






原贴地址:
http://nbviewer.jupyter.org/github/craffel/theano-tutorial/blob/master/Theano%20Tutorial.ipynb
本帖是Jupyter notebook形式,改编为普通的python脚本形式。
Theano是一款可以让你编写符号公式类型代码并编译为不同架构(特别是CPU和GPU)的 软件包。它是Montreal大学的机器学习研究者们开发的。它不但是机器学习的应用,而且是以机器学习的思想设计的。它特别擅长于CPU-intensive和并行计算的机器学习技术,例如大规模的神经网络。
这一篇指导文章会涉及Theano的基本法则,包括一些不太容易理解的地方。也会涉及一个简单的多层感知器的例子。更加详细的教程请参见:
http://deeplearning.net/software/theano/tutorial/
# Ensure python 3 forward compatibility
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
import theano
# By convention, the tensor submodule is loaded as T
import theano.tensor as T基础 Basics
符号变量 Symbolic variables
在Theano里,所有的算法都是以符号公式的方法定义的。这更像是手写的数学公式,而不像是写代码。接下来的Theano variables 都是符号化的,它们都没有明确的值。
输入:
# theano.tensor子模块中有大量的内置符号变量类型
# 这里我们定义一个标量(0维)变量
# 输入就是它的名字
foo = T.scalar('foo')
# 现在,我们定义另外一个变量bar,是foo的平方
bar = foo**2
# 当然它也是一个theano符号变量
print(type(bar))
print(bar.type)
# 使用theano的pp(pretty print)函数,可以看到bar被符号化地定义为foo的平方
print(theano.pp(bar))输出:
<class 'theano.tensor.var.TensorVariable'>
TensorType(float64, scalar)
(foo ** TensorConstant{2})Functions
使用theano做运算时,你可以定义符号化的公式。公式可以用实际的值调用,返回实际的值。
In [4]:
# 现在还不能用foo和bar做运算
# 我们需要先定义一个theano函数
# 注意bar是foo的函数,所以foo是函数输入
# theano.function 会编译代码,根据foo的值计算bar的值
f = theano.function([foo], bar)
print(f(3))Out [4]:
9.0In [5]:
# 另外,在某些情况下你可以使用符号变量的eval模式
# 这比定义一个函数更加方便
# eval模式以一个字典dictionary为输入,keys是theano变量,values是变量的值
print(bar.eval({foo: 3}))9.0In [6]:
# 也可以使用python风格的函数定义Theano变量
# 虽然看起来比较别扭,但是对于比较复杂的例子,这样语法上更加明晰
def square(x):
return x**2
bar = square(foo)
print(bar.eval({foo: 3}))9.0theano.tensor
Theano也有vectors, matrices 和tensors类型。theano.tensor有众多函数对这些类型做运算
In [7]:
A = T.matrix('A')
x = T.vector('x')
b = T.vector('b')
# T.dot(A,x)相当于A乘以x的转置--译者注
y = T.dot(A, x) + b
# 注意是对每一个元素做平方
z = T.sum(A**2)
# theano.function可以一次计算多个公式
# 还可以设置变量的默认值
# 之后会介绍theano.config.floatX
b_default = np.array([0, 0], dtype=theano.config.floatX)
linear_mix = theano.function([A, x, theano.Param(b, default=b_default)], [y, z])
# 设置值A, x, b
print(linear_mix(np.array([[1, 2, 3],
[4, 5, 6]], dtype=theano.config.floatX), #A
np.array([1, 2, 3], dtype=theano.config.floatX), #x
np.array([4, 5], dtype=theano.config.floatX))) #b
# 使用b的默认值
print(linear_mix(np.array([[1, 2, 3],
[4, 5, 6]], dtype=theano.config.floatX), #A
np.array([1, 2, 3], dtype=theano.config.floatX))) #x[array([ 18., 37.]), array(91.0)]
[array([ 14., 32.]), array(91.0)]共享变量Shared variables
Shared variables are a little different - they actually do have an explicit value, which can be get/set and is shared across functions which use the variable. They’re also useful because they have state across function calls.
共享变量有些不同-它们有确切的值。这些值可以get/set,而且是在使用此变量的不用函数间共享的。共享变量很有用,因为它们可以代表函数调用的状态。(译者注:类似C++中的static变量)
In [8]:
shared_var = theano.shared(np.array([[1, 2], [3, 4]], dtype=theano.config.floatX))
# shared variables的类型在初始化的时候指定
print(shared_var.type())<TensorType(float64, matrix)>In [9]:
# 使用set_value设置其值
shared_var.set_value(np.array([[3, 4], [2, 1]], dtype=theano.config.floatX))
# 使用get_value查询
print(shared_var.get_value())[[ 3. 4.]
[ 2. 1.]]In [10]:
shared_squared = shared_var**2
# theano.function的第一个输入参数告诉函数的输入是什么
# 注意到share_var是共享的,它已经有了值,所以没有必要放在函数的输入里
# 因此,Theano隐含地将shared_var当函数的输入。这个函数使用了shared_squared。
# 所以我们不必将它放在theano.function的输入列表里
function_1 = theano.function([], shared_squared)
print(function_1())[[ 9. 16.]
