






问题描述:
判断一段文字(原串长为n)里面是不是存在那么一些……特殊……的文字(模式串长为m)?
暴力方法:
在原串的每个位置都用模式串从头开始匹配,复杂度为O(n*m);
KMP 算法:
首先这个算法的复杂为预处理时间
Θ
(m), 匹配复杂度为
Θ
(n)
其实KMP 并不是效率最高的算法,目前编辑器中使用的算法是Boyer–Moore算法
,但是KMP算法代码更简洁。
首先用一副图说明KMP算法的思路
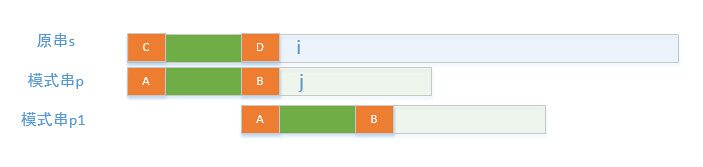
原串s 和 模式串p 进行匹配,当匹配到s[i] 和 p[j] 时发现 s[i]
≠
p[j], 此时模式串p 应该怎么移动继续进行匹配,暴力方法是将模式串p 的头移动到原串s 的第二个字符处,再开始比较。这样做其实是有浪费的,现在我们已经知道 s[1] ~s[i-1] = p[1] ~p[j-1] 的, 暴力比较下一次是比较s[2] ? p[1], 而 s[2] = p[2] 所以只用比较p[2] ? p[1], 如果我们对模式串p进行了预处理就知道p[2] 和p[1] 的关系,从而这次比较就可以避免,同理后面直到和s[i] 之前的比较都是可以再预处理中求得的,那么我们就可以通过预处理知道接下来模式串p应该怎么移动。KMP算法就是这样做的,首先会计算一个next数组。在匹配是如果s[i]
≠
p[j], then j = next[j]; next 数组的含义如图中橙色串所示,橙色部分表示完全相同的字符串,且串A和串B是当前位置j 时 的最长的。next[j] = 串A尾部的下一个位置。下次比较是模式串会移动到模式串p1的位置。下面证明这么移动是对的, 如下图所示如果模式串比p1 的位置稍微向前一点,且之前是匹配的
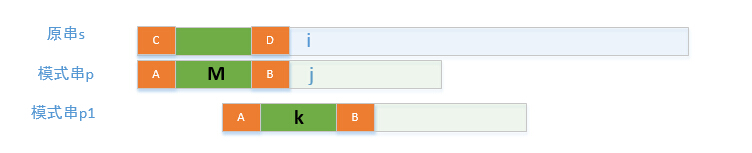
那么p[M] ~p[j-1] = p[1]~p[k-1] , p[1]~p[k-1] 是一个比A长且满足串A 和串B 关系的,这与串A和串B是当前位置j 时 的最长的假设不符,因此不可能相等。
如果模式串再往后移,就可能漏掉一些答案.
next数组的求解过程,从前面已经知道next数组的含义是串A 的下一个位置。假设我们已经知道了next[1~k] 的值,要求next[k+1] 的值。如下图:
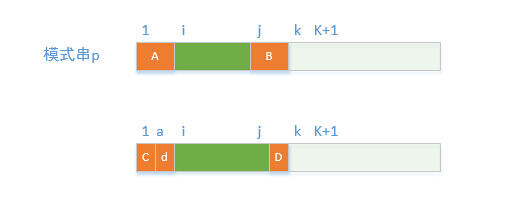
next[k] = i,串A = 串 B, 如果此时p[i] = p[k] 那么next[k+1] = i+1 = next[k]+1;
如果p[i]
≠
p[k],next[next[k]]= a 表示C = d, d = D(A=B)
所以C = D,此时只要p[a] = p[k] 则next[k+1] = next[next[k]] + 1;
如果p[a]
≠
p[k] ,我们需要寻找更小的串
…..
可以看出next数组可以使用递归求解。
代码实现:
1. next[0] = -1 这样可以简化代码实现。
2. 要求模式串长度+1 个next 值,因为如果找到一个答案后,依然可以借助next移动模式串,寻找下一个答案。
#include <cstring>
#include <cmath>
#include <cstdio>
using namespace std;
enum {maxn= 1000000+5};
char s[maxn];
char m[maxn];
int next[maxn];
void calNext()
{
next[0] = -1;
next[1] = 0;
int len = strlen(m);
for (int i=2; i<= len; i++)
{
int j = next[i-1];
while(j >= 0 && m[i-1] != m[j] ) j = next[j];
next[i] = j+1;
}
}
void find()
{
int ans = 0;
int j=0;
for (int i=0; s[i]; i++)
{
while(j >= 0 && m[j] != s[i] ) j = next[j];
j++;
if (!m[j])
{
ans ++;
j = next[j];
}
}
printf("%d\n", ans);
}
#define OJ
int main()
{
#ifndef OJ
freopen("in.txt", "r", stdin);
#endif // OJ
int n;
scanf("%d", &n);
while(n--){
scanf("%s", m);
scanf("%s", s);
calNext();
find();
}
return 0;
}















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









