




 本文深入探讨了关联分析中的Apriori算法与FP-growth算法,详细解析了这两种算法的原理与实现细节,并通过示例展示了如何使用Python进行频繁项集的挖掘。此外,还介绍了如何从新闻站点点击流中挖掘热门新闻报道。
本文深入探讨了关联分析中的Apriori算法与FP-growth算法,详细解析了这两种算法的原理与实现细节,并通过示例展示了如何使用Python进行频繁项集的挖掘。此外,还介绍了如何从新闻站点点击流中挖掘热门新闻报道。
=====================================================================
github 源码同步:https://github.com/Thinkgamer/Machine-Learning-With-Python
=====================================================================
1:关联分析
2:Apriori算法和FP-growth算法原理
3:使用Apriori算法发现频繁项集
4:使用FP-growth高效发现频繁项集
5:实例:从新闻站点点击流中挖掘新闻报道
以下程序用到的源代码下载地址:GitHub点击查看
一:关联分析
1:相关概念
关联分析(association analysis):从大规模数据集中寻找商品的隐含关系
项集 (itemset):包含0个或者多个项的集合称为项集
频繁项集:那些经常一起出现的物品集合
支持度计数(support count):一个项集出现的次数也就是整个交易数据集中包含该项集的事物数
关联规则是形如A->B的表达式,规则A->B的度量包括支持度和置信度
项集支持度:一个项集出现的次数与数据集所有事物数的百分比称为项集的支持度
eg:support(A->B)=support_count(A并B) / N
项集置信度(confidence):数据集中同时包含A,B的百分比
eg:confidence(A->B) = support_count(A并B) / support_count(A)
2:关联分析一些应用
(1):购物篮分析,通过查看那些商品经常在一起出售,可以帮助商店了解用户的购物行为,这种从数据的海洋中抽取只是可以用于商品定价、市场促销、存货管理等环节
(2):在Twitter源中发现一些公共词。对于给定的搜索词,发现推文中频繁出现的单词集合
(3):从新闻网站点击流中挖掘新闻流行趋势,挖掘哪些新闻广泛被用户浏览到
(4):搜索引擎推荐,在用户输入查询时推荐同时相关的查询词项
(5):发现毒蘑菇的相似特征。这里只对包含某个特征元素(有毒素)的项集感兴趣,从中寻找毒蘑菇中的一些公共特征,利用这些特征来避免迟到哪些有毒的蘑菇
3:样例(下文分析所依据的样本,交易数据表)
| 交易号码 | 商品 |
| 100 | Cola,Egg,Ham |
| 200 | Cola,Diaper,Beer |
| 300 | Cola,Diaper,Beer,Ham |
| 400 | Diaper,Beer |
二:Apriori算法和FP-growth算法原理
1:Apriori算法原理
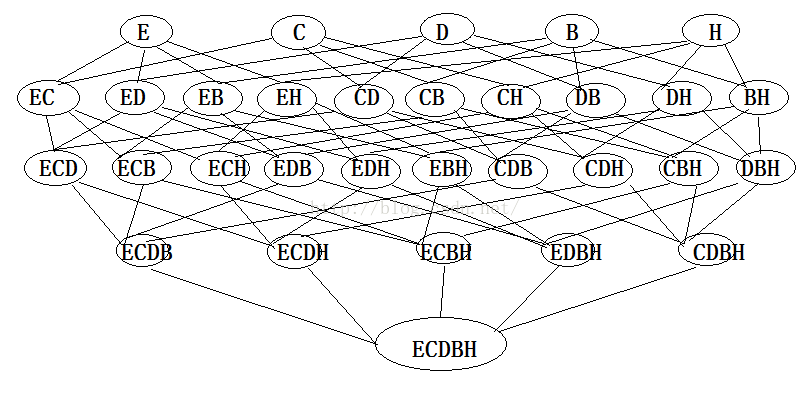
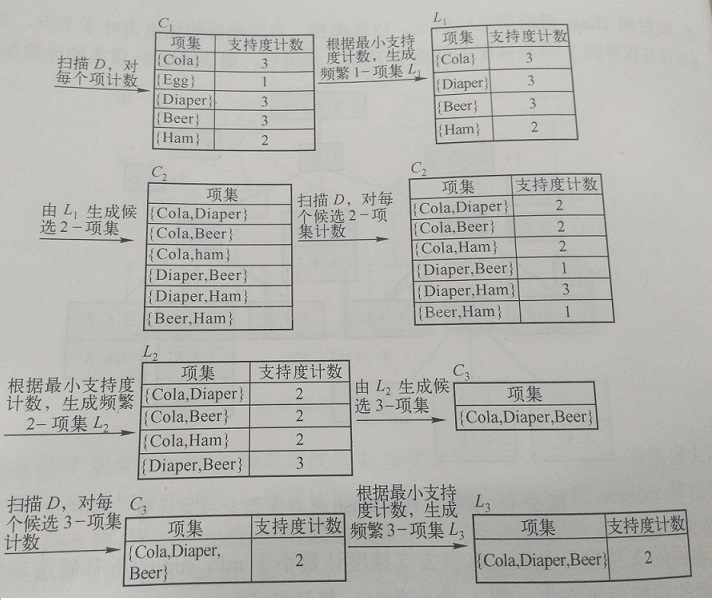
2:FP-growth算法原理
| 交易号码 | 商品 |
| 100 | Cola,Egg,Ham |
| 200 | Cola,Diaper,Beer |
| 300 | Cola,Diaper,Beer,Ham |
| 400 | Diaper,Beer |
三:使用Apriori算法发现频繁项集和挖掘相关规则
1:发现频繁项集
#-*-coding:utf-8-*-
'''
Created on 2016年5月8日
@author: Gamer Think
'''
from pydoc import apropos
#========================= 准备函数 (下) ==========================================
#加载数据集
def loadDataSet():
return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
def createC1(dataSet):
C1 = [] #C1为大小为1的项的集合
for transaction in dataSet: #遍历数据集中的每一条交易
for item in transaction: #遍历每一条交易中的每个商品
if not [item] in C1:
C1.append([item])
C1.sort()
#map函数表示遍历C1中的每一个元素执行forzenset,frozenset表示“冰冻”的集合,即不可改变
return map(frozenset,C1)
#Ck表示数据集,D表示候选集合的列表,minSupport表示最小支持度
#该函数用于从C1生成L1,L1表示满足最低支持度的元素集合
def scanD(D,Ck,minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
#issubset:表示如果集合can中的每一元素都在tid中则返回true
if can.issubset(tid):
#统计各个集合scan出现的次数,存入ssCnt字典中,字典的key是集合,value是统计出现的次数
if not ssCnt.has_key(can):