[ 4. 1.]]updates
共享变量的值在函数里更新。这个函数使用了theano.function的updates参数
In [11]:
# 在函数中更新共享变量的值
subtract = T.matrix('subtract')
# updates取一个字典,字典keys是共享变量,values是共享变量新的值
# 这里,设置updates为shared_var = shared_var - subtract
function_2 = theano.function([subtract], shared_var, updates={shared_var: shared_var - subtract})
print("shared_var before subtracting [[1, 1], [1, 1]] using function_2:")
print(shared_var.get_value())
# shared_var - [[1, 1], [1, 1]]
function_2(np.array([[1, 1], [1, 1]], dtype=theano.config.floatX))
print("shared_var after calling function_2:")
print(shared_var.get_value())
# 注意这改变了function_1的输出,因为shared_var 是被共享的!
print("New output of function_1() (shared_var**2):")
print(function_1())shared_var before subtracting [[1, 1], [1, 1]] using function_2:
[[ 3. 4.]
[ 2. 1.]]
shared_var after calling function_2:
[[ 2. 3.]
[ 1. 0.]]
New output of function_1() (shared_var**2):
[[ 4. 9.]
[ 1. 0.]]梯度Gradients
Theano很有用的地方是它可以计算梯度。你可以符号化定义一个函数,不需要自己去推导微分公式,快速计算微分值。(译者注:一般编程思路是先由程序员推导出微分公式,然后带入数值计算;Theano是直接给入函数式和输入值,自己计算微分,不需要人工推导公式。)
In [12]:
# 注意 bar = foo**2
# 像这样计算bar对foo的梯度:
bar_grad = T.grad(bar, foo)
# 由梯度公式bar_grad = 2*foo
bar_grad.eval({foo: 10})Out[12]:
array(20.0)In [13]:
# 注意 y = Ax + b
# 像这样计算Jacobian矩阵:
y_J = theano.gradient.jacobian(y, x)
linear_mix_J = theano.function([A, x, b], y_J)
# 因为这是线性组合linear mix, 理论上输出就是A
print(linear_mix_J(np.array([[9, 8, 7], [4, 5, 6]], dtype=theano.config.floatX), #A
np.array([1, 2, 3], dtype=theano.config.floatX), #x
np.array([4, 5], dtype=theano.config.floatX))) #b
# 也可以使用theano.gradient.hessian计算Hessian (这里不再详述)[[ 9. 8. 7.]
[ 4. 5. 6.]]
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/gof/cmodule.py:327: RuntimeWarning: numpy.ndarray size changed, may indicate binary incompatibility
rval = __import__(module_name, {}, {}, [module_name])Debugging
在Theano中调试比较困难,因为实际执行的代码并非你写的代码。编译之间对你的Theano做可用性检查的一种比较简单的方法是使用test values。
In [14]:
# 定义另一个矩阵, "B"
B = T.matrix('B')
# C是A和B的点积
# 此时,Theano不知道A和B的大小shape,所以它也不可能知道A和B的点积是否有效
C = T.dot(A, B)
# 现在我们试一下
C.eval({A: np.zeros((3, 4), dtype=theano.config.floatX),
B: np.zeros((5, 6), dtype=theano.config.floatX)})---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-14-75863a5c9f35> in <module>()
6 # Now, let's try to use it
7 C.eval({A: np.zeros((3, 4), dtype=theano.config.floatX),
----> 8 B: np.zeros((5, 6), dtype=theano.config.floatX)})
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/gof/graph.pyc in eval(self, inputs_to_values)
465 args = [inputs_to_values[param] for param in inputs]
466
--> 467 rval = self._fn_cache[inputs](*args)
468
469 return rval
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/compile/function_module.pyc in __call__(self, *args, **kwargs)
865 node=self.fn.nodes[self.fn.position_of_error],
866 thunk=thunk,
--> 867 storage_map=getattr(self.fn, 'storage_map', None))
868 else:
869 # old-style linkers raise their own exceptions
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/gof/link.pyc in raise_with_op(node, thunk, exc_info, storage_map)
312 # extra long error message in that case.
313 pass
--> 314 reraise(exc_type, exc_value, exc_trace)
315
316
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/compile/function_module.pyc in __call__(self, *args, **kwargs)
853 t0_fn = time.time()
854 try:
--> 855 outputs = self.fn()
856 except Exception:
857 if hasattr(self.fn, 'position_of_error'):
ValueError: Shape mismatch: x has 4 cols (and 3 rows) but y has 5 rows (and 6 cols)
Apply node that caused the error: Dot22(A, B)
Toposort index: 0
Inputs types: [TensorType(float64, matrix), TensorType(float64, matrix)]
Inputs shapes: [(3, 4), (5, 6)]
Inputs strides: [(32, 8), (48, 8)]
Inputs values: ['not shown', 'not shown']
Outputs clients: [['output']]
HINT: Re-running with most Theano optimization disabled could give you a back-trace of when this node was created. This can be done with by setting the Theano flag 'optimizer=fast_compile'. If that does not work, Theano optimizations can be disabled with 'optimizer=None'.
