






1.导读
本节我们的目标是,在上一篇博文的基础上,我们再来实现几个复杂一点的CNN模型。为下一篇CNN做文本分类打下基础。
2.例子1:inception模型
inception模型来自谷歌的一篇论文Going Deeper with Convolutions.具体来讲,这里的卷积网络模型可以用下面的图表示:

#!/usr/bin/env python
# encoding: utf-8
"""
@version: python2.7
@author: Xiangguo Sun
@contact: sunxiangguodut@qq.com
@site: http://blog.csdn.net/github_36326955
@software: PyCharm
@file: inception
@time: 17-7-13 下午2:36
[Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842)
"""
from keras.layers import Conv2D, MaxPooling2D, Input,Concatenate
from keras.models import Model
from keras.optimizers import SGD
from keras.utils import plot_model
input_img = Input(shape=(3, 256, 256))
tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
output = Concatenate(axis=1)([tower_1, tower_2, tower_3])
model = Model(inputs=input_img,outputs=output)
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
print(model.summary())
plot_model(model,to_file="./inception.png",show_shapes=True)打印一下模型的结果,看一看结构:


例子2:a CNN model for text

#!/usr/bin/env python
# encoding: utf-8
"""
@version: python2.7
@author: Xiangguo Sun
@contact: sunxiangguodut@qq.com
@site: http://blog.csdn.net/github_36326955
@software: PyCharm
@file: cnn
@time: 17-7-11 下午4:58
"""
from keras.layers import Input,Conv3D,Concatenate,Reshape,Permute,MaxPooling1D,Activation,MaxPooling3D,Dense,Flatten
from keras.models import Model
from keras.optimizers import SGD
document_number=1000 # 一共有1000条微博(样本)
sent_num_per_doc = 50 # 每篇文本中规定有50个句子(多采少补)
word_num_per_sent = 20 # 每句话中20个单词(多采样少补齐)
wv_dim = 200 #词向量的维度为200
input = Input(shape=(word_num_per_sent,wv_dim,sent_num_per_doc,1))
conv1=Conv3D(filters=10,kernel_size=(1,wv_dim,1),activation='relu')(input)
max1 = MaxPooling3D(pool_size=(20, 1, 1))(conv1)
conv2=Conv3D(filters=10,kernel_size=(2,wv_dim,1),activation='relu')(input)
max2 = MaxPooling3D(pool_size=(19, 1, 1))(conv2)
conv3=Conv3D(filters=10,kernel_size=(3,wv_dim,1),activation='relu')(input)
max3 = MaxPooling3D(pool_size=(18, 1, 1))(conv3)
concatenate = Concatenate(axis=1)([max1, max2, max3])
reshape_layer =Reshape(target_shape=(30,50))(concatenate)
#reshape_layer这一层对应论文中的Concatenation layer
l=Permute(dims=(2,1))(reshape_layer)
max4 = MaxPooling1D(pool_size=50)(l)
flat=Flatten()(max4)
fuconect = Dense(units=20)(flat)
# fuconect对应论文中的fully connected layer
output=Activation(activation='softmax')(fuconect)
model = Model(inputs=input,outputs=output)
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
print(model.summary())
from keras.utils import plot_model
plot_model(model,to_file="./model.png",show_shapes=True)
打印结果如下:

welcome!
sunxiangguodut@qq.com
http://blog.csdn.net/github_36326955

Welcome to my blog column: Dive into ML/DL!

