






 本文分析了WebChat中红包图片加载过程中的网络资源浪费问题,并提出了解决方案。通过iptables规则实现对特定FIN包的标记及后续ACK包的RST响应,减少重复的DNS查询与HTTP请求。
本文分析了WebChat中红包图片加载过程中的网络资源浪费问题,并提出了解决方案。通过iptables规则实现对特定FIN包的标记及后续ACK包的RST响应,减少重复的DNS查询与HTTP请求。
just do some test on Android DUT to learn something about the behavior of the popular App WebChat.
there are many researches about Tencent QQ and WebChat for long time and becuase that i just do some test and not learn its protocal at all, here i just not to repeat the works of previous people. the perspective would also be different with others.
the most popular part of WebChat would be "lucky money", or "red packet" named by WebChat itself. i'll also base on this hot topic.
the only difference is that i will focus on the socket itself but not the logic of the protocol or the java code. what's more, i will also not cover all of the red packet sockets and only focus on one, the red packet picture socket only.
basic info about WebChat
to make it easy, still state some basic knowledge about the whole behavior of WebChat.
as a product that leaded by Xiaolong Zhang, who is firstly learnt by the public from his work on MAIL product, WebChat logic still be impacted by MAIL design more or less. basing on an so called Exchange Sync protocol with all data encrypted. by dumping its code and comparing the tcpdump log, it do have some enhance logic to choose the best CDN for the connections as researched people comment. the major info are transfered from SSL and this socket is kept as an long connection. some other resources that do not concern too much about security would go through http, which should have better time performance. socket connections of different purpose would go to different server, this is also a good design for both stability and performance.
OK, seems all basic knowledge clear. let's go to the lukcy money.
how we get an lucky money
a red packet info is received from the long connection socket, just like the plain text message(and of course it is encrypted). after that WebChat would start fetching the red packet picture - the orange frame with "恭喜发财, 大吉大利". so from the tcpdump, you would find that after a 4-way hand shake packets, an DNS query progress is triggered and then an new socket is created to send http GET packet. after that all OK, it is able to see the "恭喜发财, 大吉大利" and you are able to try how lucky you are.
all above is plain and no any different with an web browser access every day. there is nothing to learn about it, :(
the problem
the interesting thing is that if you have a new red packet comes, the whole of the above would be repeated again: DNS query, http request. and the worse is that if the time between your new red packet and the previous is not too long while longer than 1min, the client would use the previous http socket to send the http GET packet and restart a new one following the same behavior.
DNS part
DNS would have lifetime controlled by TTL, the value for the picture server vary from less than 1min to about 3 min, so the cache may not always valid. that makes sometimes we have to retart a new DNS query. but for mobile devices, the area one can move would not that wide for most people, its connected network would also not be changed that frequently, even changed, Android itself would handle this part. i do not understand why its TTL should be so short.
and by some test on different time slots using the same ISP network(insert China UNION LTE SIM CARD under LTE network), the DNS queried target IP is not changed at all.
if this part is saved, some socket and network bandwidth is saved.
HTTP part
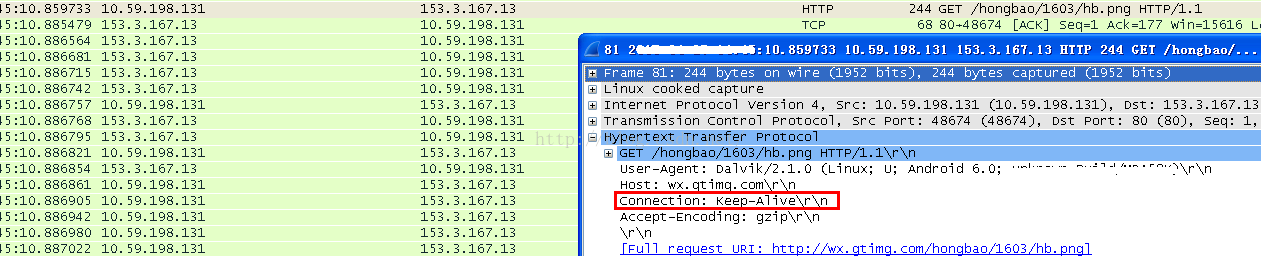
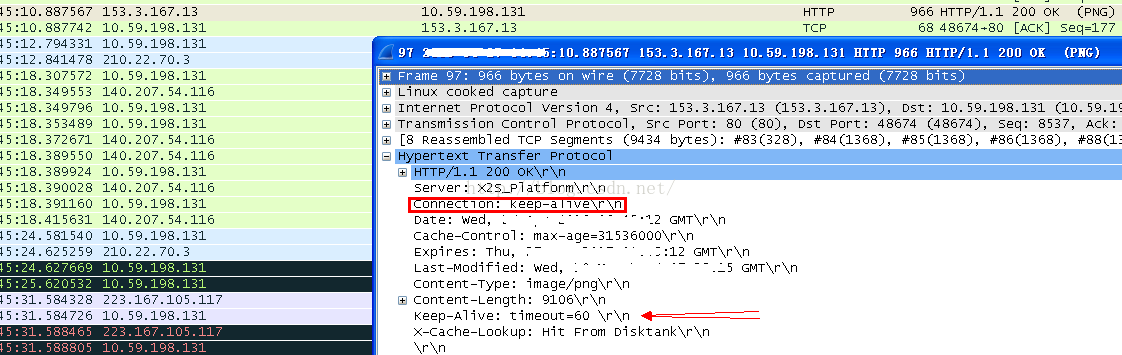
android http socket seems always makes it connection as keep alived by default and the picture connection on server also responds as accept.