HINT: Use the Theano flag 'exception_verbosity=high' for a debugprint and storage map footprint of this apply node.以上的错误信息有点让人摸不到头脑(如果我们没有指定A和B的名称,就更糟糕了)。当Theano表达式比较复杂的时候这种错误让人十分费解。它们不会告诉你出错的是Python代码中计算A和B点积的地方出错了,因为实际运行的代码不是你的Python代码-而是编译后的Theano代码!幸好,“test values”让我们绕过这个问题。但是注意,不是所有的theano方法(比如scan)允许test values。
In [15]:
# 告诉Theano我们要使用test values。如果出错就发出警告
# 设置‘warn’表示“当我没有提供test values时警告我”
theano.config.compute_test_value = 'warn'
# 将属性tag.test_value设置为测试值
A.tag.test_value = np.random.random((3, 4)).astype(theano.config.floatX)
B.tag.test_value = np.random.random((5, 6)).astype(theano.config.floatX)
# 现在,当我们计算C时就会得到一个指向正确行的错误了
C = T.dot(A, B)---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-15-038674a75ca1> in <module>()
6 B.tag.test_value = np.random.random((5, 6)).astype(theano.config.floatX)
7 # Now, we get an error when we compute C which points us to the correct line!
----> 8 C = T.dot(A, B)
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/tensor/basic.pyc in dot(a, b)
5417 return tensordot(a, b, [[a.ndim - 1], [numpy.maximum(0, b.ndim - 2)]])
5418 else:
-> 5419 return _dot(a, b)
5420
5421
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/gof/op.pyc in __call__(self, *inputs, **kwargs)
649 thunk.outputs = [storage_map[v] for v in node.outputs]
650
--> 651 required = thunk()
652 assert not required # We provided all inputs
653
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/gof/op.pyc in rval(p, i, o, n)
863 # default arguments are stored in the closure of `rval`
864 def rval(p=p, i=node_input_storage, o=node_output_storage, n=node):
--> 865 r = p(n, [x[0] for x in i], o)
866 for o in node.outputs:
867 compute_map[o][0] = True
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/tensor/basic.pyc in perform(self, node, inp, out)
5235 # gives a numpy float object but we need to return a 0d
5236 # ndarray
-> 5237 z[0] = numpy.asarray(numpy.dot(x, y))
5238
5239 def grad(self, inp, grads):
ValueError: shapes (3,4) and (5,6) not aligned: 4 (dim 1) != 5 (dim 0)(译者注:Theano虽然在python环境下运行,但是一般需要连接g++编译器。如果你不让theano连接g++编译器,例如将g++的路径从系统path删除。那么theano只能使用python的实现。这样一旦发生上述的bug,就会明确提示出是哪里出错了。)
In [16]:
# 接下来我们不会使用test values了
theano.config.compute_test_value = 'off'另外一个用到debugging的是无效计算值出现的时候,比如Nan。Theano静默接受nan值做运算,但是这种静默可能会对你接下来的Theano计算带来毁灭性打击。牺牲一点速度,我们可以让Theano在DebugMode下编译函数。这样无效的计算会产生一个错误。
In [17]:
# 一个简单的除法函数
num = T.scalar('num')
den = T.scalar('den')
divide = theano.function([num, den], num/den)
print(divide(10, 2))
# 这会出现nan
print(divide(0, 0))5.0
nanIn [18]:
# 设置mode='DebugMode',就可以在debug 模式下编译函数
divide = theano.function([num, den], num/den, mode='DebugMode')
# NaNs 现在引发错误
print(divide(0, 0))---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-18-fd8e17a1c37b> in <module>()
1 # To compile a function in debug mode, just set mode='DebugMode'
----> 2 divide = theano.function([num, den], num/den, mode='DebugMode')
3 # NaNs now cause errors
4 print(divide(0, 0))
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/compile/function.pyc in function(inputs, outputs, mode, updates, givens, no_default_updates, accept_inplace, name, rebuild_strict, allow_input_downcast, profile, on_unused_input)
306 on_unused_input=on_unused_input,
307 profile=profile,
--> 308 output_keys=output_keys)
309 # We need to add the flag check_aliased inputs if we have any mutable or
310 # borrowed used defined inputs
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/compile/pfunc.pyc in pfunc(params, outputs, mode, updates, givens, no_default_updates, accept_inplace, name, rebuild_strict, allow_input_downcast, profile, on_unused_input, output_keys)
524 accept_inplace=accept_inplace, name=name,
525 profile=profile, on_unused_input=on_unused_input,
--> 526 output_keys=output_keys)
527
528
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/compile/function_module.pyc in orig_function(inputs, outputs, mode, accept_inplace, name, profile, on_unused_input, output_keys)
1768 on_unused_input=on_unused_input,
1769 output_keys=output_keys).create(
-> 1770 defaults)
1771
1772 t2 = time.time()
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/compile/debugmode.pyc in create(self, defaults, trustme, storage_map)
2638 # Get a function instance
2639 _fn, _i, _o = self.linker.make_thunk(input_storage=input_storage,
-> 2640 storage_map=storage_map)
