









介绍
论文名: “classification, ranking, and top-k stability of recommendation algorithms”.
本文讲述比较推荐系统在三种情况下, 推荐稳定性情况.
与常规准确率比较的方式不同, 本文从另一个角度, 即推荐算法稳定性方面进行比较.
详细
参与比较的推荐算法
包括:
- baseline
- 传统基于用户
- 传统基于物品
- oneSlope
- svd
比较方式
比较的过程分为两个阶段:
阶段一, 将原始数据分为两个部分, 一部分为已知打分, 另一部分为未知打分, 用于预测.
阶段二, 在用于预测打分那部分数据中, 取出一部分数据, 加入到已知打分部分, 剩余部分仍然为预测部分.
比较阶段一中的预测结果和阶段二中预测结果的比较.
数据划分情况如图所是.
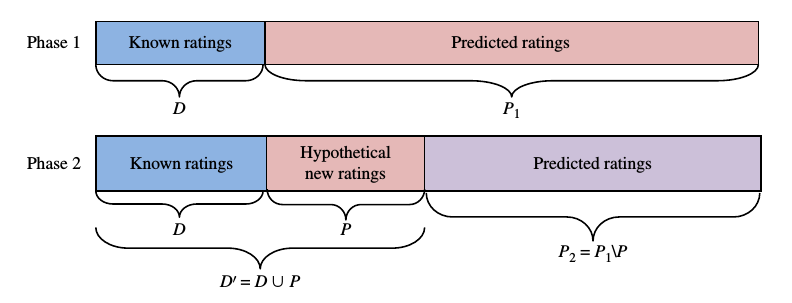
比较的方式
预测稳定性
预测性的评价方式有以下几种:
MAE, RMSE
分类稳定性
分类型的评价方式有以下几种:
准确率, 召回率, F-分数.
排名稳定性
排名型的评价方式有以下几种:
排名相关性, Spearman的
ρ
评价, Kruskal的
γ
评价, Kendall的
τ
评价.
前K项稳定性
前k项的评价方式有以下几种:
点击率稳定性(hit-rate), NDCG(normalized discounted cumulative gain).
比较的场景
稀疏性冲击
改变数据的稀疏性, 从几个方面比较这些推荐算法的稳定性.
结果如图所是.
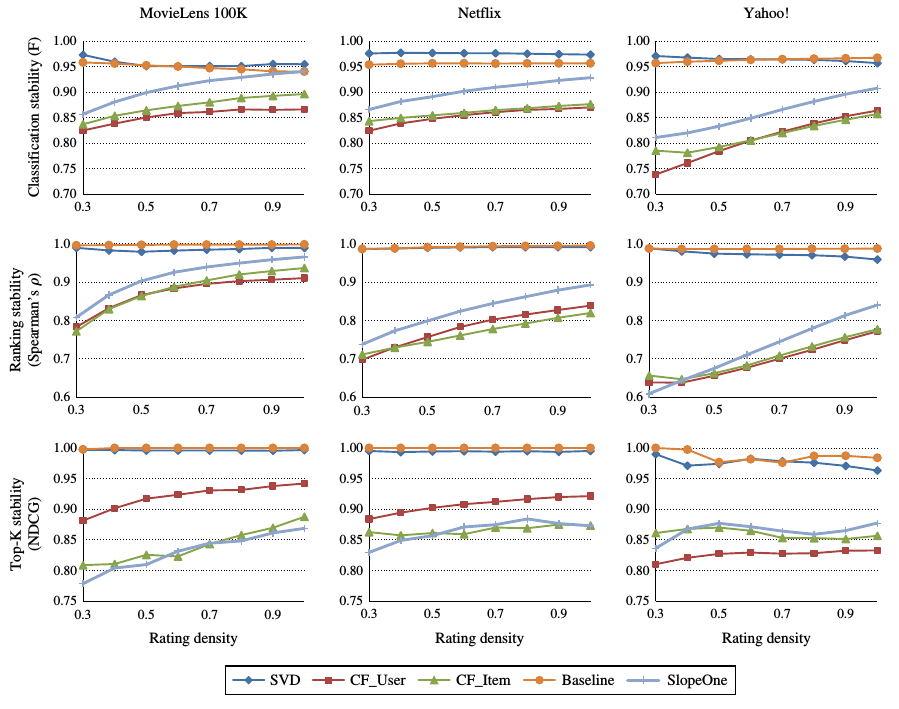
基于内存的推荐算法和slopeone算法表现出强烈的不稳定性和对数据敏感性.
svd和baseline算法相对稳定.
评价数量冲击
改变第二阶段中新加入数据的数量, 比较两次实验的差异.