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
#计算每个项集的支持度,如果满足条件则把该项集加入到retList列表中
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0, key)
#构建支持的项集的字典
supportData[key] = support
return retList,supportData
#==================== 准备函数(上) =============================
#====================== Apriori算法(下) =================================
#Create Ck,CaprioriGen ()的输人参数为频繁项集列表Lk与项集元素个数k,输出为Ck
def aprioriGen(Lk,k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1,lenLk):
#前k-2项相同时合并两个集合
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2]
L1.sort()
L2.sort()
if L1 == L2:
retList.append(Lk[i] | Lk[j])
return retList
def apriori(dataSet, minSupport=0.5):
C1 = createC1(dataSet) #创建C1
#D: [set([1, 3, 4]), set([2, 3, 5]), set([1, 2, 3, 5]), set([2, 5])]
D = map(set,dataSet)
L1,supportData = scanD(D, C1, minSupport)
L = [L1]
#若两个项集的长度为k - 1,则必须前k-2项相同才可连接,即求并集,所以[:k-2]的实际作用为取列表的前k-1个元素
k = 2
while(len(L[k-2]) > 0):
Ck = aprioriGen(L[k-2], k)
Lk,supK = scanD(D,Ck, minSupport)
supportData.update(supK)
L.append(Lk)
k +=1
return L,supportData
#====================== Apriori算法(上) =================================
if __name__=="__main__":
dataSet = loadDataSet()
L,suppData = apriori(dataSet)
i = 0
for one in L:
print "项数为 %s 的频繁项集:" % (i + 1), one,"\n"
i +=1
|

2:挖掘相关规则
前文也提到过,一条规则P➞H的可信度定义为support(P 并 H)/support(P)。可见可信度的计算是基于项集的支持度的。
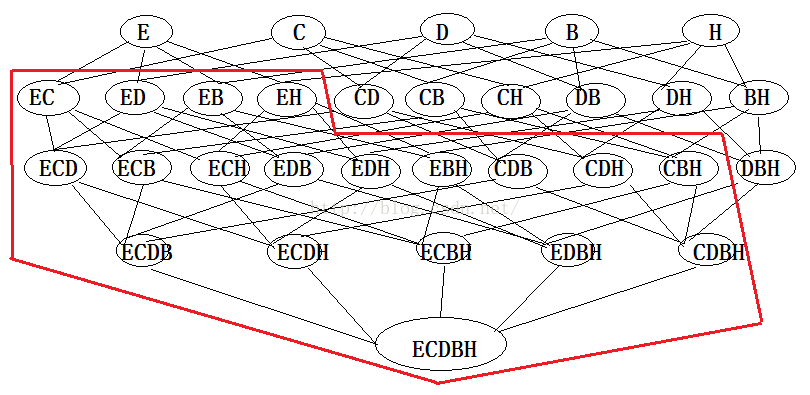
下图给出了从项集{0,1,2,3}产生的所有关联规则,其中阴影区域给出的是低可信度的规则。可以发现如果{0,1,2}➞{3}是一条低可信度规则,那么所有其他以3作为后件(箭头右部包含3)的规则均为低可信度的。

频繁项集{0,1,2,3}的关联规则网格示意图
可以观察到,如果某条规则并不满足最小可信度要求,那么该规则的所有子集也不会满足最小可信度要求。以图4为例,假设规则{0,1,2} ➞ {3}并不满足最小可信度要求,那么就知道任何左部为{0,1,2}子集的规则也不会满足最小可信度要求。可以利用关联规则的上述性质属性来减少需要测试的规则数目,类似于Apriori算法求解频繁项集。
关联规则生成函数:
def generateRules(L, supportData, minConf=0.7):
bigRuleList = []
for i in range(1, len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
# 三个及以上元素的集合
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
# 两个元素的集合
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
|
这个函数是主函数,调用其他两个函数。其他两个函数是rulesFromConseq()和calcConf(),分别用于生成候选规则集合以及对规则进行评估(计算支持度)。
函数generateRules()有3个参数:频繁项集列表L、包含那些频繁项集支持数据的字典supportData、最小可信度阈值minConf。函数最后要生成一个包含可信度的规则列表bigRuleList,后面可以基于可信度对它们进行排序。L和supportData正好为函数apriori()的输出。该函数遍历L中的每一个频繁项集,并对每个频繁项集构建只包含单个元素集合的列表H1。代码中的i指示当前遍历的频繁项集包含的元素个数,freqSet为当前遍历的频繁项集(回忆L的组织结构是先把具有相同元素个数的频繁项集组织成列表,再将各个列表组成一个大列表,所以为遍历L中的频繁项集,需要使用两层for循环)。
辅助函数——计算规则的可信度,并过滤出满足最小可信度要求的规则
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
''' 对候选规则集进行评估 '''
prunedH = []
