




http://blog.csdn.net/luckyxiaoqiang/article/details/7393134
1,链表节点定义
struct ListNode
{
int m_nKey;
ListNode * m_pNext;
};2,求单链表中结点的个数
// 求单链表中结点的个数
unsigned int GetListLength(ListNode * pHead)
{
if(pHead == NULL)
return 0;
unsigned int nLength = 0;
ListNode * pCurrent = pHead;
while(pCurrent != NULL)
{
nLength++;
pCurrent = pCurrent->m_pNext;
}
return nLength;
}3,单链表反转
http://blog.csdn.net/feliciafay/article/details/6841115
3.1 方法1:递归
Node * reverse(Node * head) {
if(head == null || head->next == null)
return head;
Node * ph = reverse(head->next);
head->next->next = head;
head->next = null;
return ph;
}3.2 方法2:非递归(原地倒置)
即用三个指针,倒转链表。
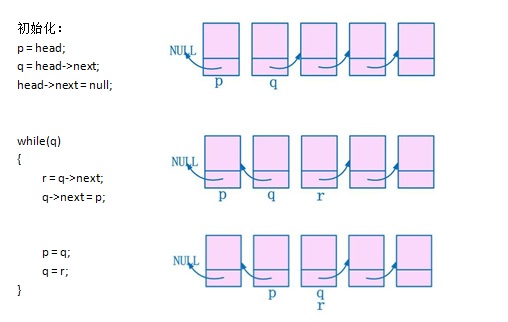
struct node{
int data;
node* next;
};
node* reverse(node* head)
{
if(head == null || head->next == null)
return head;
node *p,*q,*r;
p = head;
q = head->next;
head->next = null;
while(q)
{
r = q->next;
q->next = p;
p = q;
q = r;
}
head = p;
return head;
}3.3 方法3:非递归(新建插入)
// 反转单链表
ListNode * ReverseList(ListNode * pHead)
{
// 如果链表为空或只有一个结点,无需反转,直接返回原链表头指针
if(pHead == NULL || pHead->m_pNext == NULL)
return pHead;
ListNode * pReversedHead = NULL; // 反转后的新链表头指针,初始为NULL
ListNode * pCurrent = pHead;
while(pCurrent != NULL)
{
ListNode * pTemp = pCurrent;
pCurrent = pCurrent->m_pNext;
pTemp->m_pNext = pReversedHead; // 将当前结点摘下,插入新链表的最前端
pReversedHead = pTemp;
}
return pReversedHead;
}4,查找单链表中的倒数第K个结点(k > 0)
4.1 方法1:转换为正向n-k
4.2 方法2:双指针间隔k齐步走
主要思路就是使用两个指针,先让前面的指针走到正向第k个结点, 这样前后两个指针的距离差是k-1,之后前后两个指针一起向前走,前面的指针走到最后一个结点时,后面指针所指结点就是倒数第k个结点。// 查找单链表中倒数第K个结点
ListNode * RGetKthNode(ListNode * pHead, unsigned int k) // 函数名前面的R代表反向
{
if(k == 0 || pHead == NULL) // 这里k的计数是从1开始的,若k为0或链表为空返回NULL
return NULL;
ListNode * pAhead = pHead;
ListNode * pBehind = pHead;
while(k > 1 && pAhead != NULL) // 前面的指针先走到正向第k个结点
{
pAhead = pAhead->m_pNext;
k--;
}
if(pAhead == NULL) // 结点个数小于k,返回NULL
return NULL;
while(pAhead->m_pNext != NULL) // 前后两个指针一起向前走,直到前面的指针指向最后一个结点
{
pBehind = pBehind->m_pNext;
pAhead = pAhead->m_pNext;
}
return pBehind; // 后面的指针所指结点就是倒数第k个结点
}5,查找单链表的中间结点
// 获取单链表中间结点,若链表长度为n(n>0),则返回第n/2+1个结点
ListNode * GetMiddleNode(ListNode * pHead)
{
if(pHead == NULL || pHead->m_pNext == NULL) // 链表为空或只有一个结点,返回头指针
return pHead;
ListNode * pAhead = pHead;
ListNode * pBehind = pHead;
while(pAhead->m_pNext != NULL) // 前面指针每次走两步,直到指向最后一个结点,后面指针每次走一步
{
pAhead = pAhead->m_pNext;