2641 fn = self.function_builder(_fn, _i, _o, self.indices,
2642 self.outputs, defaults, self.unpack_single,
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/gof/link.pyc in make_thunk(self, input_storage, output_storage, storage_map)
688 return self.make_all(input_storage=input_storage,
689 output_storage=output_storage,
--> 690 storage_map=storage_map)[:3]
691
692 def make_all(self, input_storage, output_storage):
/usr/local/lib/python2.7/site-packages/Theano-0.7.0-py2.7.egg/theano/compile/debugmode.pyc in make_all(self, profiler, input_storage, output_storage, storage_map)
1945 # Precompute some things for storage pre-allocation
1946 try:
-> 1947 def_val = int(config.unittests.rseed)
1948 except ValueError:
1949 def_val = 666
AttributeError: 'TheanoConfigParser' object has no attribute 'unittests'Using the CPU vs GPU
Theano 可以在不同的硬件上透明地(transparently)编译。默认使用的设备取决于你的 .theanorc 文件和定义的环境变量,详见http://deeplearning.net/software/theano/library/config.html
现在,你应该在大多数GPU上使用float32,但是大多数人喜欢在CPU上使用float64.为了方便,Theano提供floatX配置变量。它会指明所用的float精度。例如,你可以使用特定的环境变量在CPU上运行python脚本:
THEANO_FLAGS=device=cpu,floatX=float64 python your_script.py或者在GPU上:
THEANO_FLAGS=device=gpu,floatX=float32 python your_script.pyIn [19]:
# 你可以像这样查询配置Theano的值:
print(theano.config.device)
print(theano.config.floatX)cpu
float64In [20]:
# 也可以运行时get/set:
old_floatX = theano.config.floatX
theano.config.floatX = 'float32'In [21]:
# 注意你使用的是floatX!
# 例如,下面的语句使var是flaot64(numpy默认f),而不是floatX:
var = theano.shared(np.array([1.3, 2.4]))
print(var.type()) #!!!
# 所以,无论你什么时候用numpy 的array,确保将dtype设置为theano.config.floatX
var = theano.shared(np.array([1.3, 2.4], dtype=theano.config.floatX))
print(var.type())
# 恢复原来的值
theano.config.floatX = old_floatX<TensorType(float64, vector)>
<TensorType(float32, vector)>例子:MLP
多层感知器MLP的定义已经超出了本文的范围;背景详见:
http://en.wikipedia.org/wiki/Multilayer_perceptron
我们习惯认为数据点是数据矩阵的列向量。
Layler 类
我们将我们的MLP定义为一串“层级”的级联,每一层循序作用于输入,产生网络的输出。layer定义为类,存储着权重矩阵,偏执矩阵和计算layer输出的函数。
Note that if we weren’t using Theano, we might expect the output method to take in a vector and return the layer’s activation in response to this input. However, with Theano, the output function is instead meant to be used to create (using theano.function) a function which can take in a vector and return the layer’s activation. So, if you were to pass, say, a np.ndarray to the Layer class’s output function, you’d get an error. Instead, we’ll construct a function for actually computing the Layer’s activation outside of the class itself.
注意,如果我们没有使用Theano,我们可能期望输出方法以一个vector作输入,返回layer的activition处理后的输出。但是,在Theano中,输出函数会以theano.function创造一个函数。这个函数以一个vector为输入,返回layer的activation。所以,如果传给Layer类的输出函数,会发生错误。正确的方式是,在类外构造一个函数用来实际计算Layer类的activation。
In [22]:
class Layer(object):
def __init__(self, W_init, b_init, activation):
'''
A layer of a neural network, computes s(Wx + b) where s is a nonlinearity and x is the input vector.
:parameters:
- W_init : np.ndarray, shape=(n_output, n_input)
Values to initialize the weight matrix to.
- b_init : np.ndarray, shape=(n_output,)
Values to initialize the bias vector
- activation : theano.tensor.elemwise.Elemwise
Activation function for layer output
'''
# Retrieve the input and output dimensionality based on W's initialization
n_output, n_input = W_init.shape
# Make sure b is n_output in size
assert b_init.shape == (n_output,)
# All parameters should be shared variables.
# They're used in this class to compute the layer output,
# but are updated elsewhere when optimizing the network parameters.
# Note that we are explicitly requiring that W_init has the theano.config.floatX dtype
self.W = theano.shared(value=W_init.astype(theano.config.floatX),
# The name parameter is solely for printing purporses
name='W',
# Setting borrow=True allows Theano to use user memory for this object.
# It can make code slightly faster by avoiding a deep copy on construction.
# For more details, see
# http://deeplearning.net/software/theano/tutorial/aliasing.html
borrow=True)
# We can force our bias vector b to be a column vector using numpy's reshape method.
# When b is a column vector, we can pass a matrix-shaped input to the layer
# and get a matrix-shaped output, thanks to broadcasting (described below)
self.b = theano.shared(value=b_init.reshape(n_output, 1).astype(theano.config.floatX),