for conseq in H:
conf = supportData[freqSet] / supportData[freqSet - conseq]
if conf >= minConf:
print freqSet - conseq, '-->', conseq, 'conf:', conf
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
|
计算规则的可信度以及找出满足最小可信度要求的规则。函数返回一个满足最小可信度要求的规则列表,并将这个规则列表添加到主函数的bigRuleList中(通过参数brl)。返回值prunedH保存规则列表的右部,这个值将在下一个函数rulesFromConseq()中用到。
辅助函数——根据当前候选规则集H生成下一层候选规则集
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
''' 生成候选规则集 '''
m = len(H[0])
if (len(freqSet) > (m + 1)):
Hmpl = aprioriGen(H, m + 1)
Hmpl = calcConf(freqSet, Hmpl, supportData, brl, minConf)
if (len(Hmpl) > 1):
rulesFromConseq(freqSet, Hmpl, supportData, brl, minConf)
|
从最初的项集中生成更多的关联规则。该函数有两个参数:频繁项集freqSet,可以出现在规则右部的元素列表H。其余参数:supportData保存项集的支持度,brl保存生成的关联规则,minConf同主函数。函数先计算H中的频繁项集大小m。接下来查看该频繁项集是否大到可以移除大小为m的子集。如果可以的话,则将其移除。使用函数aprioriGen()来生成H中元素的无重复组合,结果保存在Hmp1中,这也是下一次迭代的H列表。
|
if __name__=="__main__":
dataSet = loadDataSet()
L,suppData = apriori(dataSet)
i = 0
for one in L:
print "项数为 %s 的频繁项集:" % (i + 1), one,"\n"
i +=1
print "minConf=0.7时:"
rules = generateRules(L,suppData, minConf=0.7)
print "\nminConf=0.5时:"
rules = generateRules(L,suppData, minConf=0.5)
|

如果仔细看下上述代码和输出,会发现这里面是一些问题的。
1 问题的提出
频繁项集L的值前面提到过。我们在其中计算通过{2, 3, 5}生成的关联规则,可以发现关联规则{3, 5}➞{2}和{2, 3}➞{5}的可信度都应该为1.0的,因而也应该包括在当minConf = 0.7时的rules中——但是这在前面的运行结果中并没有体现出来。minConf = 0.5时也是一样,{3, 5}➞{2}的可信度为1.0,{2, 5}➞{3}的可信度为2/3,{2, 3}➞{5}的可信度为1.0,也没有体现在rules中。
通过分析程序代码,我们可以发现:
- 当i = 1时,generateRules()函数直接调用了calcConf()函数直接计算其可信度,因为这时L[1]中的频繁项集均包含两个元素,可以直接生成和判断候选关联规则。比如L[1]中的{2, 3},生成的候选关联规则为{2}➞{3}、{3}➞{2},这样就可以了。
- 当i > 1时,generateRules()函数调用了rulesFromConseq()函数,这时L[i]中至少包含3个元素,如{2, 3, 5},对候选关联规则的生成和判断的过程需要分层进行(图4)。这里,将初始的H1(表示初始关联规则的右部,即箭头右边的部分)作为参数传递给了rulesFromConseq()函数。
例如,对于频繁项集{a, b, c, …},H1的值为[a, b, c, …](代码中实际为frozenset类型)。如果将H1带入计算可信度的calcConf()函数,在函数中会依次计算关联规则{b, c, d, …}➞{a}、{a, c, d, …}➞{b}、{a, b, d, …}➞{c}……的支持度,并保存支持度大于最小支持度的关联规则,并保存这些规则的右部(prunedH,即对H的过滤,删除支持度过小的关联规则)。
当i > 1时没有直接调用calcConf()函数计算通过H1生成的规则集。在rulesFromConseq()函数中,首先获得当前H的元素数m = len(H[0])(记当前的H为Hm )。当Hm可以进一步合并为m+1元素数的集合Hm+1时(判断条件:len(freqSet) > (m + 1)),依次:
- 生成Hm+1:Hmpl = aprioriGen(H, m + 1)
- 计算Hm+1的可信度:Hmpl = calcConf(freqSet, Hmpl, …)
- 递归计算由Hm+1生成的关联规则:rulesFromConseq(freqSet, Hmpl, …)
所以这里的问题是,在i>1时,rulesFromConseq()函数中并没有调用calcConf()函数计算H1的可信度,而是直接由H1生成H2,从H2开始计算关联规则——于是由元素数>3的频繁项集生成的{a, b, c, …}➞{x}形式的关联规则(图4中的第2层)均缺失了。由于代码示例数据中的对H1的剪枝prunedH没有删除任何元素,结果只是“巧合”地缺失了一层。正常情况下如果没有对H1进行过滤,直接生成H2,将给下一层带入错误的结果(如图4中的012➞3会被错误得留下来)。