pBehind = pBehind->m_pNext;
if(pAhead->m_pNext != NULL)
pAhead = pAhead->m_pNext;
}
return pBehind; // 后面的指针所指结点即为中间结点
}6,从尾到头打印单链表
6.1 自己使用栈
// 从尾到头打印链表,使用栈
void RPrintList(ListNode * pHead)
{
std::stack<ListNode *> s;
ListNode * pNode = pHead;
while(pNode != NULL)
{
s.push(pNode);
pNode = pNode->m_pNext;
}
while(!s.empty())
{
pNode = s.top();
printf("%d\t", pNode->m_nKey);
s.pop();
}
}6.2 使用递归函数
// 从尾到头打印链表,使用递归
void RPrintList(ListNode * pHead)
{
if(pHead == NULL)
{
return;
}
else
{
RPrintList(pHead->m_pNext);
printf("%d\t", pHead->m_nKey);
}
}7,合并两个链表
7.1 方法1:归并排序
// 合并两个有序链表
ListNode * MergeSortedList(ListNode * pHead1, ListNode * pHead2)
{
if(pHead1 == NULL)
return pHead2;
if(pHead2 == NULL)
return pHead1;
//【pHead1非空】且【pHead2非空】,先pHeadMerged加入一个头结点
ListNode * pHeadMerged = NULL;
if(pHead1->m_nKey < pHead2->m_nKey)
{
pHeadMerged = pHead1;
pHead1 = pHead1->m_pNext;
pHeadMerged->m_pNext = NULL;
}
else
{
pHeadMerged = pHead2;
pHead2 = pHead2->m_pNext;
pHeadMerged->m_pNext = NULL;
}
//循环加入
ListNode * pTemp = pHeadMerged;
while(pHead1 != NULL && pHead2 != NULL)
{
if(pHead1->m_nKey < pHead2->m_nKey)
{
pTemp->m_pNext = pHead1;
pHead1 = pHead1->m_pNext;
pTemp = pTemp->m_pNext;
pTemp->m_pNext = NULL;
}
else
{
pTemp->m_pNext = pHead2;
pHead2 = pHead2->m_pNext;
pTemp = pTemp->m_pNext;
pTemp->m_pNext = NULL;
}
}
if(pHead1 != NULL)
pTemp->m_pNext = pHead1;
else if(pHead2 != NULL)
pTemp->m_pNext = pHead2;
return pHeadMerged;
}7.2 方法2:递归算法
ListNode * MergeSortedList(ListNode * pHead1, ListNode * pHead2)
{
if(pHead1 == NULL)
return pHead2;
if(pHead2 == NULL)
return pHead1;
ListNode * pHeadMerged = NULL;
if(pHead1->m_nKey < pHead2->m_nKey)
{
pHeadMerged = pHead1;
pHeadMerged->m_pNext = MergeSortedList(pHead1->m_pNext, pHead2);
}
else
{
pHeadMerged = pHead2;
pHeadMerged->m_pNext = MergeSortedList(pHead1, pHead2->m_pNext);
}
return pHeadMerged;
8,判断一个单链表中是否有环
bool HasCircle(ListNode * pHead)
{
ListNode * pFast = pHead; // 快指针每次前进两步
ListNode * pSlow = pHead; // 慢指针每次前进一步
while(pFast != NULL && pFast->m_pNext != NULL)
{
pFast = pFast->m_pNext->m_pNext;
pSlow = pSlow->m_pNext;
if(pSlow == pFast) // 相遇,存在环
return true;
}
return false;
}9,求一个单链表中进入环的第一个节点
ListNode* GetFirstNodeInCircle(ListNode * pHead)
{
// 判断单链表是否有环问题
bool hasCircle = false;
if(pHead == NULL || pHead->m_pNext == NULL)
return NULL;
ListNode * pFast = pHead;
ListNode * pSlow = pHead;