name='b',
borrow=True,
# Theano allows for broadcasting, similar to numpy.
# However, you need to explicitly denote which axes can be broadcasted.
# By setting broadcastable=(False, True), we are denoting that b
# can be broadcast (copied) along its second dimension in order to be
# added to another variable. For more information, see
# http://deeplearning.net/software/theano/library/tensor/basic.html
broadcastable=(False, True))
self.activation = activation
# We'll compute the gradient of the cost of the network with respect to the parameters in this list.
self.params = [self.W, self.b]
def output(self, x):
'''
Compute this layer's output given an input
:parameters:
- x : theano.tensor.var.TensorVariable
Theano symbolic variable for layer input
:returns:
- output : theano.tensor.var.TensorVariable
Mixed, biased, and activated x
'''
# Compute linear mix
lin_output = T.dot(self.W, x) + self.b
# Output is just linear mix if no activation function
# Otherwise, apply the activation function
return (lin_output if self.activation is None else self.activation(lin_output))MLP 类
Most of the functionality of our MLP is contained in the Layer class; the MLP class is essentially just a container for a list of Layers and their parameters. The output function simply recursively computes the output for each layer. Finally, the squared_error returns the squared Euclidean distance between the output of the network given an input and the desired (ground truth) output. This function is meant to be used as a cost in the setting of minimizing cost over some training data. As above, the output and squared error functions are not to be used for actually computing values; instead, they’re to be used to create functions which are used to compute values.
大多数MLP的操作都包含在了Layer类里;MLP类基本上就是Layer类及其参数的容器。输出函数只是简单迭代计算每一层Layer的输出。最终,squared_error返回网络输出和期望输出的欧几里得距离的平方。这个函数作为cost函数,通过训练数据最小化cost函数。总之,输出和平方误差函数不是用来实际计算的;相反,它们是用来创造计算数值的函数。
In [23]:
class MLP(object):
def __init__(self, W_init, b_init, activations):
'''
Multi-layer perceptron class, computes the composition of a sequence of Layers
:parameters:
- W_init : list of np.ndarray, len=N
Values to initialize the weight matrix in each layer to.
The layer sizes will be inferred from the shape of each matrix in W_init
- b_init : list of np.ndarray, len=N
Values to initialize the bias vector in each layer to
- activations : list of theano.tensor.elemwise.Elemwise, len=N
Activation function for layer output for each layer
'''
# Make sure the input lists are all of the same length
assert len(W_init) == len(b_init) == len(activations)
# Initialize lists of layers
self.layers = []
# Construct the layers
for W, b, activation in zip(W_init, b_init, activations):
self.layers.append(Layer(W, b, activation))
# Combine parameters from all layers
self.params = []
for layer in self.layers:
self.params += layer.params
def output(self, x):
'''
Compute the MLP's output given an input
:parameters:
- x : theano.tensor.var.TensorVariable
Theano symbolic variable for network input
:returns:
- output : theano.tensor.var.TensorVariable
x passed through the MLP
'''
# Recursively compute output
for layer in self.layers:
x = layer.output(x)
return x
def squared_error(self, x, y):
'''
Compute the squared euclidean error of the network output against the "true" output y
:parameters:
- x : theano.tensor.var.TensorVariable
Theano symbolic variable for network input
- y : theano.tensor.var.TensorVariable
Theano symbolic variable for desired network output
:returns:
- error : theano.tensor.var.TensorVariable
The squared Euclidian distance between the network output and y
'''
return T.sum((self.output(x) - y)**2)梯度下降Gradient descent
To train the network, we will minimize the cost (squared Euclidean distance of network output vs. ground-truth) over a training set using gradient descent. When doing gradient descent on neural nets, it’s very common to use momentum, which is simply a leaky integrator on the parameter update. That is, when updating parameters, a linear mix of the current gradient update and the previous gradient update is computed. This tends to make the network converge more quickly on a good solution and can help avoid local minima in the cost function. With traditional gradient descent, we are guaranteed to decrease the cost at each iteration. When we use momentum, we lose this guarantee, but this is generally seen as a small price to pay for the improvement momentum usually gives.
为了训练网络,我们会使用一个训练集以梯度下降法最小化cost函数。当在神经网络上使用梯度下降法时,一般会采用动量法momentum。这是在参数更新时的一种leaky intergrator。也就是,当更新参数时,计算当前的梯度更新和之前的梯度更新的线性组合。这会使网络更快地收敛于一个好的解,还可以避免局部最小值。使用传统的梯度下降法,cost在每一次迭代都会降低。使用momentum未必如此,但是这可以视为其他优势的小代价。
In Theano, we store the previous parameter update as a shared variable so that its value is preserved across iterations. Then, during the gradient update, we not only update the parameters, but we also update the previous parameter update shared variable.