在i>1时,将对H1调用calcConf()的过程加上就可以了。比如可以这样:
def generateRules2(L, supportData, minConf=0.7):
bigRuleList = []
for i in range(1, len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
# 三个及以上元素的集合
H1 = calcConf(freqSet, H1, supportData, bigRuleList, minConf)
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
# 两个元素的集合
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
|
这里就只需要修改generateRules()函数。这样实际运行效果中,刚才丢失的那几个关联规则就都出来了。
进一步修改:当i=1时的else部分并没有独特的逻辑,这个if语句可以合并,然后再修改rulesFromConseq()函数,保证其会调用calcConf(freqSet, H1, …):
def generateRules3(L, supportData, minConf=0.7):
bigRuleList = []
for i in range(1, len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
rulesFromConseq2(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def rulesFromConseq2(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > m): # 判断长度改为 > m,这时即可以求H的可信度
Hmpl = calcConf(freqSet, H, supportData, brl, minConf)
if (len(Hmpl) > 1): # 判断求完可信度后是否还有可信度大于阈值的项用来生成下一层H
Hmpl = aprioriGen(Hmpl, m + 1)
rulesFromConseq2(freqSet, Hmpl, supportData, brl, minConf) # 递归计算,不变
|
运行结果和generateRules2相同。
进一步修改:消除rulesFromConseq2()函数中的递归项。这个递归纯粹是偷懒的结果,没有简化任何逻辑和增加任何可读性,可以直接用一个循环代替:
def rulesFromConseq3(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
while (len(freqSet) > m): # 判断长度 > m,这时即可求H的可信度
H = calcConf(freqSet, H, supportData, brl, minConf)
if (len(H) > 1): # 判断求完可信度后是否还有可信度大于阈值的项用来生成下一层H
H = aprioriGen(H, m + 1)
m += 1
else: # 不能继续生成下一层候选关联规则,提前退出循环
break
|
另一个主要的区别是去掉了多余的Hmpl变量。运行的结果和generateRules2相同。
此为修改后的运行结果:

至此,一个完整的Apriori算法就完成了。
Apriori算法总结:
关联分析是用于发现大数据集中元素间有趣关系的一个工具集,可以采用两种方式来量化这些有趣的关系。第一种方式是使用频繁项集,它会给出经常在一起出现的元素项。第二种方式是关联规则,每条关联规则意味着元素项之间的“如果……那么”关系。
发现元素项间不同的组合是个十分耗时的任务,不可避免需要大量昂贵的计算资源,这就需要一些更智能的方法在合理的时间范围内找到频繁项集。能够实现这一目标的一个方法是Apriori算法,它使用Apriori原理来减少在数据库上进行检查的集合的数目。Apriori原理是说如果一个元素项是不频繁的,那么那些包含该元素的超集也是不频繁的。Apriori算法从单元素项集开始,通过组合满足最小支持度要求的项集来形成更大的集合。支持度用来度量一个集合在原始数据中出现的频率。
关联分析可以用在许多不同物品上。商店中的商品以及网站的访问页面是其中比较常见的例子。
每次增加频繁项集的大小,Apriori算法都会重新扫描整个数据集。当数据集很大时,这会显著降低频繁项集发现的速度。下面会介绍FP-growth算法,和Apriori算法相比,该算法只需要对数据库进行两次遍历,能够显著加快发现频繁项集的速度。
四:使用FP-growth高效发现频繁项集
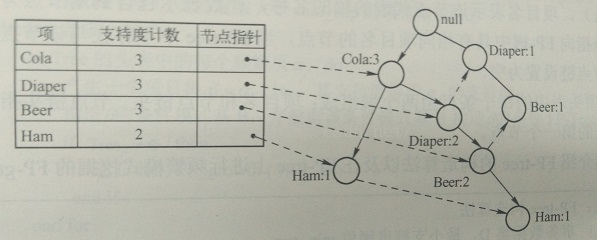
(拿书中的数据举例)FP-growth算法将数据存储在一种称为FP树的紧凑数据结构中。FP代表频繁模式(Frequent Pattern)。一棵FP树看上去与计算机科学中的其他树结构类似,但是它通过链接(link)来连接相似元素,被连起来的元素项可以看成一个链表。图5给出了FP树的一个例子。
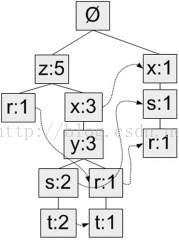
上图为 一棵FP树,和一般的树结构类似,包含着连接相似节点(值相同的节点)的连接
与搜索树不同的是,一个元素项可以在一棵FP树种出现多次。FP树辉存储项集的出现频率,而每个项集会以路径的方式存储在数中。存在相似元素的集合会共享树的一部分。只有当集合之间完全不同时,树才会分叉。 树节点上给出集合中的单个元素及其在序列中的出现次数,路径会给出该序列的出现次数。
