









前言
在TensorFlow中进行模型训练时,在官网给出的三种读取方式,中最好的文件读取方式就是将利用队列进行文件读取,而且步骤有两步:
1. 把样本数据写入TFRecords二进制文件
2. 从队列中读取
TFRecords二进制文件,能够更好的利用内存,更方便的移动和复制,并且不需要单独的标记文件
下面官网给出的,对mnist文件进行操作的code,具体代码请参考:tensorflow-master\tensorflow\examples\how_tos\reading_data\convert_to_records.py
CODE
源码与解析
解析主要在注释里
import tensorflow as tf
import os
import argparse
import sys
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#1.0 生成TFRecords 文件
from tensorflow.contrib.learn.python.learn.datasets import mnist
FLAGS = None
# 编码函数如下:
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def convert_to(data_set, name):
"""Converts a dataset to tfrecords."""
images = data_set.images
labels = data_set.labels
num_examples = data_set.num_examples
if images.shape[0] != num_examples:
raise ValueError('Images size %d does not match label size %d.' %
(images.shape[0], num_examples))
rows = images.shape[1] # 28
cols = images.shape[2] # 28
depth = images.shape[3] # 1. 是黑白图像,所以是单通道
filename = os.path.join(FLAGS.directory, name + '.tfrecords')
print('Writing', filename)
writer = tf.python_io.TFRecordWriter(filename)
for index in range(num_examples):
image_raw = images[index].tostring()
# 写入协议缓存区,height,width,depth,label编码成int64类型,image_raw 编码成二进制
example = tf.train.Example(features=tf.train.Features(feature={
'height': _int64_feature(rows),
'width': _int64_feature(cols),
'depth': _int64_feature(depth),
'label': _int64_feature(int(labels[index])),
'image_raw': _bytes_feature(image_raw)}))
writer.write(example.SerializeToString()) # 序列化为字符串
writer.close()
def main(unused_argv):
# Get the data.
data_sets = mnist.read_data_sets(FLAGS.directory,
dtype=tf.uint8,
reshape=False,
validation_size=FLAGS.validation_size)
# Convert to Examples and write the result to TFRecords.
convert_to(data_sets.train, 'train')
convert_to(data_sets.validation, 'validation')
convert_to(data_sets.test, 'test')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--directory',
type=str,
default='MNIST_data/',
help='Directory to download data files and write the converted result'
)
parser.add_argument(
'--validation_size',
type=int,
default=5000,
help="""\
Number of examples to separate from the training data for the validation
set.\
"""
)
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
运行结果
打印输出
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
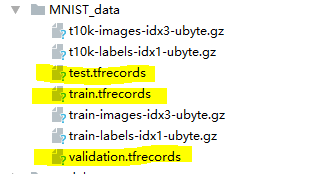
Writing MNIST_data/train.tfrecords
Writing MNIST_data/validation.tfrecords
Writing MNIST_data/test.tfrecords文件
相关
- argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块。argparse模块的作用是用于解析命令行参数,详情请参见这里:python中的argparse模块:http://blog.csdn.net/fontthrone/article/details/76735591
- 把样本数据写入TFRecords二进制文件 : http://blog.csdn.net/fontthrone/article/details/76727412
- TensorFlow笔记(基础篇):加载数据之预加载数据与填充数据:http://blog.csdn.net/fontthrone/article/details/76727466
- TensorFlow笔记(基础篇):加载数据之从队列中读取:http://blog.csdn.net/fontthrone/article/details/76728083



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