结果如图所是:
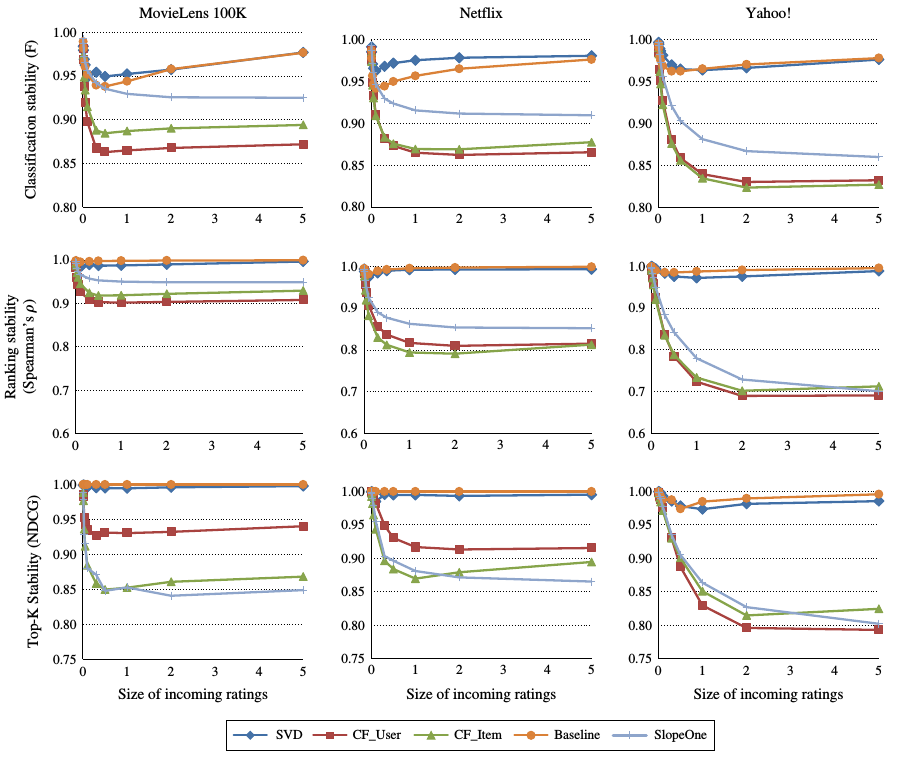
横坐标为比例, 即已知打分数据的倍数, 从10%到500%.
从图中可以看出, 在新加入的数据较少时, 各个推荐算法表现出高度的稳定性.
当新加入的数据较多时, 基于内存的推荐算法的稳定性不断下降.
相反, 基于模型的方法相对稳定.
打分分布冲击
除了新加入的数据外, 新加入的数据的数据分布也一定程度上影响了推荐算法的稳定性.
下表显示了修改数据分布的策略:
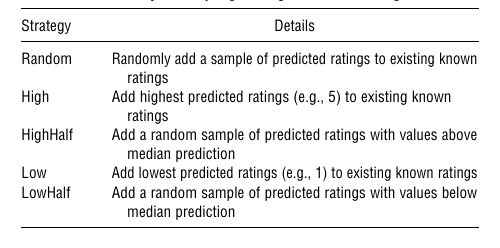
实验的结果如下:
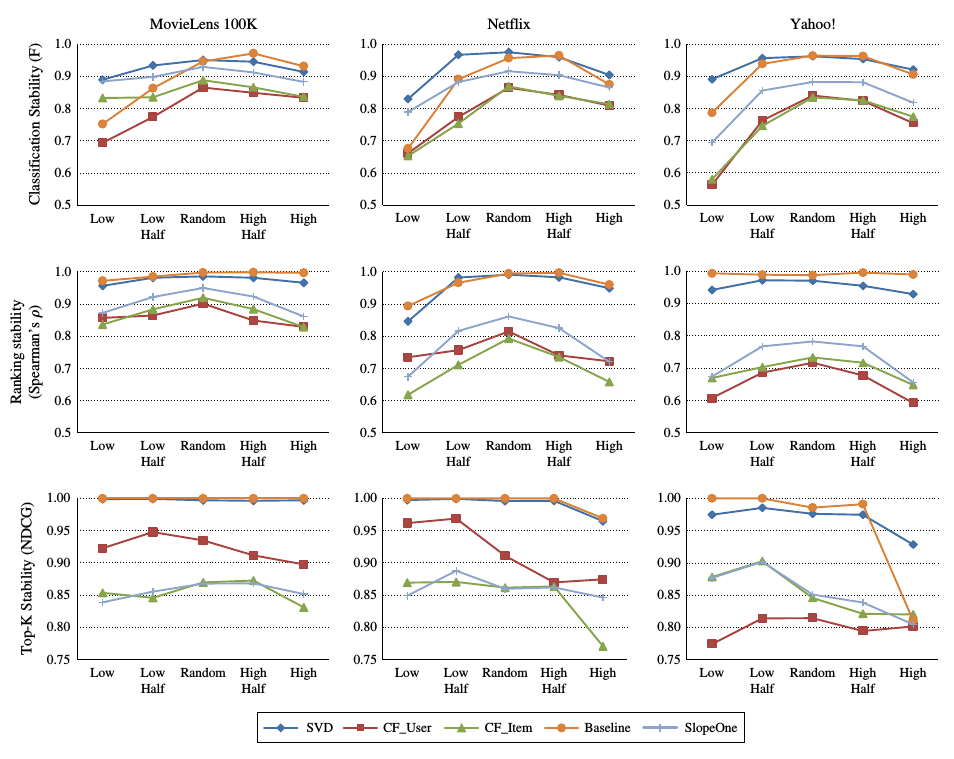
从图中可以看出, 当加入的数据为随机时, 各个推荐算法都表现出相对较高的稳定性.
