






使用搜索HTML索引器
译者:老葛 Eskalate科技公司
索引器的目标是更有效的搜索大量的HTML内容。通过运行http://example.com/cron.php(一般使用一个周期性的cron调用)处理内容来实现这一目标的。因此,从提交新内容以后,到新内容可被搜索到,基于cron运行周期的长短,会有一个时差。索引器解析数据并对文本进行切分成词语 (成为分词),基于一组规则集为每个令牌(token)分配一个分数,可以使用搜索API扩展这一规则集。它接着将这些数据保存到数据库中,而当请求一个搜索时,它将使用这些索引过的表来代替直接使用节点表。
什么时候使用索引器
当搜索引擎评价大量的数据集时,而且当你的处理要求比标准的“最多词语匹配”查询更多时,一般需要使用索引器。当文件或者其它资源中的文本不是默认的格式时,索引器也用来从这些文本中提取和组织元数据。搜索相关度,指的是使用一组规则(通常很复杂)对内容进行处理来决定一个索引的匹配等级值。
如果你需要对大量的HTML内容进行搜索时,你将需要利用索引器的能力。Drupal中的最大优点之一就是,日志、论坛、页面等等都是节点。它们的基本数据结构是相同的,而这一联结也意味着它们的基本功能也一样。一个通用的特性就是当启用了搜索模块后将自动对所有的节点进行索引;而不需要额外的编程工作。即便是你创建了一个定制的节点类型,Drupal也会自动对该内容进行搜索。
索引器的工作原理
索引器有一个预处理模式,在该模式下将使用一组规则对文本进行过来从而指定分数。这些规则包括:处理缩略语、URLs、和数字数据。在于处理阶段,其它模块还有机会向该流程中添加逻辑,从而进行它们自己的数据操作。在针对特定语言调整期间,这非常方便,如下所示,这里我们使用了第3方模块Porter-Stemmer:
resumé ➤ resume (accent removal)
skipping ➤ skip (stemming)
skips ➤ skip (stemming)
其他的这样针对语言预处理的例子有是,为了保证文本被正确索引对汉语、日语、和韩语所进行的切词。
提示 Porter-Stemmer模块(http://drupal.org/project/porterstemmer)是一个模块例子,它用来提供词根服务从而提高英语搜索的。同样,汉语切词模块(http://drupal.org/project/csplitter)是一个加强版的预处理器,用来汉语、日语、和韩语的搜索。在搜索模块中包含了一个简单的汉语切词器,可以在搜索设置页面启用它。
预处理阶段过后,索引器使用HTML标签来寻找更重要的字词(称为令牌(tokens)),基于默认的HTML标签分数和每个令牌出现的次数来分给它们适当的分数。下面是全部的默认HTML标签分数列表(在search_index()中定义的它们):
<h1> = 25
<h2> = 18
<h3> = 15
<h4> = 12
<a> = 10
<h5> = 9
<h6> = 6
<b> = 3
<strong> = 3
<i> = 3
<em> = 3
<u> = 3
让我们摘取一段HTML,然后使用索引器对其处理,从而更好的理解索引器的工作原理。图12-6展示了HTML索引器的概貌:解析内容,为令牌分配分数,将信息存储在数据库中。

图12-6 对一段HTML进行索引并分配分数
当索引器遇到一个由标点符号分隔的数字数据时,它将删除标点符号并只对数字进行索引。这意味着数字元素比如日期、版本号、IP地址等等将会更容易搜索到。图12-6中的中间步骤展示了如何对一个没有使用HTML标签的单词令牌(token)进行处理的。这些令牌的重量为1.最后一行展示了使用强调标签<em>的内容。决定一个令牌总分的公式如下:
匹配数量 * HTML标签重量
还需要注意的是Drupal对节点过滤后的输出进行索引;例如,如果你有一个输入过滤器,它将URL自动转化为了超链接,或者其它的过滤器将换行转化为了HTML的<br/>和<p>标签,索引器将看到这些带有标签的内容,并会根据这些标签分配分数。你可能知道Drupal内部有一个可选的PHP代码输入过滤器,在一个使用了该过滤器的节点中,可以看到对过滤后的内容进行索引所产生的效果会更加明显。索引动态内容应该非常麻烦,但是由于Drupal的索引器只看到PHP节点的输出,所以动态PHP节点将自动被索引。
当索引器遇到内部链接时,它也将以一种特定方式对它们进行处理。如果一个链接指向了另一个节点,那么连接中的词语将被添加到目标节点的内容中,这使得能够更容易的搜索到常见问题的答案和相关信息。有两种方式能够钩住索引器:
• 为了调整搜索的相关性,你可以向节点中添加在视图中不可见的数据。你可以在Drupal内核中看到这方面的实例,对于分类词语和评论,从技术上讲它们不是节点你对象的一部份,但它们对搜索结果有影响。在索引阶段使用nodeapi('update index')钩子将这些项目添加到节点中。当仅仅处理节点时你可以再次调用hook_nodeapi()。
• 通过hook_update_index(),你可以使用索引器对不属于节点的HTML内容进行索引。Drupal内核中hook_update_index()的实现,参看modules/node/node.module中的node_update_index()。
在cron运行期间,为了索引新的数据,将会调用这两个钩子。图12-7展示了这些钩子的运行次序。
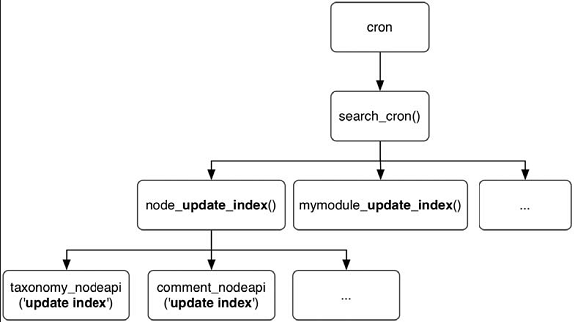
图12-7 HTML索引钩子的概貌
我们将在接下来的部分更详细的讨论这些钩子
向节点添加元数据:nodeapi('update index')
当Drupal为了快速搜索对节点进行索引时,它首先使用node_view()来运行节点对象,从而生成与你在你的浏览器中看的完全一样的输出。这就意味着节点中任何可视的部分都将被索引。例如,假定我们有一个节点,它的ID为26。党察看URL http://example.com/?q=node/26时可见得节点部分也都将被索引器看到。
如果我们有一个定制的节点类型,它包含隐藏的数据,而这些数据对搜索结果有影响,那该怎么办呢?在book.module中有个很好的现成的例子,我们看看它是怎么处理这一点的。我们可以对章节标题和子页面一同索引来提高这些子页面的相关度。
注意 钩子nodeapi仅用来向节点追加元数据。为了对不是节点的元素进行索引,需要使用hook_update_index()。
function book_boost_nodeapi($node, $op, $arg = 0) {
switch ($op) {
case 'update index':
// Book nodes have a parent attribute.
if ($node->parent) {
$parent = node_load($node->parent);
// Boost relevancy by using h2 tags.
return '<h2>'. $parent->title .'</h2>';
}
}
}
注意,我们在这里对标题使用了HTML<h2>标签进行封装,从而告诉索引器为这一文本分配一个相对较高的分数。















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









