数比较大数据,通常采用梯度下降法,得到一个近似解,但是速度较快。梯度下降法就是通过设置学习率eta与迭代次数,每一代计算目标函数的梯度来更新权值的方法。(具体不做介绍)
学习率太小会导致收敛太慢,学习率太大会导致偏离最优解,因此可以通过之前讲的grid search来调整参数。对于迭代次数可以一开始设置一个比较大的数,当梯度开始变得很小时,则可以停下来,记录迭代次数。
Batch Gradient Descent
Batch Gradient Descent即每次迭代使用所有样本计算梯度,取平均,来更新参数。可以看到这个方法能直接朝着最优解方向前进。
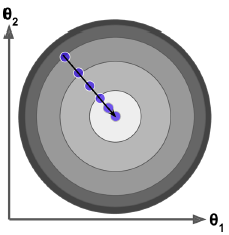
eta = 0.1 # learning rate
n_iterations = 1000
m = 100
theta = np.random.randn(2,1) # random initialization
X_b = np.c_[np.ones((100, 1)), X]
for iteration in range(n_iterations):
gradients = 2/float(m) * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients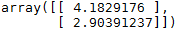
Stochastic Gradient Descent
由于Batch Gradient Descent每次迭代使用全部训练集,当训练集数据量较大时,训练速度则会很慢。因此与这个相反,随机梯度下降(Stochastic Gradient Descent)就是每一代随机选择一个样本,计算梯度,更新参数。由于每次只抽取一个样本,因此在大量数据也能很好的计算。
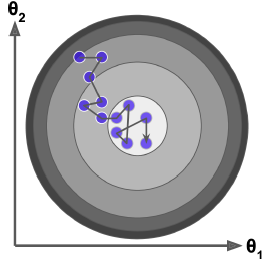
但是当接近最优解时(如图)始终无法收敛到最优解,这是由于每次根据一个样本更新参数,每个样本都有自己的梯度方向,所以会不断的在最优解附近振荡。为了解决这个问题,引入了learning_schedule参数,这个一个学习率衰减参数,在迭代的过程中,不断减少学习率,在迭代结束时学习率非常小,可以看作不再振荡,接近最优解。
随机梯度下降skicit-learn也有对应的函数:其中n_iter为迭代次数,eta0为学习率,penalty下面会说到。
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(n_iter=50, penalty=None, eta0=0.1)
sgd_reg.fit(X, y.ravel())
sgd_reg.intercept_, sgd_reg.coef_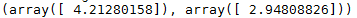
Mini-batch Gradient Descent
结合Batch Gradient Descent和Stochastic Gradient Descent,每一代计算Mini-batch(远小于Batch)个样本的梯度,计算平均值,更新参数。这种方式的好处是能在数据量比较大的训练样本中进行矩阵运算,特别是可以在GPU上计算。(在深度学习中运用的比较多)
2、多项式模型
如果数据不是简单的一条直线,也可以通过线性模型来训练,其中一种比较简单的方法是通过给训练数据特征开n次方。下面是一个例子:
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5 * X**2 + X + 2 + np.random.randn(m, 1)
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
X[0],X_poly[0]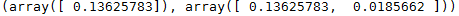
可以看到,通过PolynomialFeatures以后,得到新的特征 (x,x2) ,再用这个新特征训练一个线性模型。
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)注:若存在两个特征a和b,若degree=2时,不仅增加了 a2 和 b2 ,还有 ab
Learning Curves
如果使用高degree创造非常多特征来作多项式模型,你能够很好的拟合训练数据。然而这种只对训练数据拟合的情况称为过拟合(如图),而对于线性模型则为欠拟合。
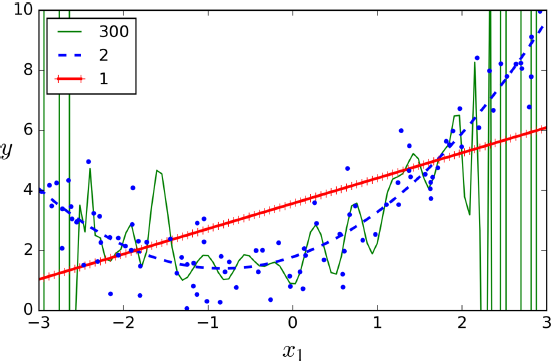
为了检测模型是否有效,在第3节已经讲述了其中一种方法,交叉验证法。下面再介绍一种方法Learning Curves。通过分开训练和验证集,不断调整训练集的数量,计算均方误差来画出曲线,观察训练集和验证集在训练中的情况。
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