相似项之间的链接称为节点链接(node link),用于快速发现相似项的位置。
举例说明,下表用来产生图5的FP树:
| 事务ID | 事务中的元素项 |
| 001 | r, z, h, j, p |
| 002 | z, y, x, w, v, u, t, s |
| 003 | z |
| 004 | r, x, n, o, s |
| 005 | y, r, x, z, q, t, p |
| 006 | y, z, x, e, q, s, t, m |
对FP树的解读:
图5中,元素项z出现了5次,集合{r, z}出现了1次。于是可以得出结论:z一定是自己本身或者和其他符号一起出现了4次。集合{t, s, y, x, z}出现了2次,集合{t, r, y, x, z}出现了1次,z本身单独出现1次。就像这样,FP树的解读方式是读取某个节点开始到根节点的路径。路径上的元素构成一个频繁项集,开始节点的值表示这个项集的支持度。根据图5,我们可以快速读出项集{z}的支持度为5、项集{t, s, y, x, z}的支持度为2、项集{r, y, x, z}的支持度为1、项集{r, s, x}的支持度为1。FP树中会多次出现相同的元素项,也是因为同一个元素项会存在于多条路径,构成多个频繁项集。但是频繁项集的共享路径是会合并的,如图中的{t, s, y, x, z}和{t, r, y, x, z}
和之前一样,我们取一个最小阈值,出现次数低于最小阈值的元素项将被直接忽略。图5中将最小支持度设为3,所以q和p没有在FP中出现。
FP-growth算法的工作流程如下。首先构建FP树,然后利用它来挖掘频繁项集。为构建FP树,需要对原始数据集扫描两遍。第一遍对所有元素项的出现次数进行计数。数据库的第一遍扫描用来统计出现的频率,而第二遍扫描中只考虑那些频繁元素。
1:创建FP树的数据结构
由于树节点的结构比较复杂,我们使用一个类表示。创建文件fpGrowth.py并加入下列代码:
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print ' ' * ind, self.name, ' ', self.count
for child in self.children.values():
child.disp(ind + 1)
|
每个树节点由五个数据项组成:
- name:节点元素名称,在构造时初始化为给定值
- count:出现次数,在构造时初始化为给定值
- nodeLink:指向下一个相似节点的指针,默认为None
- parent:指向父节点的指针,在构造时初始化为给定值
- children:指向子节点的字典,以子节点的元素名称为键,指向子节点的指针为值,初始化为空字典
成员函数:
- inc():增加节点的出现次数值
- disp():输出节点和子节点的FP树结构
测试代码:
>>>import fpGrowth
>>> rootNode = fpGrowth.treeNode('pyramid', 9, None)
>>> rootNode.children['eye'] = fpGrowth.treeNode('eye', 13, None)
>>> rootNode.children['phoenix'] = fpGrowth.treeNode('phoenix', 3, None)
>>> rootNode.disp()
|
2:构建FP树
头指针表
FP-growth算法还需要一个称为头指针表的数据结构,其实很简单,就是用来记录各个元素项的总出现次数的数组,再附带一个指针指向FP树中该元素项的第一个节点。这样每个元素项都构成一条单链表。图示说明:
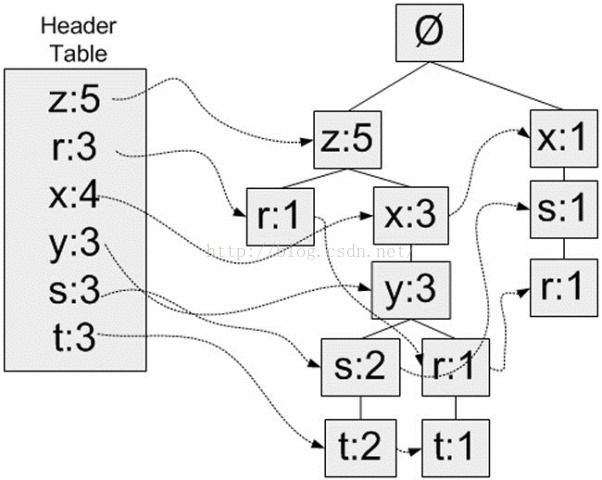
这里使用Python字典作为数据结构,来保存头指针表。以元素项名称为键,保存出现的总次数和一个指向第一个相似元素项的指针。
第一次遍历数据集会获得每个元素项的出现频率,去掉不满足最小支持度的元素项,生成这个头指针表。
元素项排序
上文提到过,FP树会合并相同的频繁项集(或相同的部分)。因此为判断两个项集的相似程度需要对项集中的元素进行排序(不过原因也不仅如此,还有其它好处)。排序基于元素项的绝对出现频率(总的出现次数)来进行。在第二次遍历数据集时,会读入每个项集(读取),去掉不满足最小支持度的元素项(过滤),然后对元素进行排序(重排序)。
对示例数据集进行过滤和重排序的结果如下:
| 事务ID | 事务中的元素项 | 过滤及重排序后的事务 |
| 001 | r, z, h, j, p | z, r |
| 002 | z, y, x, w, v, u, t, s | z, x, y, s, t |
| 003 | z | z |
| 004 | r, x, n, o, s | x, s, r |
| 005 | y, r, x, z, q, t, p | z, x, y, r, t |
| 006 | y, z, x, e, q, s, t, m | z, x, y, s, t |
构建FP树
在对事务记录过滤和排序之后,就可以构建FP树了。从空集开始,将过滤和重排序后的频繁项集一次添加到树中。如果树中已存在现有元素,则增加现有元素的值;如果现有元素不存在,则向树添加一个分支。对前两条事务进行添加的过程:
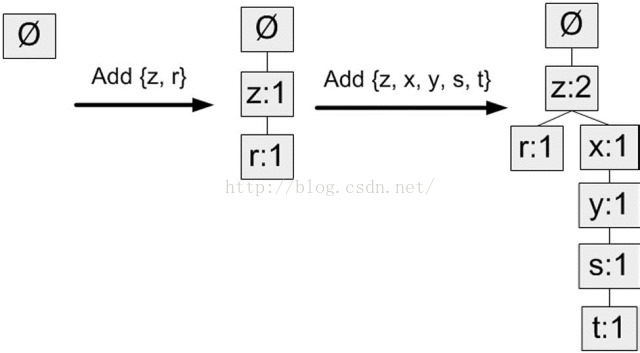
算法:构建FP树
输入:数据集、最小值尺度
输出:FP树、头指针表
1. 遍历数据集,统计各元素项出现次数,创建头指针表