while(pFast != NULL && pFast->m_pNext != NULL)
{
pSlow = pSlow->m_pNext;
pFast = pFast->m_pNext->m_pNext;
if(pSlow == pFast)
{
hasCircle = true;
break;
}
}
if(!hasCircle)
return NULL;
// 将环中的此节点作为假设的尾节点,将它变成两个单链表相交问题
ListNode * pAssumedTail = pSlow;
ListNode * pHead1 = pHead;
ListNode * pHead2 = pAssumedTail->m_pNext;
ListNode * pNode1, * pNode2;
int len1 = 1;
ListNode * pNode1 = pHead1;
while(pNode1 != pAssumedTail)
{
pNode1 = pNode1->m_pNext;
len1++;
}
int len2 = 1;
ListNode * pNode2 = pHead2;
while(pNode2 != pAssumedTail)
{
pNode2 = pNode2->m_pNext;
len2++;
}
pNode1 = pHead1;
pNode2 = pHead2;
// 先对齐两个链表的当前结点,使之到尾节点的距离相等
if(len1 > len2)
{
int k = len1 - len2;
while(k--)
pNode1 = pNode1->m_pNext;
}
else
{
int k = len2 - len1;
while(k--)
pNode2 = pNode2->m_pNext;
}
while(pNode1 != pNode2)
{
pNode1 = pNode1->m_pNext;
pNode2 = pNode2->m_pNext;
}
return pNode1;
}10,判断两个单链表是否相交
10.1 肯定无环
bool IsIntersected(ListNode * pHead1, ListNode * pHead2)
{
if(pHead1 == NULL || pHead2 == NULL)
return false;
ListNode * pTail1 = pHead1;
while(pTail1->m_pNext != NULL)
pTail1 = pTail1->m_pNext;
ListNode * pTail2 = pHead2;
while(pTail2->m_pNext != NULL)
pTail2 = pTail2->m_pNext;
return pTail1 == pTail2;
}10.2 可能有环
1.先判断带不带环
2.如果都不带环,就判断尾节点是否相等
3.如果一个带环一个不带环,则不相交
4.如果都带环,判断一链表上俩指针相遇的那个节点,在不在另一条链表上。如果在,则相交,如果不在,则不相交。
struct Node {
int data;
int Node *next;
};
//无环情况
int isJoinedSimple(Node * h1, Node * h2) {
while (h1->next != NULL) {
h1 = h1->next;
}
while (h2->next != NULL) {
h2 = h2-> next;
}
return h1 == h2;
}
//可能有环
int isJoined(Node *h1, Node * h2) {
Node* cylic1 = testCylic(h1);
Node* cylic2 = testCylic(h2);
//1,都无环
if (cylic1+cylic2==0)
return isJoinedSimple(h1, h2);
//2,一个有环一个无环
if (cylic1==0 && cylic2!=0 || cylic1!=0 &&cylic2==0)
return 0;
//3,都有环
Node *p = cylic1;
while (1) {
if (p==cylic2 || p->next == cylic2)
return 1;
p=p->next->next;
cylic1 = cylic1->next;
if (p==cylic1)
return 0;
}
}
Node* testCylic(Node * h1) {
Node * p1 = h1, *p2 = h1;
while (p2!=NULL && p2->next!=NULL) {
p1 = p1->next;
p2 = p2->next->next;
if (p1 == p2) {
return p1;
}
}
return NULL;
}11,求两个单链表相交的第一个节点
对第一个链表遍历,计算长度len1,同时保存最后一个节点的地址。
对第二个链表遍历,计算长度len2,同时检查最后一个节点是否和第一个链表的最后一个节点相同,若不相同,不相交,结束。
两个链表均从头节点开始,假设len1大于len2,那么将第一个链表先遍历len1-len2个节点,此时两个链表当前节点到第一个相交节点的距离就相等了,然后一起向后遍历,知道两个节点的地址相同。
时间复杂度,O(len1+len2)。参考代码如下:
ListNode* GetFirstCommonNode(ListNode * pHead1, ListNode * pHead2)
