










内容简介
- 代码一,笔记简略版本
- 代码二,词频统计与pandas集合,分词词性提取与词频统计结合
代码一
import FontCN_NLPtools as fts引用的是我自己写的一个类,是对我常用的一些方法的封装,code已经上传
# - * - coding: utf - 8 -*-
#
# 作者:田丰(FontTian)
# 创建时间:'2017/7/3'
# 邮箱:fonttian@Gmaill.com
# CSDN:http://blog.csdn.net/fontthrone
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
sys.path.append("../")
import nltk
import FontCN_NLPtools as fts
# 解决乱码问题
import matplotlib as mpl
mpl.rcParams[u'font.sans-serif'] = [u'KaiTi']
mpl.rcParams[u'font.serif'] = [u'KaiTi']
# mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题,或者转换负号为字符串
text_path = 'txt/lztest.txt' # 设置要分析的文本路径
stopwords_path = 'stopwords\CNENstopwords.txt' # 停用词词表
fontsTools = fts.FontCN_NLPtools(textPath=text_path, stopwordsPath=stopwords_path)
fontsTools.addUserWords([u'路明非'])
tokenstr = nltk.word_tokenize(fontsTools.getText(isAddWord=True))
# 全文总词数
print u"词汇表 :",
for item in tokenstr:
print item,
print
print u"词总数 :",
print len(tokenstr)
# 共出现多少词
print u"共出现词数 :",
print len(set(tokenstr))
# 词汇条目排序表
print u"词汇条目排序表 :"
for word in sorted(set(tokenstr)):
print word,
print
# 每个词平均使用次数
print u"每个词平均使用次数:",
print float(len(tokenstr)) / float(len(set(tokenstr)))
# 统计词频
fdist1 = nltk.FreqDist(tokenstr)
for key, val in sorted(fdist1.iteritems()):
print key, val,
print
print u".........路明非出现次数..............."
print fdist1[u'路明非']
print
print u".........李嘉图出现次数..............."
print fdist1[u'李嘉图']
# 统计出现最多的前5个词
print
print u".........统计出现最多的前10个词..............."
fdist1 = nltk.FreqDist(tokenstr)
for key, val in sorted(fdist1.iteritems(), key=lambda x: (x[1], x[0]), reverse=True)[:10]:
print key, val
# 前10个高频词的累积频率分布图
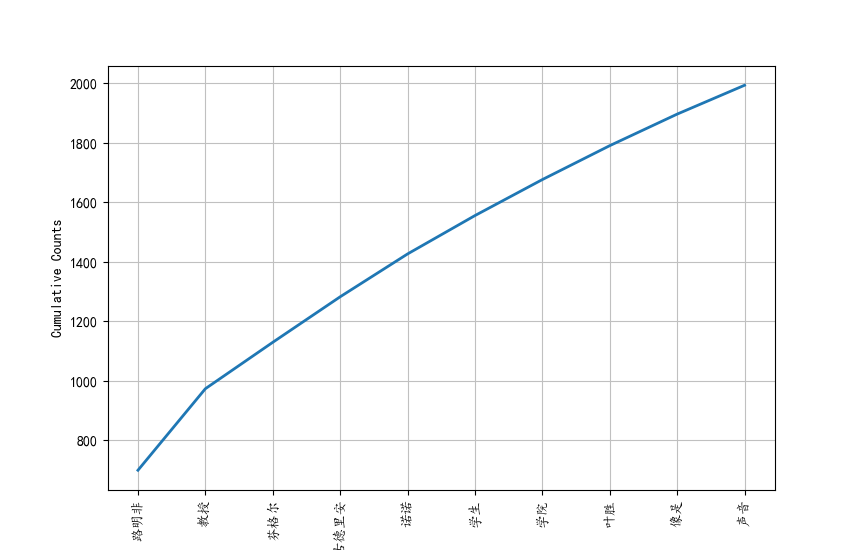
print u'...............前10个高频词的累积频率分布图...............'
fdist1.plot(10, cumulative=True)

代码二,与pandas结合,生成统计柱形图,以及词性标注与词频统计的结合
pandas是一个好用的工具,我们可以直接将前面计算好的输入pandas绘图(当然pandas能做到的,matplotlib都能做到),之所以拿的这样一个例子是因为前段时间一个项目的demo这样用过,所以拿来举例,你也可以直接用matplotlib进行绘图.