2. 移除头指针表中不满足最小值尺度的元素项
3. 第二次遍历数据集,创建FP树。对每个数据集中的项集:
3.1 初始化空FP树
3.2 对每个项集进行过滤和重排序
3.3 使用这个项集更新FP树,从FP树的根节点开始:
3.3.1 如果当前项集的第一个元素项存在于FP树当前节点的子节点中,则更新这个子节点的计数值
3.3.2 否则,创建新的子节点,更新头指针表
3.3.3 对当前项集的其余元素项和当前元素项的对应子节点递归3.3的过程
代码(在fpGrowth.py中加入下面的代码):
1: 总函数:createTree
def createTree(dataSet, minSup=1):
''' 创建FP树 '''
# 第一次遍历数据集,创建头指针表
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
# 移除不满足最小支持度的元素项
for k in headerTable.keys():
if headerTable[k] < minSup:
del(headerTable[k])
# 空元素集,返回空
freqItemSet = set(headerTable.keys())
if len(freqItemSet) == 0:
return None, None
# 增加一个数据项,用于存放指向相似元素项指针
for k in headerTable:
headerTable[k] = [headerTable[k], None]
retTree = treeNode('Null Set', 1, None) # 根节点
# 第二次遍历数据集,创建FP树
for tranSet, count in dataSet.items():
localD = {} # 对一个项集tranSet,记录其中每个元素项的全局频率,用于排序
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0] # 注意这个[0],因为之前加过一个数据项
if len(localD) > 0:
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)] # 排序
updateTree(orderedItems, retTree, headerTable, count) # 更新FP树
return retTree, headerTable
|
(代码比较宽,大家的显示器都那么大,应该没关系吧……)
需要注意的是,参数中的dataSet的格式比较奇特,不是直觉上得集合的list,而是一个集合的字典,以这个集合为键,值部分记录的是这个集合出现的次数。于是要生成这个dataSet还需要后面的createInitSet()函数辅助。因此代码中第7行中的dataSet[trans]实际获得了这个trans集合的出现次数(在本例中均为1),同样第21行的“for tranSet, count in dataSet.items():”获得了tranSet和count分别表示一个项集和该项集的出现次数。——这样做是为了适应后面在挖掘频繁项集时生成的条件FP树。
2:辅助函数:updateTree
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children:
# 有该元素项时计数值+1
inTree.children[items[0]].inc(count)
else:
# 没有这个元素项时创建一个新节点
inTree.children[items[0]] = treeNode(items[0], count, inTree)
# 更新头指针表或前一个相似元素项节点的指针指向新节点
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1:
# 对剩下的元素项迭代调用updateTree函数
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
|
3: 辅助函数:updateHeader
def updateHeader(nodeToTest, targetNode):
while (nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
|
这个函数其实只做了一件事,就是获取头指针表中该元素项对应的单链表的尾节点,然后将其指向新节点targetNode。
生成数据集
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict
|
生成的样例数据同文中用得一样。这个诡异的输入格式就是createInitSet()函数中这样来得。
测试代码
>>> import fpGrowth
>>> simpDat = fpGrowth.loadSimpDat()
>>> initSet = fpGrowth.createInitSet(simpDat)
>>> myFPtree, myHeaderTab = fpGrowth.createTree(initSet, 3)
>>> myFPtree.disp()
|
结果是这样的(连字都懒得打了,直接截图……):

得到的FP树也和图5中的一样。
3:从一棵FP树中挖掘频繁项集
从FP树中抽取频繁项集的三个基本步骤如下:
- 从FP树中获得条件模式基;
- 利用条件模式基,构建一个条件FP树;
- 迭代重复步骤1步骤2,直到树包含一个元素项为止。
1 抽取条件模式基
(什么鬼……)