在Theano中,将之前的参数更新设为共享变量,使得其值在迭代过程中能保存。然后,在梯度更新中,不仅更新参数,还更新上一步的共享变量。
In [24]:
def gradient_updates_momentum(cost, params, learning_rate, momentum):
'''
Compute updates for gradient descent with momentum
:parameters:
- cost : theano.tensor.var.TensorVariable
Theano cost function to minimize
- params : list of theano.tensor.var.TensorVariable
Parameters to compute gradient against
- learning_rate : float
Gradient descent learning rate
- momentum : float
Momentum parameter, should be at least 0 (standard gradient descent) and less than 1
:returns:
updates : list
List of updates, one for each parameter
'''
# Make sure momentum is a sane value
assert momentum < 1 and momentum >= 0
# List of update steps for each parameter
updates = []
# Just gradient descent on cost
for param in params:
# For each parameter, we'll create a param_update shared variable.
# This variable will keep track of the parameter's update step across iterations.
# We initialize it to 0
param_update = theano.shared(param.get_value()*0., broadcastable=param.broadcastable)
# Each parameter is updated by taking a step in the direction of the gradient.
# However, we also "mix in" the previous step according to the given momentum value.
# Note that when updating param_update, we are using its old value and also the new gradient step.
updates.append((param, param - learning_rate*param_update))
# Note that we don't need to derive backpropagation to compute updates - just use T.grad!
updates.append((param_update, momentum*param_update + (1. - momentum)*T.grad(cost, param)))
return updates小例子
We’ll train our neural network to classify two Gaussian-distributed clusters in 2d space.
我们会训练我们的神经网络用来分类2D的高斯分布数据。
In [25]:
# Training data - two randomly-generated Gaussian-distributed clouds of points in 2d space
np.random.seed(0)
# Number of points
N = 1000
# Labels for each cluster
y = np.random.random_integers(0, 1, N)
# Mean of each cluster
means = np.array([[-1, 1], [-1, 1]])
# Covariance (in X and Y direction) of each cluster
covariances = np.random.random_sample((2, 2)) + 1
# Dimensions of each point
X = np.vstack([np.random.randn(N)*covariances[0, y] + means[0, y],
np.random.randn(N)*covariances[1, y] + means[1, y]]).astype(theano.config.floatX)
# Convert to targets, as floatX
y = y.astype(theano.config.floatX)
# Plot the data
plt.figure(figsize=(8, 8))
plt.scatter(X[0, :], X[1, :], c=y, lw=.3, s=3, cmap=plt.cm.cool)
plt.axis([-6, 6, -6, 6])
plt.show()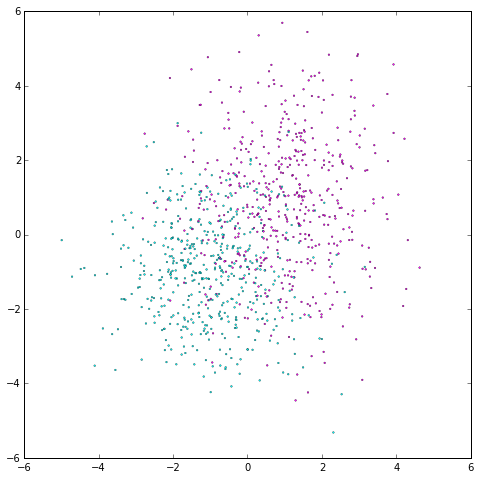
In [26]:
# First, set the size of each layer (and the number of layers)
# Input layer size is training data dimensionality (2)
# Output size is just 1-d: class label - 0 or 1
# Finally, let the hidden layers be twice the size of the input.
# If we wanted more layers, we could just add another layer size to this list.
layer_sizes = [X.shape[0], X.shape[0]*2, 1]
# Set initial parameter values
W_init = []
b_init = []
activations = []
for n_input, n_output in zip(layer_sizes[:-1], layer_sizes[1:]):
# Getting the correct initialization matters a lot for non-toy problems.
# However, here we can just use the following initialization with success:
# Normally distribute initial weights
W_init.append(np.random.randn(n_output, n_input))
# Set initial biases to 1
b_init.append(np.ones(n_output))
# We'll use sigmoid activation for all layers
# Note that this doesn't make a ton of sense when using squared distance
# because the sigmoid function is bounded on [0, 1].
activations.append(T.nnet.sigmoid)
# Create an instance of the MLP class
mlp = MLP(W_init, b_init, activations)
# Create Theano variables for the MLP input
mlp_input = T.matrix('mlp_input')
# ... and the desired output
mlp_target = T.vector('mlp_target')
# Learning rate and momentum hyperparameter values
# Again, for non-toy problems these values can make a big difference
# as to whether the network (quickly) converges on a good local minimum.
learning_rate = 0.01
momentum = 0.9
# Create a function for computing the cost of the network given an input
cost = mlp.squared_error(mlp_input, mlp_target)
# Create a theano function for training the network
train = theano.function([mlp_input, mlp_target], cost,
updates=gradient_updates_momentum(cost, mlp.params, learning_rate, momentum))
# Create a theano function for computing the MLP's output given some input
mlp_output = theano.function([mlp_input], mlp.output(mlp_input))
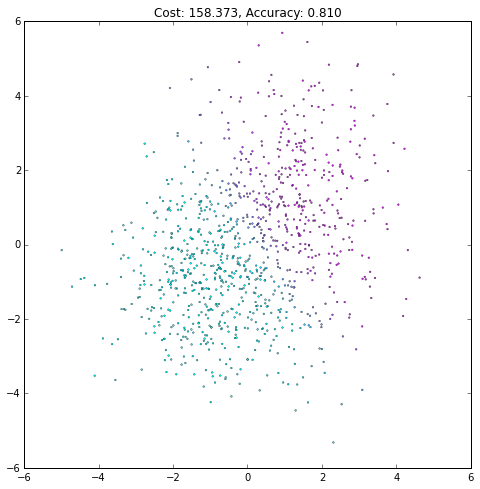
In [27]:
