







1 算法思想
算法使用频繁项集性质的先验知识。Apriori使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集。首先,通过扫描数据库,累积每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记作L1.然后,L1用于找频繁2项集的集合L2,L2用于找L3,如此迭代,直到不能再找到频繁k项集。找每个Lk需要一次数据库全扫描。
Apriori性质可用于压缩搜索空间,提高频繁项集逐层产生的效率。
Apriori性质:频繁项集的所有非空子集也必是频繁的。
Apriori算法主要包括连接步和剪枝步两步组成。在连接步和剪枝步中采用Apriori性质可以提高算法的效率。
1.1 连接步
此步骤用于从频繁k-1项集集合产生候选k项集集合。
为了计算出Lk,根据Apriori性质,需要从Lk-1选择所有可连接的对连接产生候选k项集的集合,记作Ck。假设项集中的项按字典序排序,则可连接的对是指两个频繁项集仅有最后一项不同。例如,若Lk-1的元素l1和l2是可连接的,则l1和l2两个项集的k-1个项中仅有最后一项不同,这个条件仅仅用于保证不产生重复。
1.2 剪枝步
此步骤用于快速缩小Ck包含的项集数目。
由Apriori性质可得,任何非频繁的(k-1)项集都不是频繁k项集的子集,因此,如果Ck中的一条候选k项集的任意一个(k-1)项子集不在Lk-1中,则这条候选k项集必定不是频繁的,从而可以从Ck中删除。这种子集测试可以使用当前所有频繁项集的散列树快速完成。
Ck是Lk的超集,经过子集测试压缩Ck后,即可扫描数据库,确定Ck中每个候选的计数,从而确定Lk。
2 伪代码
- 算法:Apriori, 使用逐层迭代方法基于候选产生找出频繁项集
- 输入:
- D:事务数据库;
- min_sup:最小支持度计数阈值。
- 输出: L:D中的频繁项集。
- 方法:
- 1) L1 = find_frequent_1_itemsets(D);
- 2) for (k = 2; Lk-1 ≠ ∅; k++) {
- 3) Ck = aproiri_gen(Lk-1,min_sup);
- 4) for each transaction t∈D{ //扫描D用来计数
- 5) Ct = subset(Ck,t); //找出事务t中包含的所有候选k项集,
- 6) for each candidate c∈Ct //对事务t包含的每个候选k项集的计数加一
- 7) c.count++;
- 8) }
- 9) Lk={c∈Ck | c.count ≥ min_sup}
- 10) }
- 11) return L = ∪kLk;
- procedure apriori_gen(Lk-1: frequent (k-1)-itemset; min_sup: support)
- 1) for each itemset l1∈Lk-1
- 2) for each itemset l2∈Lk-1
- 3) if (l1[1]=l2[1])∧...∧(l1[k-2]=l2[k-2])∧(l1[k-1]<l2[k-2]) then {
- 4) c = l1 连接 l2; //连接步: 产生candidates
- 5) if has_infrequent_subset(c,Lk-1) then
- 6) delete c; // 剪枝步: 移除非频繁的cadidate
- 7) else add c to Ck;
- 8) }
- 9) return Ck;
- procedure has_infrequent_subset(c:candidate k-itemset; Lk-1:frequent (k-1)-itemset)
- // 使用先验知识
- 1) for each (k-1)-subset s of c
- 2) if c∉Lk-1 then
- 3) return TRUE;
- 4) return FALSE;
其中,Lk-1表示频繁k-1项集。
实现步骤
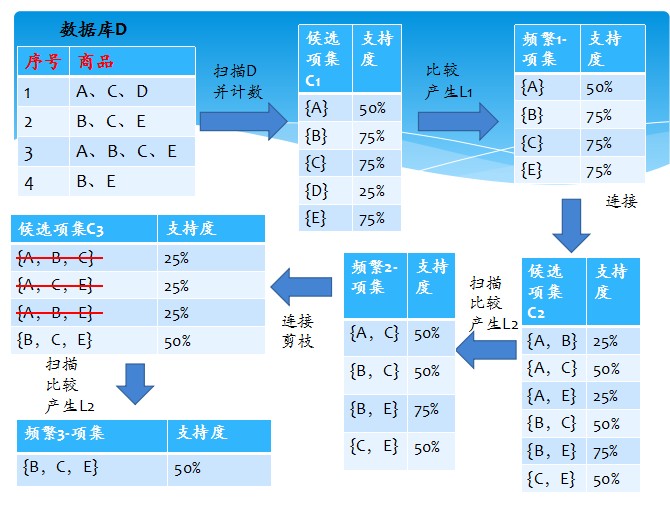
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法Apriori使用一种称作逐层搜索的迭代方法,“K-1项集”用于搜索“K项集”。
首先,找出频繁“1项集”的集合,该集合记作L1。L1用于找频繁“2项集”的集合L2,而L2用于找L3。如此下去,直到不能找到“K项集”。找每个Lk都需要一次数据库扫描。
核心思想是:连接步和剪枝步。连接步是自连接,原则是保证前k-2项相同,并按照字典顺序连接。剪枝步,是使任一频繁项集的所有非空子集也必须是频繁的。反之,如果某
个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从CK中删除。
简单的讲,1、发现频繁项集,过程为(1)扫描(2)计数(3)比较(4)产生频繁项集(5)连接、剪枝,产生候选项集 重复步骤(1)~(5)直到不能发现更大的频集
2、产生关联规则,过程为:根据前面提到的置信度的定义,关联规则的产生如下:
(1)对于每个频繁项集L,产生L的所有非空子集;
(2)对于L的每个非空子集S,如果
P(L)/P(S)≧min_conf
则输出规则“SàL-S”
注:L-S表示在项集L中除去S子集的项集















 2275
2275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