.
then why the connection is not alive at last?
after checking details, the socket connections would always be terminated after 60s by an FIN response, which is just the same as http connection keep alive timeout.
while this termination would not send a following RST packet but just close its own side on server silently, client just goes into CLOSR_WAIT state.
because of TCP 4-way hand shake for socket closing, at this time, just an 0 returned while read by the client socket but the write would encounter no error to trigger the socket fail. or if the socket does nothing, nothing would happen at all.
the code below shows how a incoming FIN packet is handled.
while packets transferred from L3 to L4, they are handled by tcp_rcv_established() or tcp_rcv_state_process() basing on the socket state, and the FIN packet would be handled while processing segment text, namely in tcp_data_queue(), by calling tcp_fin().
(an interesting part of some tcp function name is that the functions like tcp_fin is not to handle sending but receiving logic, others like tcp_reset, tcp_ack...)
//kernel/net/ipv4/tcp_input.c
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
struct tcp_sock *tp = tcp_sk(sk);
...
/* step 7: process the segment text */
switch (sk->sk_state) {
...
/* step 7: process the segment text */
switch (sk->sk_state) {
case TCP_CLOSE_WAIT:
case TCP_CLOSING:
case TCP_LAST_ACK:
if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt))
break;
case TCP_FIN_WAIT1:
case TCP_FIN_WAIT2:
/* RFC 793 says to queue data in these states,
* RFC 1122 says we MUST send a reset.
* BSD 4.4 also does reset.
*/
if (sk->sk_shutdown & RCV_SHUTDOWN) {
if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq &&
after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
tcp_reset(sk);
return 1;
}
}
/* Fall through */
case TCP_ESTABLISHED:
tcp_data_queue(sk, skb);
queued = 1;
break;
}
...
int tcp_rcv_established(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
struct tcp_sock *tp = tcp_sk(sk);
...
slow_path:
...
step5:
if (tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT) < 0)
goto discard;
...
/* step 7: process the segment text */
tcp_data_queue(sk, skb);
tcp_data_snd_check(sk);
tcp_ack_snd_check(sk);
return 0;
...
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
const struct tcphdr *th = tcp_hdr(skb);
struct tcp_sock *tp = tcp_sk(sk);
...
if (eaten <= 0) {
queue_and_out:
...
if (th->fin)
tcp_fin(sk);
if (!skb_queue_empty(&tp->out_of_order_queue)) {
tcp_ofo_queue(sk);
...
static void tcp_fin(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
inet_csk_schedule_ack(sk);
sk->sk_shutdown |= RCV_SHUTDOWN;
sock_set_flag(sk, SOCK_DONE);
switch (sk->sk_state) {
case TCP_SYN_RECV:
case TCP_ESTABLISHED:
/* Move to CLOSE_WAIT */
tcp_set_state(sk, TCP_CLOSE_WAIT);
inet_csk(sk)->icsk_ack.pingpong = 1;
break;
case TCP_CLOSE_WAIT:
case TCP_CLOSING:
/* Received a retransmission of the FIN, do
* nothing.
*/
break;
...
/* It _is_ possible, that we have something out-of-order _after_ FIN.
* Probably, we should reset in this case. For now drop them.
*/
__skb_queue_purge(&tp->out_of_order_queue);
if (tcp_is_sack(tp))
tcp_sack_reset(&tp->rx_opt);
sk_mem_reclaim(sk);
if (!sock_flag(sk, SOCK_DEAD)) {
sk->sk_state_change(sk);
/* Do not send POLL_HUP for half duplex close. */
if (sk->sk_shutdown == SHUTDOWN_MASK ||
sk->sk_state == TCP_CLOSE)
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_HUP);
else
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
}
by its sk_shutdown flag RCV_SHUTDOWN and sk_state of CLOSE-WAIT, only POLL_IN would be sent, sk_state_change would only wake up sleep APP.