首先从头指针表中的每个频繁元素项开始,对每个元素项,获得其对应的条件模式基(conditional pattern base)。条件模式基是以所查找元素项为结尾的路径集合。每一条路径其实都是一条前缀路径(prefix path)。简而言之,一条前缀路径是介于所查找元素项与树根节点之间的所有内容。
将图5重新贴在这里:
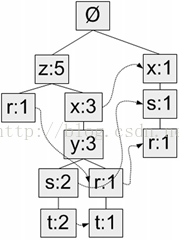
则每一个频繁元素项的所有前缀路径(条件模式基)为:
| 频繁项 | 前缀路径 |
| z | {}: 5 |
| r | {x, s}: 1, {z, x, y}: 1, {z}: 1 |
| x | {z}: 3, {}: 1 |
| y | {z, x}: 3 |
| s | {z, x, y}: 2, {x}: 1 |
| t | {z, x, y, s}: 2, {z, x, y, r}: 1 |
发现规律了吗,z存在于路径{z}中,因此前缀路径为空,另添加一项该路径中z节点的计数值5构成其条件模式基;r存在于路径{r, z}、{r, y, x, z}、{r, s, x}中,分别获得前缀路径{z}、{y, x, z}、{s, x},另添加对应路径中r节点的计数值(均为1)构成r的条件模式基;以此类推。
前缀路径将在下一步中用于构建条件FP树,暂时先不考虑。如何发现某个频繁元素项的所在的路径?利用先前创建的头指针表和FP树中的相似元素节点指针,我们已经有了每个元素对应的单链表,因而可以直接获取。
下面的程序给出了创建前缀路径的代码:
1 主函数:findPrefixPath
def findPrefixPath(basePat, treeNode):
''' 创建前缀路径 '''
condPats = {}
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats
|
该函数代码用于为给定元素项生成一个条件模式基(前缀路径),这通过访问树中所有包含给定元素项的节点来完成。参数basePet表示输入的频繁项,treeNode为当前FP树种对应的第一个节点(可在函数外部通过headerTable[basePat][1]获取)。函数返回值即为条件模式基condPats,用一个字典表示,键为前缀路径,值为计数值。
2 辅助函数:ascendTree
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
|
这个函数直接修改prefixPath的值,将当前节点leafNode添加到prefixPath的末尾,然后递归添加其父节点。最终结果,prefixPath就是一条从treeNode(包括treeNode)到根节点(不包括根节点)的路径。在主函数findPrefixPath()中再取prefixPath[1:],即为treeNode的前缀路径。
测试代码:
>>> fpGrowth.findPrefixPath('x', myHeaderTab['x'][1])
>>> fpGrowth.findPrefixPath('z', myHeaderTab['z'][1])
>>> fpGrowth.findPrefixPath('r', myHeaderTab['r'][1])
|
2 创建条件FP树
(又是什么鬼……)
对于每一个频繁项,都要创建一棵条件FP树。可以使用刚才发现的条件模式基作为输入数据,并通过相同的建树代码来构建这些树。例如,对于r,即以“{x, s}: 1, {z, x, y}: 1, {z}: 1”为输入,调用函数createTree()获得r的条件FP树;对于t,输入是对应的条件模式基“{z, x, y, s}: 2, {z, x, y, r}: 1”。
代码(直接调用createTree()函数):
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
myCondTree, myHead = createTree(condPattBases, minSup)
|
示例:t的条件FP树
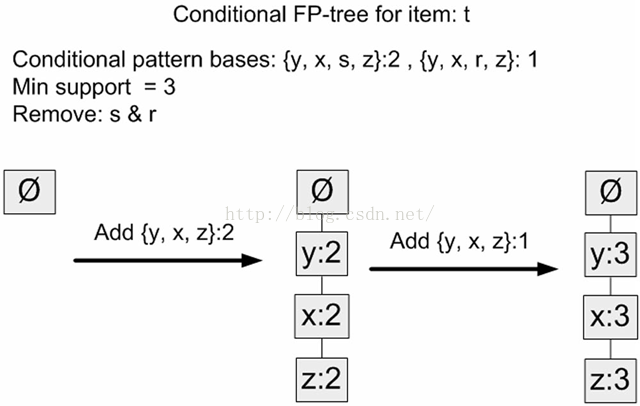
t的条件FP树的创建过程
在图8中,注意到元素项s以及r是条件模式基的一部分,但是它们并不属于条件FP树。因为在当前的输入中,s和r不满足最小支持度的条件。
3 递归查找频繁项集
有了FP树和条件FP树,我们就可以在前两步的基础上递归得查找频繁项集。
递归的过程是这样的:
输入:我们有当前数据集的FP树(inTree,headerTable)
1. 初始化一个空列表preFix表示前缀
2. 初始化一个空列表freqItemList接收生成的频繁项集(作为输出)
3. 对headerTable中的每个元素basePat(按计数值由小到大),递归:
3.1 记basePat + preFix为当前频繁项集newFreqSet
3.2 将newFreqSet添加到freqItemList中
3.3 计算t的条件FP树(myCondTree、myHead)
3.4 当条件FP树不为空时,继续下一步;否则退出递归
3.4 以myCondTree、myHead为新的输入,以newFreqSet为新的preFix,外加freqItemList,递归这个过程
函数如下:
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead != None:
# 用于测试
print 'conditional tree for:', newFreqSet
myCondTree.disp()
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
|
输入参数:
- inTree和headerTable是由createTree()函数生成的数据集的FP树