train_errors, val_errors = [], []
for m in range(1, len(X_train)):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train_predict, y_train[:m]))
val_errors.append(mean_squared_error(y_val_predict, y_val))
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
plt.xlabel("Training set size")
plt.ylabel("RMSE")
lin_reg = LinearRegression()
plot_learning_curves(lin_reg, X, y)
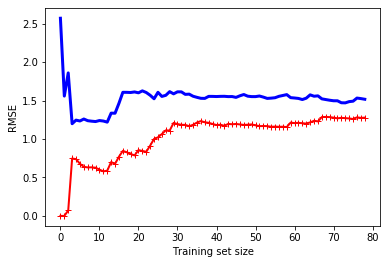
可以看到当训练集中只有一个或两个实例时,模型可以完美地拟合它们,这就是曲线从零开始的原因。但是,当新样本被添加到训练集时,模型不可能很好地拟合训练数据,这是由于样本是复杂的。再看看验证数据上模型的性能。当模型在很少的训练样本时,就不能很好的泛化推广,这就是为什么验证错误最初是相当大的。当新样本被添加到训练集时,通过学习,从而验证错误缓慢下降。误差最终会停留在一个类似高原的地方。
上面为degree=1的模型,再看看degree=10的模型
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline((
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("sgd_reg", LinearRegression()),
))
plot_learning_curves(polynomial_regression, X, y)
plt.ylim(0,2)
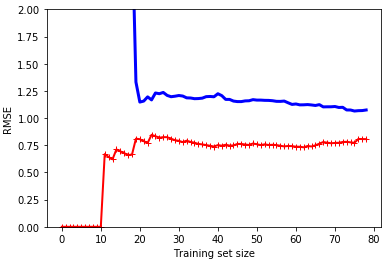
可以看到degree=10的训练误差和验证误差都比degree=1的要小。所以该模型较好。我们还可以看到两条曲线中间的间隙,间隙越大,说明过拟合程度越大。
3、正则化线性模型(Regularized Linear Models)
为了防止过拟合,可以给模型损失函数(如均方误差)增加正则项。
Ridge Regression(L2正则化)
Ridge Regression的损失函数为:
可以看到加入后面的正则项后会使 θ 靠近0,直观上可以理解为对 MSE(θ) (即模型)贡献越小的 θ ,惩罚越大,这样的 θ 越小,所以通过正则化能够减小这些无关特征带来的影响。
需要注意的是:在Ridge Regression之前要先对特征进行缩放(标准化或最大最小缩放),这是因为Ridge Regression对特征的尺度大小很敏感。
同样有两种方法计算最优解Normal Equation和梯度下降法。
对于Normal Equation结果为:
对应的代码为
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky")
ridge_reg.fit(X, y)随机梯度下降L2正则化对应的代码为
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty="l2")
sgd_reg.fit(X, y.ravel())
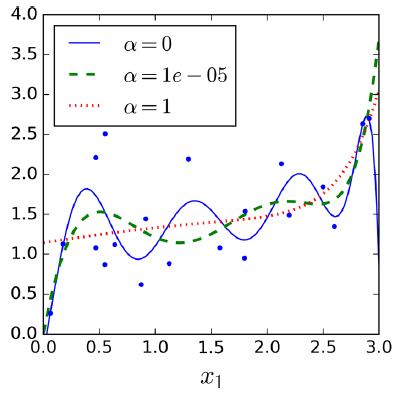
通过设置不同的 α 值,可以看到通过正则化后曲线变得平缓,看起来比没有正则化的曲线有着更好的泛化推广能力。
Lasso Regression(L1正则化)
Lasso Regression的损失函数为:
#最小二乘LASSO方法
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
#随机梯度下降正则化L2(线性)
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty="l1")
sgd_reg.fit(X, y.ravel())
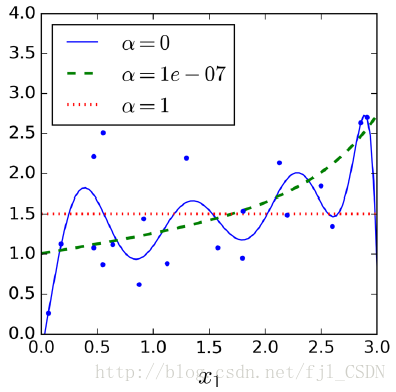
可以看到经过L1正则化后曲线变得更加平缓,更像一条直线。
需要注意的是:L1正则化后会导致在最优点附近震荡,因此要像随机梯度下降一样减小学习率。
Elastic Net
Elastic Net的损失函数为:
可以看到Elastic Net是L1正则化和L2正则化的结合,通过一个参数调整比例。
#最小二乘ElasticNet方法
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X, y)
#随机梯度下降ElasticNet(线性)
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty="elasticnet",l1_ratio=0.5)