//kernel/net/core/sock.c
void sock_init_data(struct socket *sock, struct sock *sk)
{
...
sk->sk_state_change = sock_def_wakeup;
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
...
static void sock_def_wakeup(struct sock *sk)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (wq_has_sleeper(wq))
wake_up_interruptible_all(&wq->wait);
rcu_read_unlock();
}
the impacted part is only when read() is running, at that time it would got the return value 0 from the socket.
//kernel/net/ipv4/tcp.c
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
struct tcp_sock *tp = tcp_sk(sk);
int copied = 0;
...
lock_sock(sk);
err = -ENOTCONN;
...
do {
...
skb_queue_walk(&sk->sk_receive_queue, skb) {
...
if (tcp_hdr(skb)->fin)
goto found_fin_ok;
}
...
if (copied) {
if (sk->sk_err ||
sk->sk_state == TCP_CLOSE ||
(sk->sk_shutdown & RCV_SHUTDOWN) ||
!timeo ||
signal_pending(current))
break;
} else {
if (sock_flag(sk, SOCK_DONE))
break;
if (sk->sk_err) {
copied = sock_error(sk);
break;
}
if (sk->sk_shutdown & RCV_SHUTDOWN)
break;
if (sk->sk_state == TCP_CLOSE) {
if (!sock_flag(sk, SOCK_DONE)) {
/* This occurs when user tries to read
* from never connected socket.
*/
copied = -ENOTCONN;
break;
}
break;
}
if (!timeo) {
copied = -EAGAIN;
break;
}
if (signal_pending(current)) {
copied = sock_intr_errno(timeo);
break;
}
}
skip_copy:
...
if (tcp_hdr(skb)->fin)
goto found_fin_ok;
...
continue;
found_fin_ok:
/* Process the FIN. */
++*seq;
if (!(flags & MSG_PEEK)) {
sk_eat_skb(sk, skb, copied_early);
copied_early = false;
}
break;
} while (len > 0);
... release_sock(sk);
if (copied > 0)
uid_stat_tcp_rcv(current_uid(), copied);
return copied;
out:
release_sock(sk);
return err;and the problem is that http logic would always be an send() following read() function call pair. that makes the error can only be detected till the next HTTP request is sent when a previous HTTP transactions completed following a FIN packet by the server side. that's our encountered problem:
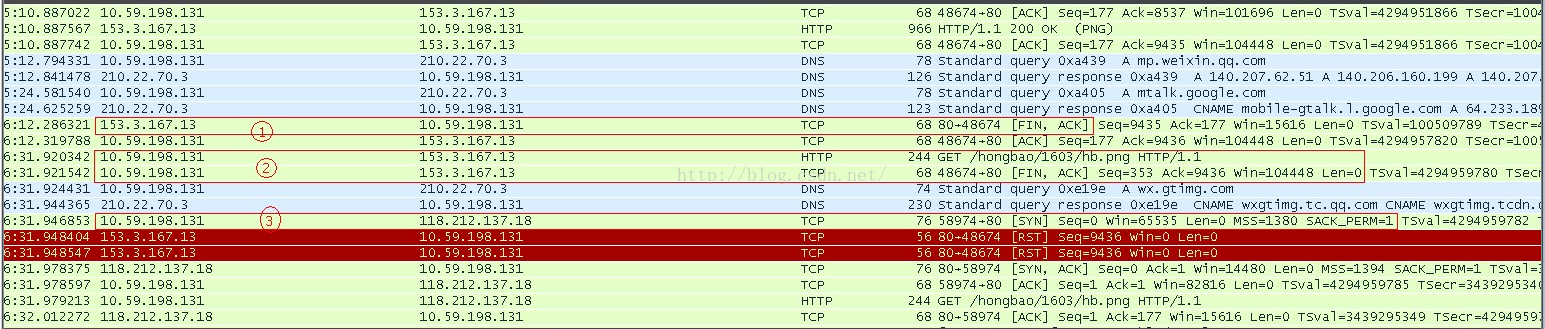
1.server sends a FIN after HTTP response when it reaches its timeout config;
2.client still try an HTTP request and following an FIN out;
3. client initial an new socket to send the same HTTP request;
it is sure that previous socket would get RST packets from the server.
