







 本文介绍了OpenCV中的均值漂移算法,用于实时跟踪视频流中的物体。算法通过迭代找到目标位置,具有计算量小、实时性强的特点,适用于中小规模数据集。文章详细讲解了非参数估计方法,包括直方图、核密度估计,并探讨了算法在目标跟踪中的优缺点及其在工程实践中的改进策略。
本文介绍了OpenCV中的均值漂移算法,用于实时跟踪视频流中的物体。算法通过迭代找到目标位置,具有计算量小、实时性强的特点,适用于中小规模数据集。文章详细讲解了非参数估计方法,包括直方图、核密度估计,并探讨了算法在目标跟踪中的优缺点及其在工程实践中的改进策略。
1 均值漂移算法简介
均值漂移算法是一种基于密度梯度上升的非参数方法,通过迭代运算找到目标位置,实现目标跟踪。所谓跟踪,就是通过已知的图像帧中的目标位置找到目标在下一帧中的位置。均值漂移算法显著的优点是算法计算量小,简单易实现,很适合于实时跟踪场合;但是跟踪小目标和快速移动目标时常常失败,而且在全部遮挡情况下不能自我恢复跟踪。通过实验提出应用核直方图来计算目标分布,证明了均值漂移算法具有很好的实时性特点。均值漂移在聚类、图像平滑、分割、跟踪等方面有着广泛的应用。
2 均值漂移算法中的非参数估计方法
非参数估计和参数估计(即,监督参数估计和非监督参数估计)共同构成了概率密度估计方法。非参数估计也有人将其称之为无参密度估计,它是一种对先验知识要求最少,完全依靠训练数据进行估计,而且可以用于任意形状密度估计的方法。常见的非参数估计方法有以下几种:
A.直方图:把数据的值域分为若干相等的区间,数据按照区间分为若干组,每组形成一个矩形,矩形的高和该组数据的多少成正比,其底为所属区间,将这些矩形依次排列组成的图形就是直方图。它提供给数据一个直观的形象,但只适合低维数据的情况,当维数较高时,直方图所需的空间将随着维数的增加呈指数级增加。
B.核密度估计(Kernel Density Estimates,简称KDE):就是采用平滑的峰值函数(“核”)来拟合观察到的数据点,从而对真实的概率分布曲线进行模拟。原理和直方图有些类似,是一种平滑的无参密度估计方法。对于一组采样数据,把数据的值域分为若干相等的区间,每个区间称为一个bin,数据就按区间分为若干组,每组数据的个数和总参数个数的比率就是每个bin的概率值。相对于直方图法,它多了一个用于平滑数据的核函数。核密度估计方法适用于中小规模的数据集,可以很快地产生一个渐近无偏的密度估计,有良好的概率统计性质。具体来说,如果数据为x1,x2,…,xn,在任意点x的一种核密度估计为:
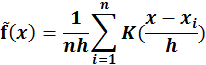
绘制成直方图是这样的:
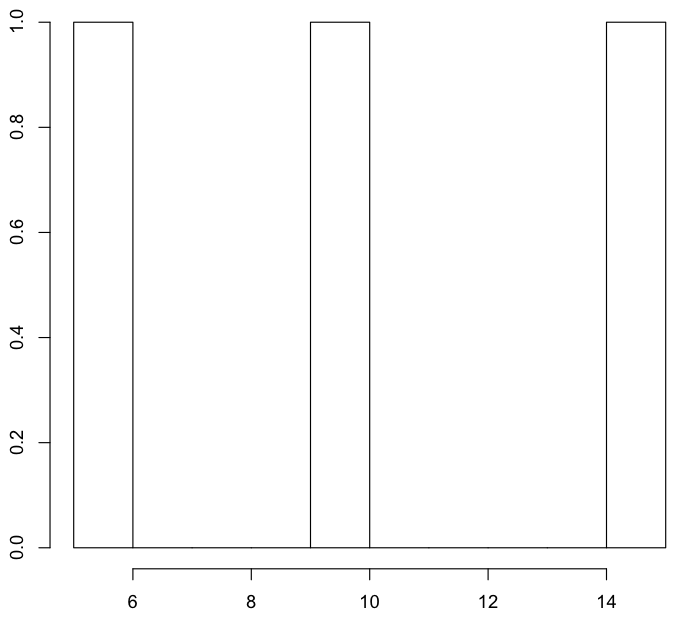
而使用KDE则是:
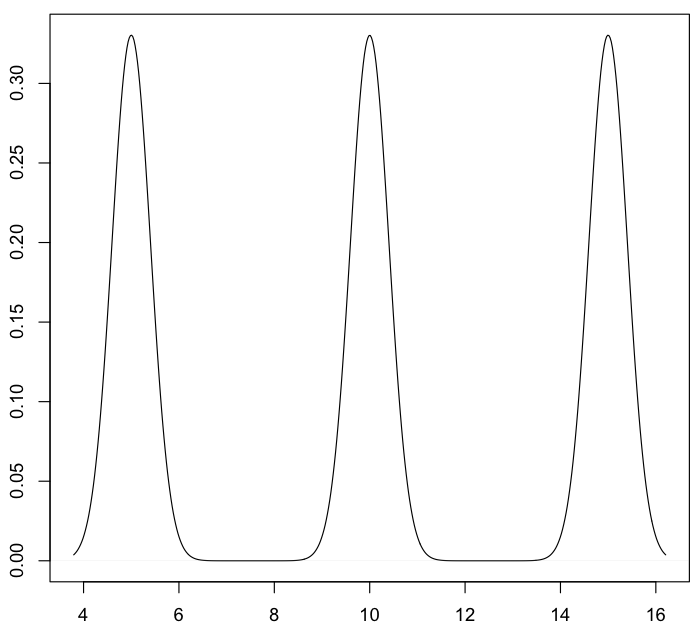
其中 K(*)称为核函数,满足对称性及 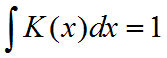
C.局部多项式密度估计:目前最流行,效果很好的密度估计 方法。对每一个点x拟合一个局部多项式来估计该点的密度。
D.K近邻估计:核密度估计的加权是以数据点到x的欧式距离为基准来进行的,而K近邻估计是无论欧氏距离多少,只要是x点的最近的k个点的其中之一就可参与加权。一种具体的k近邻密度估计:
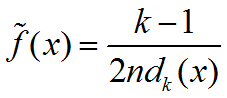
令d1<=…<=dn表示按升幂排列的x到所有n个样本点的欧氏距离。K的取值决定了估计密度曲线的光滑程度,k越大越光滑。与核估计结合起来定义广义的k近邻估计:

E.多元密度估计:上述的几种估计方法都是一元密度估计方法。假定x为d维向量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9514
9514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