sgd_reg.fit(X, y.ravel())如何选择正则化
加入少量的正则化一般都会给模型带来一定的提升。一般情况下都会选择Ridge(L2正则化);但是如果得知数据中只有少量的特征是有用的,那么推荐使用Lasso(L1正则化)或Elastic Net;一般来说Elastic Net会比Lasso效果要好,因为当遇到强相关性特征说特征数量大于训练样本时Lasso会表现的很奇怪。
提前中断训练(Early Stopping)
通过调整迭代次数,在验证误差达到最小时立即停止训练。图中是用Batch Gradient Descent训练的,随着迭代次数的上升,验证集上的预测误差会下降。 但是,过了一段时间验证错误停止下降,反而往上开始回升。 这表明该模型已经开始过度拟合训练数据。 一旦验证错误达到最小,立即停止训练。 这是一种简单而有效的正则化技术。
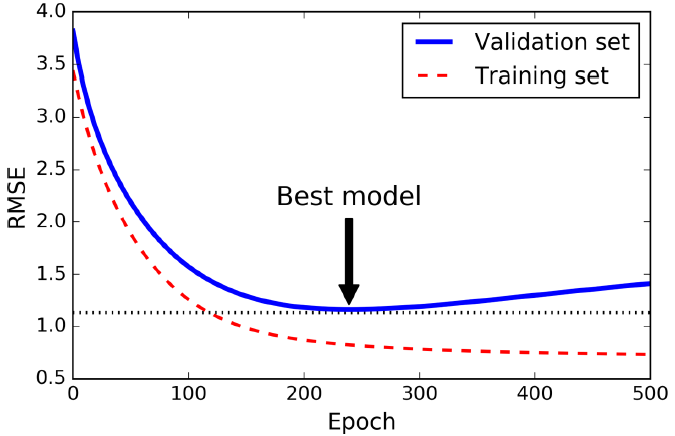
需要注意的是:对于Stochastic 和 Mini-batch Gradient Descent的曲线不会这么平滑。其中一种方案是当到达最低点时,再过一段时间(当你觉得不会再下降),停止,将参数调回到当时的最低点。
下面是一个例子,当warm_start=True时,调用fit()后继续训练模型而不是重新训练模型。
from sklearn.base import clone
sgd_reg = SGDRegressor(n_iter=1, warm_start=True, penalty=None,
learning_rate="constant", eta0=0.0005)
minimum_val_error = float("inf") #正无穷
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train) # 继续训练
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val_predict, y_val)
if val_error < minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = clone(sgd_reg) #保存模型
4、Logistic回归(Logistic Regression)
Logistic回归与线性回归模型比较相似,Logistic回归在线性回归模型的基础上增加了sigmoid函数 σ() ,即
下面利用Logistic回归对真实数据Iris进行分类。Iris数据为150个训练样本,包含4个特征,分为3类。
首先先用Logistic模型作一个二分类器。取出其中一种特征,判断是否为某一类。
#Iris
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris["data"][:, 3:] # 只读取最后一个特征
y = (iris["target"] == 2).astype(np.int) # 取出判断是否为第3类的label
#训练Logistic回归模型
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X, y)对于一个二分类问题,还可以画出判别线
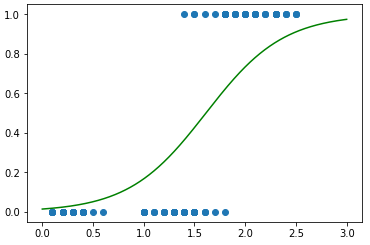
注:对于Logistic回归同样需要L1,L2正则化,而这个scikit-learn也默认设置了。
4、Softmax回归(Softmax Regression)
对于Logistic回归是一个二分类器,然而不需要像第4节所讲到了训练多个二分类器来实现多分类。Logistic回归可以直接扩展成一个多分类器Softmax回归。
与Logistic回归相似,Softmax回归计算每一类的一个概率,归为概率最大的一类。
Softmax函数为:
对于Softmax回归使用交叉熵(cross entropy)函数作为损失函数:
下面是一个实例,LogisticRegression默认使用(OVA),如果使用Softmax就把multi_class=”multinomial”
X = iris["data"][:, (2, 3)] # petal length, petal width
y = iris["target"]
softmax_reg = LogisticRegression(multi_class="multinomial",solver="lbfgs", C=10)
softmax_reg.fit(X, y)
上一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(四)
下一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(六)















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