here most server would deploy some strategies like this to save resource: quickly close its connection by FIN without sending a new RST packet. but in fact most client would not aware of this and just simply follow the standard TCP design to try 4 way hand shake to try terminating the connection. that makes client cost more resource, both time and memory. and the bandwidth and CPU of the server still not be saved at all. the speed of UX still not so fast as expected.
most people may think about making the client to well handle this case by closing the socket in time and not reuse it. i think it is nice to have thought about enhance the performance at most from APP design, while an standard writing code shouldn't. it
is more preferred that the server side also follow the standard: apply the LINGER option to terminate the peer clearly but not simply close its own quietly with the other side half live. an http connection service that would not send any data do need to be
cleaned but not half live!
another try
as both the APP(WebChat) and the server(Tencent) is out of control of mine, i have to make it by some other ways.
for DNS cache, one direct solution is to query by myself periodly with a short timer than normal TTL so that cache is always alive. but that has big problem about both charge and power concern. an process do this repeatly for long time is really not a good idea. one other way is to write cache config to make the cache live with a longer live time. the only problem is that you have to have high privilege as the newer the Android version, the stricter the security design.
and that is not so interesting as you can expect.
so i'd more likely to try the left http socket part.
i'm not to rewrite the APP of change the socket API. my thought is, if server do not terminate the socket clear, let me help for it. server does not send the RST packet, we do it.
confirm the code logic
first, just make sure the RST packet handle logic. do you forget our tcp function name rule?
/kernel/net/ipv4/tcp_input.c
void tcp_reset(struct sock *sk)
{
/* We want the right error as BSD sees it (and indeed as we do). */
switch (sk->sk_state) {
case TCP_SYN_SENT:
sk->sk_err = ECONNREFUSED;
break;
case TCP_CLOSE_WAIT:
sk->sk_err = EPIPE;
break;
case TCP_CLOSE:
return;
default:
sk->sk_err = ECONNRESET;
}
/* This barrier is coupled with smp_rmb() in tcp_poll() */
smp_wmb();
if (!sock_flag(sk, SOCK_DEAD))
sk->sk_error_report(sk);
tcp_done(sk);
}
/kernel/net/core/sock.c
static void sock_def_error_report(struct sock *sk)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (wq_has_sleeper(wq))
wake_up_interruptible_poll(&wq->wait, POLLERR);
sk_wake_async(sk, SOCK_WAKE_IO, POLL_ERR);
rcu_read_unlock();
}
/kernel/net/ipv4/tcp.c
void tcp_done(struct sock *sk)
{
struct request_sock *req = tcp_sk(sk)->fastopen_rsk;
if (sk->sk_state == TCP_SYN_SENT || sk->sk_state == TCP_SYN_RECV)
TCP_INC_STATS_BH(sock_net(sk), TCP_MIB_ATTEMPTFAILS);
tcp_set_state(sk, TCP_CLOSE);
tcp_clear_xmit_timers(sk);
if (req != NULL)
reqsk_fastopen_remove(sk, req, false);
sk->sk_shutdown = SHUTDOWN_MASK;
if (!sock_flag(sk, SOCK_DEAD))
sk->sk_state_change(sk);
else
inet_csk_destroy_sock(sk);
}
set sk_err, trigger POLL_ERR wakeup and update sk_state as SHUTDOWN_MASK.
by this way while the next send() would fail directly without any packets out:
/kernel/net/ipv4/tcp.c
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t size)
{
struct iovec *iov;
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
...
iovlen = msg->msg_iovlen;
iov = msg->msg_iov;
copied = 0;
err = -EPIPE;
if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
goto out_err;
...
just try the work
OK, i suppose to get the uid of WebChat, and then filter that kind of packets, after an FIN got from server, generate an RST packet to the client, so the the client socket would fail next time.
by filter packets, it is of course to use iptable/netfilter rules. but there is no existed match/TARGET modules to deploy directly on the FIN packet. to write an netfilter module for iptable should be too expensive, it is best to depend on the already provided modules.
now the iptables is able to filter the packets of Webchat by its uid, the FIN packets is also be able to be found, there is rules to generate RST packets back to the sender. but no rules to make the RST send direction the same as the original packet. so we have to perform this on the response packet for the incoming FIN packet. while an ACK to the FIN is sending, the socket state should be CLOSE_WAIT, while iptable rules do not have such state, there is no way from this direction.while from another aspect, there is relationship of these two packets, they are on the same stream. and a stream connection is able to be tracked! we can mark the connection while FIN got and RST the following outgoing ACK.
