









首先来说为什么需要原子操作?
最最典型的例子:x++
我们知道它有三个步骤,1.从内存中读x的值到寄存器中 2.对寄存器加1 3.再把新值写回x所处的内存地址
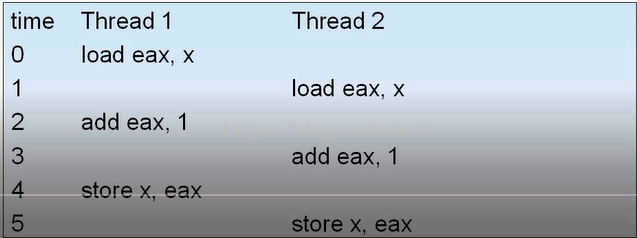
假设x的初始值为0,我们使用两个线程对x++,我们期待x的值为3,但实际上可能为2。
原因是有可能多个处理器同时从各自的缓存中读取变量i,分别进行加一操作,然后分别写入系统内存当中。那么想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
要想安全得到正确的答案:1.使用互斥锁,但是多个线程访问势必出现锁竞争,锁竞争性能杀手之一,不推荐
2.使用原子性操作,这就是本文的核心,原子性,就是不可再分,把三个过程作为一个整体。
首先我们来看一写gcc自带的原子操作:
1.原子自增操作 :
type __sync_fetch_and_add(type *ptr, type value)
原子性的让*ptr+value
2.原子比较和交换(设置)操作
type __sync_val_compare_and_swqp(type *ptr, type oldval, type newval) //先判定*ptr是否和oldval相等,如果相等设置为newval
bool __sync_bool_compare_and_swap(type *ptr, type oldval, type newval)
3.原子赋值操作
type __sync_lock_test_and_set(type *ptr, type value)
相当于*ptr=value
使用这些原子操作,编译的时候需要加-march=cpu-type
我们来看一下muduo库的AtomicIntegerT类的接口:

源码分析如下:
#ifndef MUDUO_BASE_ATOMIC_H
#define MUDUO_BASE_ATOMIC_H
#include <boost/noncopyable.hpp>
#include <stdint.h>
namespace muduo
{
namespace detail
{
template<typename T>
class AtomicIntegerT : boost::noncopyable
{
public:
AtomicIntegerT()
: value_(0)
{
}
// uncomment if you need copying and assignment
//
// AtomicIntegerT(const AtomicIntegerT& that)
// : value_(that.get())
// {}
//
// AtomicIntegerT& operator=(const AtomicIntegerT& that)
// {
// getAndSet(that.get());
// return *this;
// }
T get() //返回value_的值,如果value_=0,把它和0交换。
{
// in gcc >= 4.7: __atomic_load_n(&value_, __ATOMIC_SEQ_CST)
return __sync_val_compare_and_swap(&value_, 0, 0);
}
T getAndAdd(T x) //先获取没有修改的value_的值,再给value_+x
{
// in gcc >= 4.7: __atomic_fetch_add(&value_, x, __ATOMIC_SEQ_CST)
return __sync_fetch_and_add(&value_, x);
}
T addAndGet(T x) //先加,后获取,get_and_add + x相当于先加后获取
{
return getAndAdd(x) + x;
}
T incrementAndGet() //先加1后获取
{
return addAndGet(1);
}
T decrementAndGet() //先减1后获取
{
return addAndGet(-1);
}
void add(T x) //加x,无返回值
{
getAndAdd(x);
}
void increment() //自加1,无返回值
{
incrementAndGet();
}
void decrement() //自减1,无返回值
{
decrementAndGet();
}
T getAndSet(T newValue) //先get然后设置为新的值
{
// in gcc >= 4.7: __atomic_store_n(&value, newValue, __ATOMIC_SEQ_CST)
return __sync_lock_test_and_set(&value_, newValue);
}
private:
volatile T value_; //使用volatile修饰,避免编译器优化。
};
}
typedef detail::AtomicIntegerT<int32_t> AtomicInt32;
typedef detail::AtomicIntegerT<int64_t> AtomicInt64;
}
#endif // MUDUO_BASE_ATOMIC_H
利用原子性操作还可以实现无锁队列,可以参考这篇文章http://coolshell.cn/articles/8239.html















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









