







深入浅出的强化学习笔记(一)——概述
本系列将针对强化学习,从基础概念到最近十分热门的模型求解算法Deep Q-learning(即DQN),全面讲解强化学习的发展历史和算法原理。
1.强化学习的特征
强化学习与有监督学习有几分相似,但它并不存在明确的答案或者标签,而有一个看上去类似但实则大相径庭的概念——报酬。
下面以踢足球的进攻为例,把强化学习和有监督学习的区别再讲清楚一点。为了完成一次进攻,球员需要完成传球、运球、假动作等等一系列的步骤。
对于有监督学习来说就是,你进行每一个步骤时都能听到场外一个个观众在讨论,“我觉得向左后方传球是个不错的办法”、“我觉得向右前方运球推进简直是胡来”等等,然后球员根据听到的讨论进行决策,然后通过完成这一系列的决策从而最终进球。
而对于强化学习来说,它只知道进球的报酬是3分,获得一次罚球机会的报酬是2分,绕过一名防守球员的报酬是1分,被断球的报酬是-2分等等。具体到每一个步骤到底如何抉择才是最好的,就没有人告诉它了,他只能在脑海中不断演算分析、推倒重来,最后学习得到每一个步骤的最佳决策。
那么到底如何才能根据最后的报酬推导出每一次阶段性决策的评价得分呢?显然,我们只能进行逆向推导。
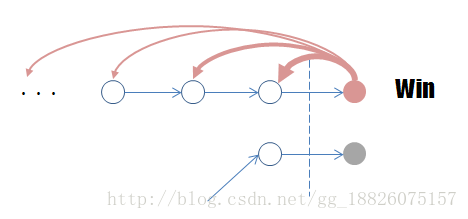
2.马尔科夫决策过程
下面介绍马尔科夫决策过程的几个重要参数:
- 状态S:State,比如下围棋时某一个时刻的当前棋局;
- 行动A(s):Actions,根据当前的状态s,选择进行动作a的概率;
- 转移T(s’|s, a):Transition,在状态s时,经过行动a,然后状态变化到s’的概率;
- 报酬R(s, a):Rewards,状态s时进行动作a对你的有利程度;
- 策略 π(s)−>a :Policy,当处于状态s时,最应该作出的行动a
如果感觉还是不够清晰,可以参考下下面的这幅图(街头霸王):
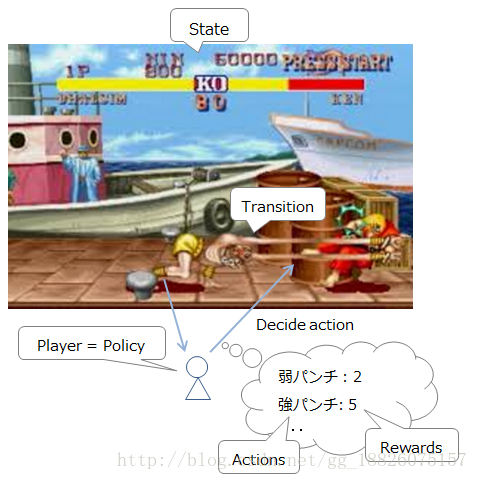
- 状态:自己的位置、自己的血量、敌人的位置、敌人的血量……
- 行动:当前时刻有效的所有按键组合
这种情况下不仅要考虑到获胜概率的最大化(路径的总报酬尽量大),还要兼顾到游戏时间有限,必须速战速决(路径要尽量短),同时随着推导路径长度的不断增长,不确定因素也会增多,求得的获胜概率的可信度也会不断下降。
于是,我们需要加入一个报酬衰减因子
λ
然后,我们再定义一个新的参数,来表示某状态的有利程度评价值
回到最初的问题,我们关心的是如何做出当前状态s下的最佳决策,显然有下面的公式
显然,我们若是每一个决策都选择有利程度最大的那个决策的话,我们的评价函数就要改写一下了(①式和②式联立,主要是为了消去 π(s) 这个变量)
上面的式子被称为Bellman equation,这样我们做出决策时就仅需要考虑当前的状态s即可,大大简化了算法模型的训练。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