as i'm working on a live device, all following are by adb cmd directly
firstly get the WebChat PID then the UID:
adb shell 'cat /proc/4918/status'
Name: com.tencent.mm
State: S (sleeping)
Tgid: 4918
Pid: 4918
PPid: 500
TracerPid: 0
Uid: 10400 10400 10400 10400
Gid: 10400 10400 10400 10400
adb shell 'iptables -t filter -A INPUT -m owner --uid-owner 10400 -p tcp --sport 80 --tcp-flags FIN,ACK FIN,ACK -j MARK --set-mark 15'
adb shell 'iptables -t filter -A INPUT -j CONNMARK --save-mark'
adb shell 'iptables -t filter -A OUTPUT -j CONNMARK --restore-mark'
adb shell 'iptables -t filter -A INPUT -j CONNMARK --restore-mark'
at last, RST the out going ACK to make client into socket err and shutdown state.
adb shell 'iptables -t filter -A OUTPUT -m mark --mark 15 -p tcp --tcp-flags ACK ACK -j REJECT --reject-with tcp-reset'as this article is so long now, for more details, please reference below source code about iptable
/kernel/net/netfilter/xt_connmark.c
/kernel/net/netfilter/xt_mark.c
/kernel/net/ipv4/netfilter/ipt_REJECT.c
all above source base on Kernel 3.10 and if you want have a try on Android, L or later version with latest WebChat is preferred.
after all applied, it should be work like
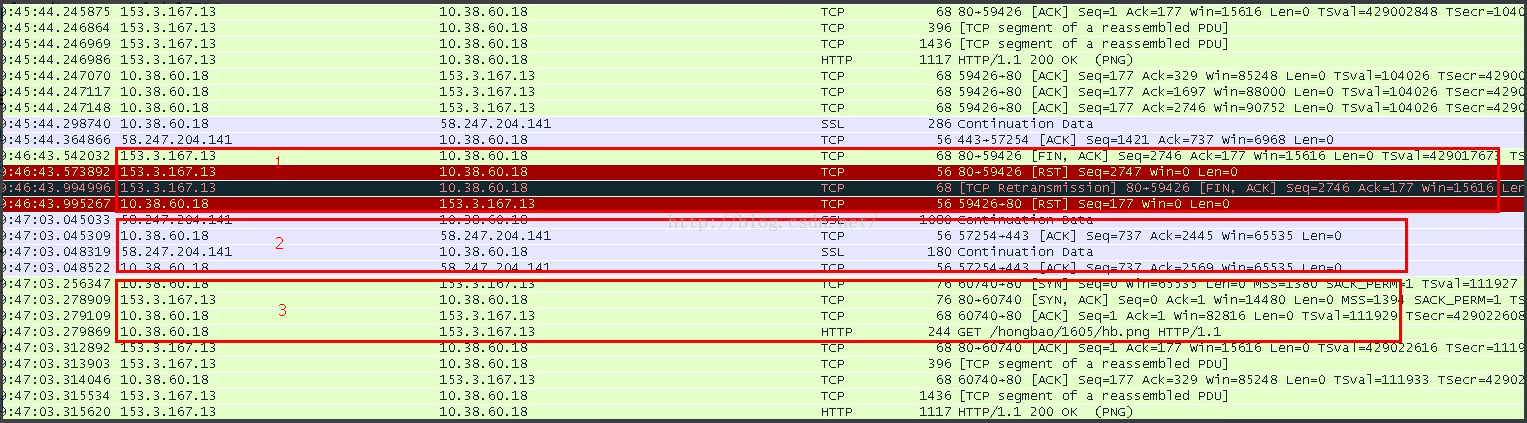
you'll find the ACK is lost and no packets are saved. that's an bad part. while the good news is that the following socket connection time is saved:
1.reset socket right after got FIN, as the RST without ACK back, server retransmits the FIN, getting another and realreal RST;
2.client get red packet segments;
3.client create an new socket directly to send HTTP request.
as you can find, there is more than 0.2s gap bewteen the new SYN packet and the previous packet. as my device is nearly idle, this gap still seems big. in fact there is HTTP request trying send from previous socket, but it failed directly from kernel L4
without sending it. if there we can have mechanism to make the connection be terminated more quick, the try of the previous socket would also be saved. so you'll find that the best way to save resource is to well handle the logic from the original App code
that uses socket. it takes less effort and works with better performance, also without concern about side effect.
Reference
http://www.wooyun.org/bugs/wooyun-2010-037507
http://www.blogjava.net/yongboy/archive/2014/03/05/410636.html
http://www.cnblogs.com/lulu/p/4199544.html
http://blog.163.com/xychenbaihu@yeah/blog/static/132229655201212705752493/
http://blog.csdn.net/maotianwang/article/details/8489908


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