# Keep track of the number of training iterations performed
iteration = 0
# We'll only train the network with 20 iterations.
# A more common technique is to use a hold-out validation set.
# When the validation error starts to increase, the network is overfitting,
# so we stop training the net. This is called "early stopping", which we won't do here.
max_iteration = 20
while iteration < max_iteration:
# Train the network using the entire training set.
# With large datasets, it's much more common to use stochastic or mini-batch gradient descent
# where only a subset (or a single point) of the training set is used at each iteration.
# This can also help the network to avoid local minima.
current_cost = train(X, y)
# Get the current network output for all points in the training set
current_output = mlp_output(X)
# We can compute the accuracy by thresholding the output
# and computing the proportion of points whose class match the ground truth class.
accuracy = np.mean((current_output > .5) == y)
# Plot network output after this iteration
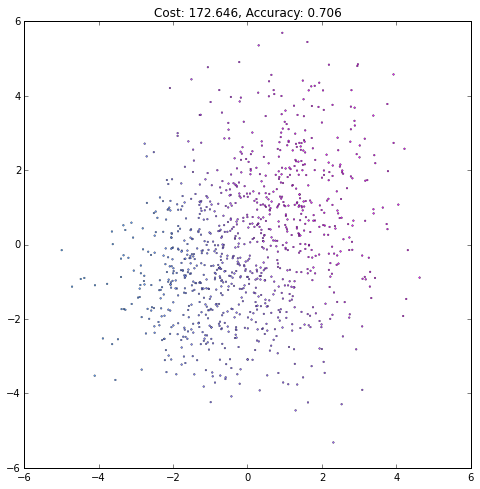
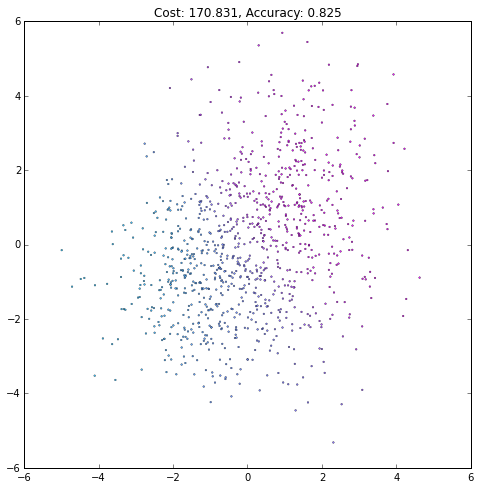
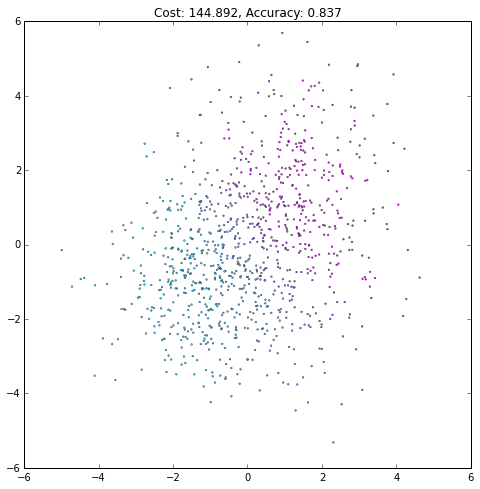
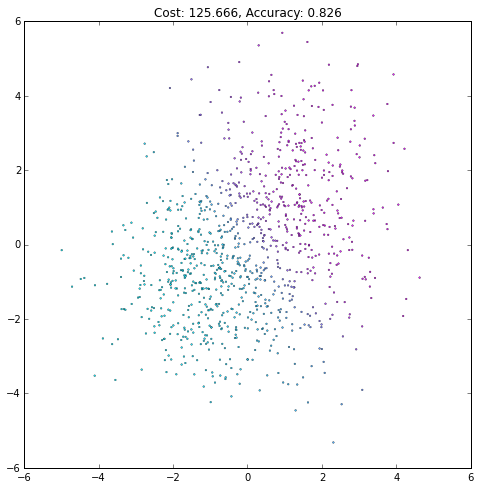
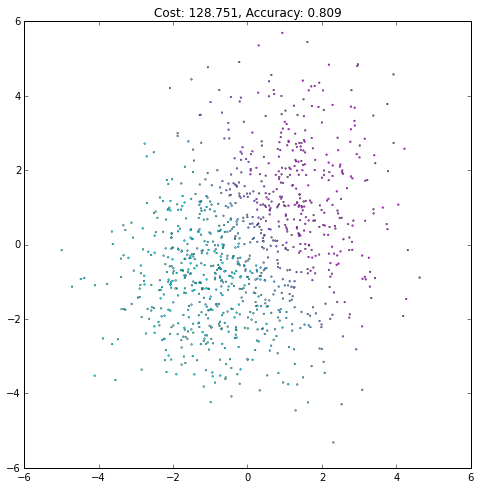
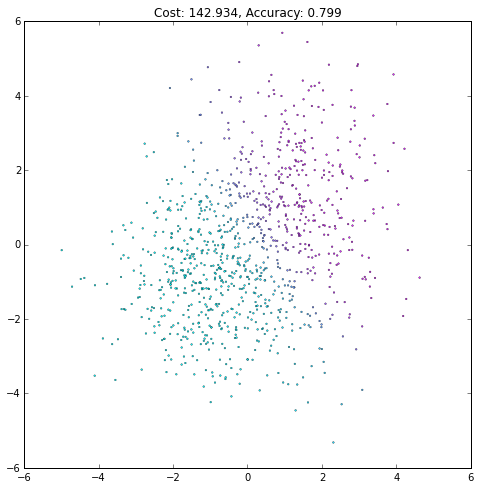
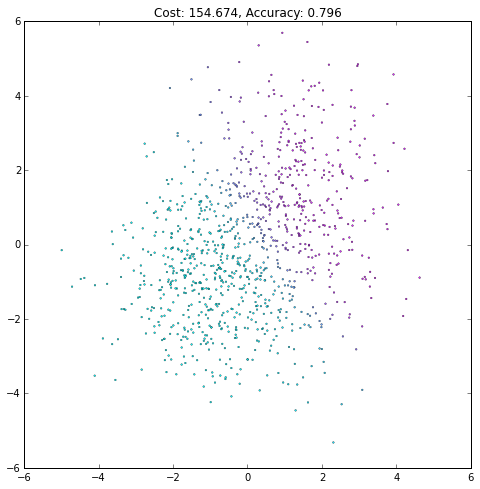
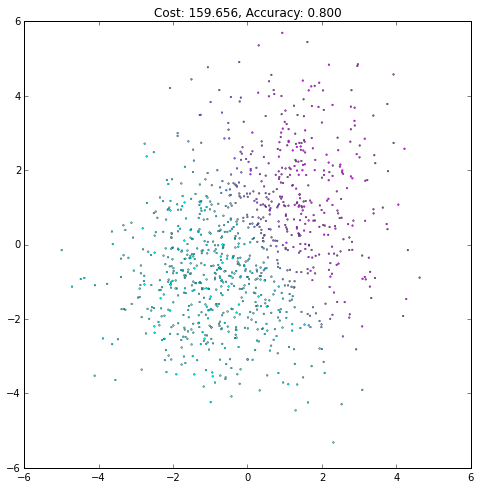
plt.figure(figsize=(8, 8))
plt.scatter(X[0, :], X[1, :], c=current_output,
lw=.3, s=3, cmap=plt.cm.cool, vmin=0, vmax=1)
plt.axis([-6, 6, -6, 6])
plt.title('Cost: {:.3f}, Accuracy: {:.3f}'.format(float(current_cost), accuracy))
plt.show()
iteration += 1(译者注:注意观察Accurary不是单调上升的,cost也不是单调下降的!)
1
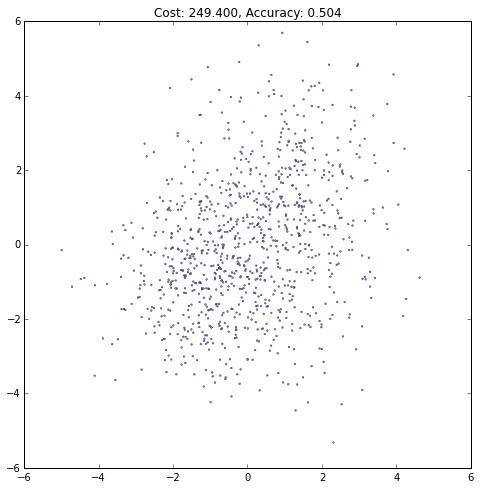
2
3
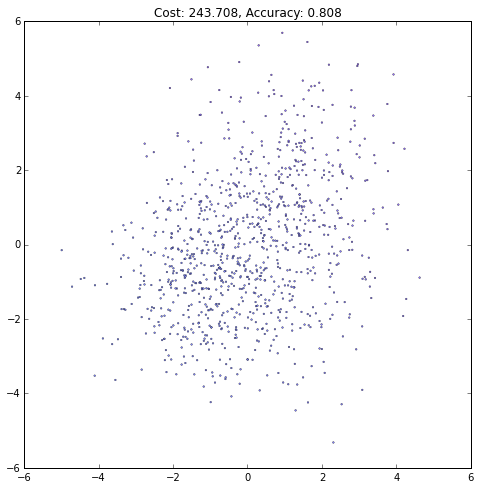
4

5

6

7

8

9

10

11
12

13
14
15
16
17
18
19
20















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