# - * - coding: utf - 8 -*-
#
# 作者:田丰(FontTian)
# 创建时间:'2017/7/12'
# 邮箱:fonttian@Gmaill.com
# CSDN:http://blog.csdn.net/fontthrone
import sys
import matplotlib.pyplot as plt
import FontCN_NLPtools as fts
import nltk
import pandas as pd
# 解决matplotlib 与 pandas 的乱码问题
# 详情请看 http://blog.csdn.net/fontthrone/article/details/75042659
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
# mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题,或者转换负号为字符串
import seaborn as sns
sns.set_style("darkgrid", {"font.sans-serif": ['KaiTi', 'Arial']})
reload(sys)
sys.setdefaultencoding('utf-8')
sys.path.append("../")
text_path = u'txt/lztest.txt' # 设置要分析的文本路径
stopwords_path = u'stopwords\CNENstopwords.txt' # 停用词词表
fontsTools = fts.FontCN_NLPtools(textPath=text_path, stopwordsPath=stopwords_path)
print
fontsTools.addUserWords([u'路明非'])
lztext = fontsTools.getText(isAddWord=True)
tokenstr = nltk.word_tokenize(lztext)
fdist1 = nltk.FreqDist(tokenstr)
listkey = []
listval = []
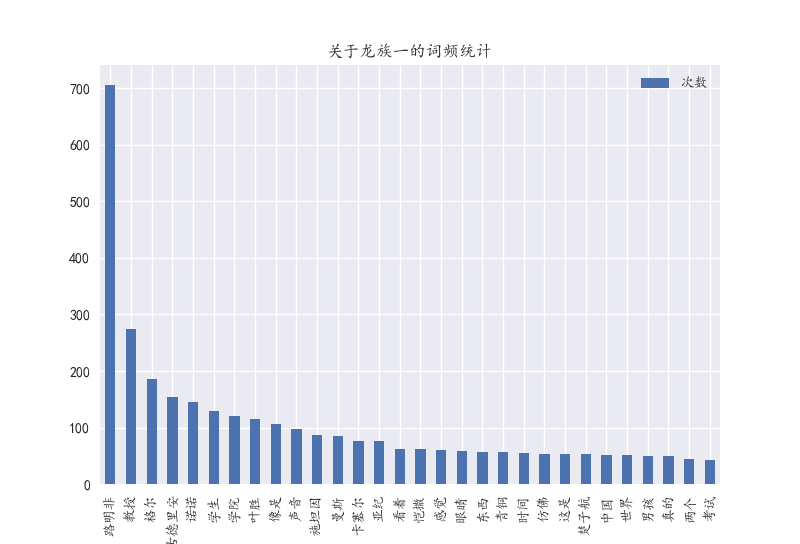
print u".........统计出现最多的前30个词..............."
for key, val in sorted(fdist1.iteritems(), key=lambda x: (x[1], x[0]), reverse=True)[:30]:
listkey.append(key)
listval.append(val)
print key, val, u' ',
df = pd.DataFrame(listval, columns=[u'次数'])
df.index = listkey
df.plot(kind='bar')
plt.title(u'关于龙族一的词频统计')
plt.show()
posstr = fontsTools.jiebaCutStrpos(NewText=lztext)
strtag = [nltk.tag.str2tuple(word) for word in posstr.split()]
cutTextList = []
for word, tag in strtag:
# 获取动词,在jieba采取和NLPIR兼容的的词性标注,对应关系我会贴在最后
if tag[0] == "V":
cutTextList.append(word)
tokenstr = nltk.word_tokenize(" ".join(cutTextList))
fdist1 = nltk.FreqDist(tokenstr)
listkey = []
listval = []
print
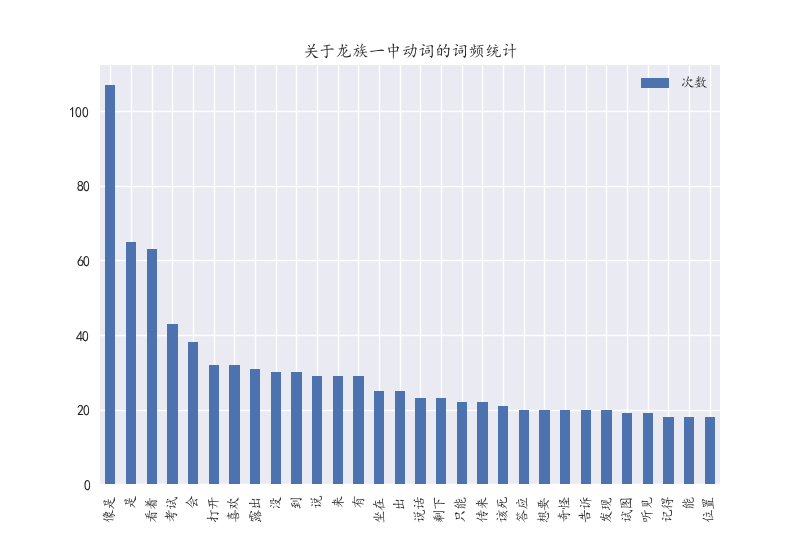
print u".........统计出现最多的前30个动词..............."
for key, val in sorted(fdist1.iteritems(), key=lambda x: (x[1], x[0]), reverse=True)[:30]:
listkey.append(key)
listval.append(val)
print key, val, u' ',
df = pd.DataFrame(listval, columns=[u'次数'])
df.index = listkey
df.plot(kind='bar')
plt.title(u'关于龙族一中动词的词频统计')
plt.show()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