- minSup表示最小支持度
- preFix请传入一个空集合(set([])),将在函数中用于保存当前前缀
- freqItemList请传入一个空列表([]),将用来储存生成的频繁项集
测试代码:
>>> freqItems = []
>>> fpGrowth.mineTree(myFPtree, myHeaderTab, 3, set([]), freqItems)
>>> freqItems
|
[set(['y']), set(['y', 'x']), set(['y', 'z']), set(['y', 'x', 'z']), set(['s']), set(['x', 's']), set(['t']), set(['z', 't']), set(['x', 'z', 't']), set(['y', 'x', 'z', 't']), set(['y', 'z', 't']), set(['x', 't']), set(['y', 'x', 't']), set(['y', 't']), set(['r']), set(['x']), set(['x', 'z']), set(['z'])]
想这一段代码解释清楚比较难,因为中间涉及到很多递归。直接举例说明,我们在这里分解输入myFPtree和myHeaderTab后,“for basePat in bigL:”一行当basePat为’t’时的过程:
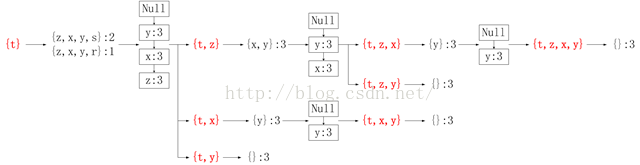
图9 mineTree函数解构图(basePat = ‘t’)
图中红色加粗的部分即实际添加到freqItemList中的频繁项集。
4 封装
至此,完整的FP-growth算法已经可以运行。封装整个过程如下:
def fpGrowth(dataSet, minSup=3):
initSet = createInitSet(dataSet)
myFPtree, myHeaderTab = createTree(initSet, minSup)
freqItems = []
mineTree(myFPtree, myHeaderTab, minSup, set([]), freqItems)
return freqItems
|
测试代码:
>>> import fpGrowth
>>> dataSet = fpGrowth.loadSimpDat()
>>> freqItems = fpGrowth.fpGrowth(dataSet)
>>> freqItems
|
和之前的输出相同。
5 总结
FP-growth算法是一种用于发现数据集中频繁模式的有效方法。FP-growth算法利用Apriori原则,执行更快。Apriori算法产生候选项集,然后扫描数据集来检查它们是否频繁。由于只对数据集扫描两次,因此FP-growth算法执行更快。在FP-growth算法中,数据集存储在一个称为FP树的结构中。FP树构建完成后,可以通过查找元素项的条件基及构建条件FP树来发现频繁项集。该过程不断以更多元素作为条件重复进行,直到FP树只包含一个元素为止。
FP-growth算法还有一个map-reduce版本的实现,它也很不错,可以扩展到多台机器上运行。Google使用该算法通过遍历大量文本来发现频繁共现词,其做法和我们刚才介绍的例子非常类似(参见扩展阅读:FP-growth算法)。
五:实例:从新闻站点点击流中挖掘新闻报道
书中的这两章有不少精彩的示例,这里只选取比较有代表性的一个——从新闻网站点击流中挖掘热门新闻报道。这是一个很大的数据集,有将近100万条记录(参见扩展阅读:kosarak)。在源数据集合保存在文件kosarak.dat(http://fimi.ua.ac.be/data/)中。该文件中的每一行包含某个用户浏览过的新闻报道。新闻报道被编码成整数,我们可以使用Apriori或FP-growth算法挖掘其中的频繁项集,查看那些新闻ID被用户大量观看到。
首先,将数据集导入到列表:
>>> parsedDat = [line.split() for line in open('kosarak.dat').readlines()]
|
接下来需要对初始集合格式化:
>>> import fpGrowth
>>> initSet = fpGrowth.createInitSet(parsedDat)
|
然后构建FP树,并从中寻找那些至少被10万人浏览过的新闻报道。
>>> myFPtree, myHeaderTab = fpGrowth.createTree(initSet, 100000)
|
下面创建一个空列表来保存这些频繁项集:
>>> myFreqList = []
>>> fpGrowth.mineTree(myFPtree, myHeaderTab, 100000, set([]), myFreqList)
|
接下来看下有多少新闻报道或报道集合曾经被10万或者更多的人浏览过:
>>> len(myFreqList)
|
9
总共有9个。下面看看都是那些:
>>> myFreqList
|
[set(['1']), set(['1', '6']), set(['3']), set(['11', '3']), set(['11', '3', '6']), set(['3', '6']), set(['11']), set(['11', '6']), set(['6'])]
至此Apriori算法和FP-Tree算法已经讲解分析完毕,当然我这里讲的有很多不足的地方,希望大家指正。































 到【灌水乐园】发言
到【灌水乐园】发言