但是, 当添加的数据出现歪斜时, 基于内存的推荐算法的稳定性降低较快, 基于模型的推荐算法的稳定性基本保持不变.
算法参数冲击
对于推荐算法而言, 除了数据的因素外, 还有算法本身参数对算法稳定性的影响.
对于基于内存的算法, 相似用户/物品的数量影响着推荐算法的效果,
对于svd算法, 隐含属性的数量影响着推荐算法的结果.
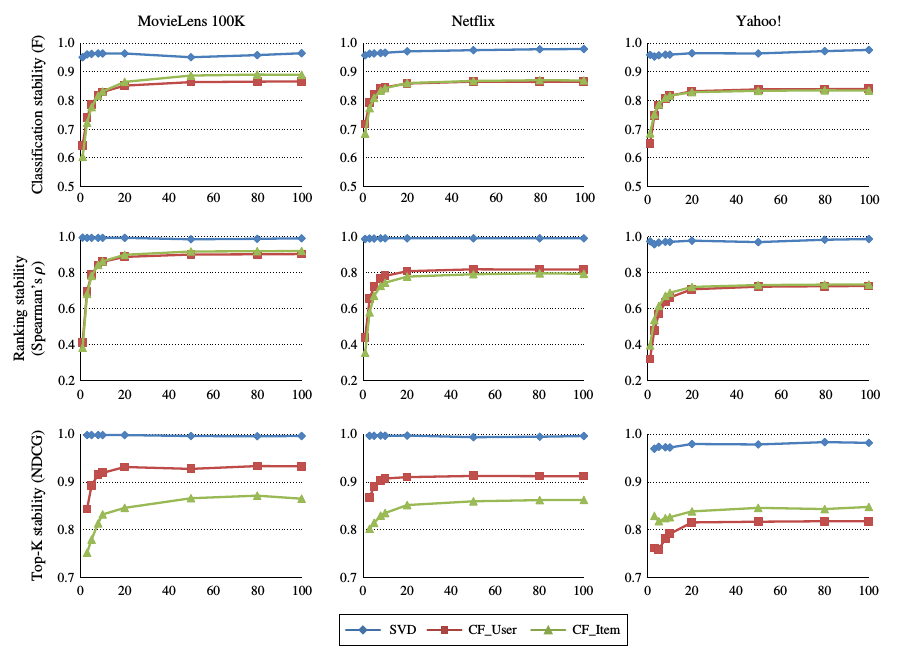
实验通过修改推荐算法参数的方式进行比较, 结果如图所时:
对于top-K的比较, k值的大小也影响推荐算法的稳定性.
通过修改k的大小, 实验的结果如图所时:
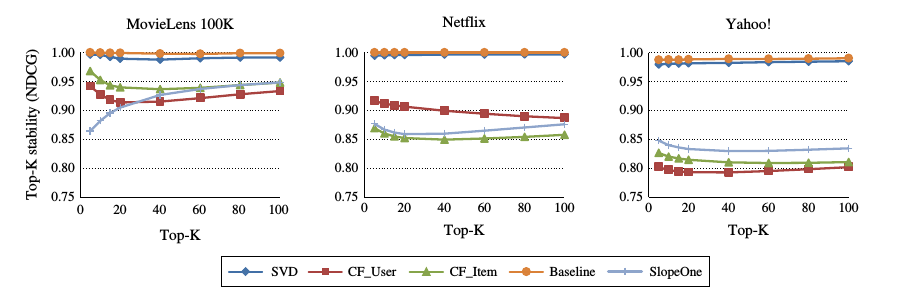
实验结果表示:
对于修改算法的参数, 对svd算法的影响较少, 对于基于内存的算法影响较大.
修改top-k中k的大小, 对基于模型的推荐算法影响较小, 对于基于内存的推荐算法的稳定性影响较大.
总结
对于上面多种情况的比较.
基于模型的推荐算法在多种情况下, 稳定性较高, 特别时svd算法.
基于内存的推荐算法稳定性较差.















 7904
7904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