{
if(pHead1 == NULL || pHead2 == NULL)
return NULL;
int len1 = 1;
ListNode * pTail1 = pHead1;
while(pTail1->m_pNext != NULL)
{
pTail1 = pTail1->m_pNext;
len1++;
}
int len2 = 1;
ListNode * pTail2 = pHead2;
while(pTail2->m_pNext != NULL)
{
pTail2 = pTail2->m_pNext;
len2++;
}
if(pTail1 != pTail2) // 不相交直接返回NULL
return NULL;
ListNode * pNode1 = pHead1;
ListNode * pNode2 = pHead2;
// 先对齐两个链表的当前结点,使之到尾节点的距离相等
if(len1 > len2)
{
int k = len1 - len2;
while(k--)
pNode1 = pNode1->m_pNext;
}
else
{
int k = len2 - len1;
while(k--)
pNode2 = pNode2->m_pNext;
}
while(pNode1 != pNode2)
{
pNode1 = pNode1->m_pNext;
pNode2 = pNode2->m_pNext;
}
return pNode1;
}12,删除单链表pToBeDeleted节点
问题:给出一单链表头指针pHead和一节点指针pToBeDeleted,O(1)时间复杂度删除节点pToBeDeleted
对于删除节点,我们普通的思路就是让该节点的前一个节点指向该节点的下一个节点,这种情况需要遍历找到该节点的前一个节点,时间复杂度为O(n)。对于链表,链表中的每个节点结构都是一样的,所以我们可以把该节点的下一个节点的数据复制到该节点,然后删除下一个节点即可。要注意最后一个节点的情况,这个时候只能用常见的方法来操作,先找到前一个节点,但总体的平均时间复杂度还是O(1)。参考代码如下:
void Delete(ListNode * pHead, ListNode * pToBeDeleted)
{
if(pToBeDeleted == NULL)
return;
//要删除的节点不是最后一个
if(pToBeDeleted->m_pNext != NULL)
{
ListNode * temp = pToBeDeleted->m_pNext;
// 将下一个节点的数据复制到本节点,然后删除下一个节点
pToBeDeleted->m_nKey = temp->m_nKey;
pToBeDeleted->m_pNext = temp->m_pNext;
delete temp;
}
// 要删除的是最后一个节点,所以要找前一个节点
else
{
// 链表中只有一个节点的情况
if(pHead == pToBeDeleted)
{
pHead = NULL;
delete pToBeDeleted;
}
// 链表中有多个节点的情况
else
{
ListNode * pNode = pHead;
while(pNode->m_pNext != pToBeDeleted) // 找到倒数第二个节点
pNode = pNode->m_pNext;
pNode->m_pNext = NULL;
delete pToBeDeleted;
}
}
}解法:在p节点后添加q,然后交换p和q的数据即可:
q->next=p->next;
p->next=q;
swap(&p->value, &q->value);
13,单链表两两反转节点
两两反转单项链表就是把每两个数反转一次。如:(A -> B) -> (C ->D) -> (E -> F) ->(G -> H) -> (I) 两两反转后变为 (B -> A) -> (D ->C) -> (F -> E) ->(H -> G) -> (I)
Node* reverseInPair(Node* head) {
if (head == null || head.next == null){
return head;
}
Node* previousNode = null; // 这是指向前一个节点的指针
Node* current = head;
Node* nextNode = NULL;
Node* nextNextNode = NULL;
while(current != null && current.next != null) {
//得到下一个节点和下一个的下一个节点
nextNode = current.next;
nextNextNode = nextNode.next;
nextNode.next = current;
current.next = nextNextNode;
//更新前一个节点的下一个节点
if (previousNode != null) {
previousNode.next = nextNode;
}
previousNode = current;
current = nextNextNode; // 当前节点赋值为下一个的下一个节点继续遍历
}
return head;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