I devote myself to dive into typical algorithms on machine learning and deep learning, especially the application in the area of computational personality.
My research interests include computational personality, user portrait, online social network, computational society, and ML/DL. In fact you can find the internal connection between these concepts:
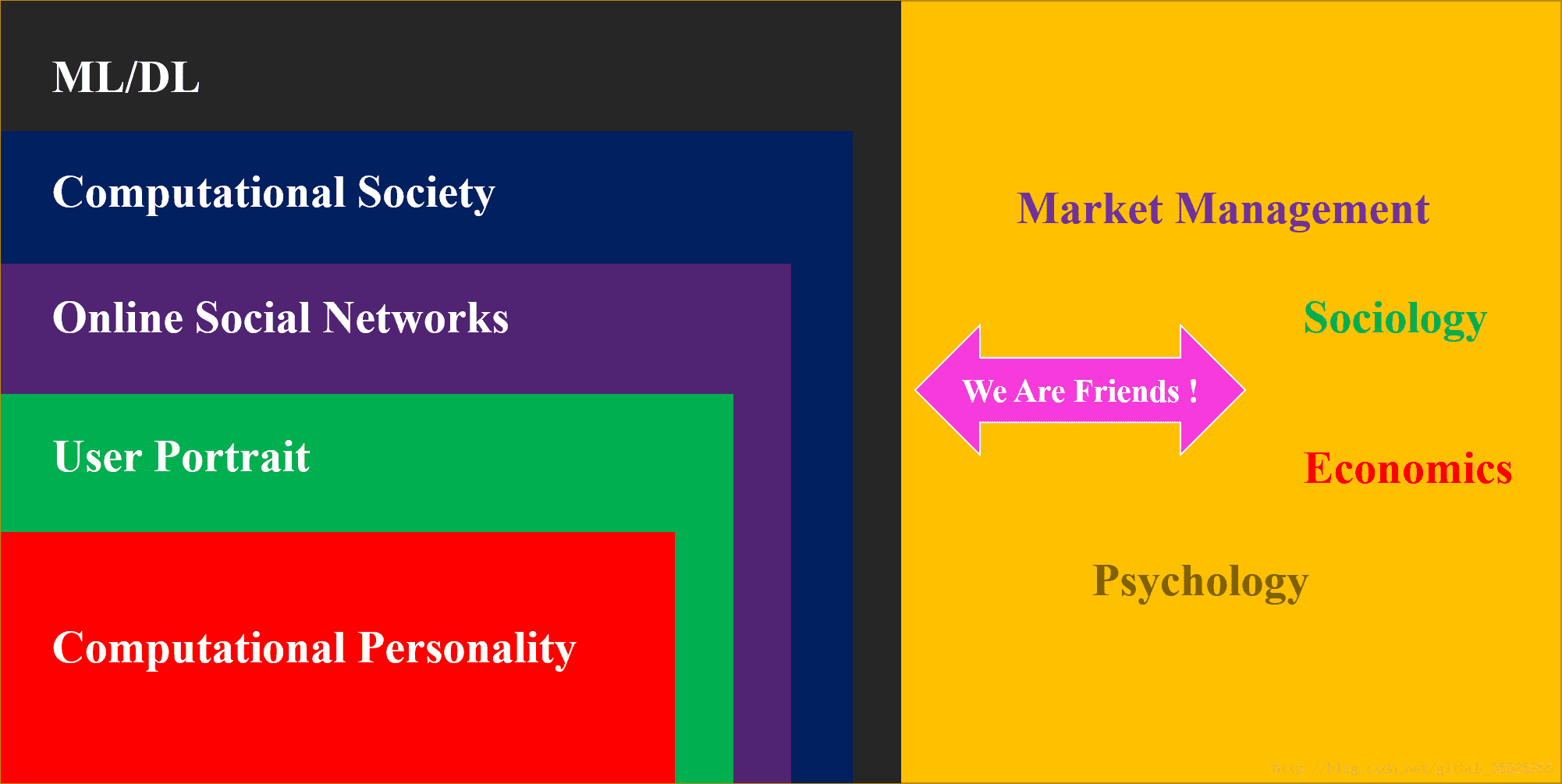
In this blog column, I will introduce some typical algorithms about machine learning and deep learning used in OSNs(Online Social Networks), which means we will include NLP, networks community, information diffusion,and individual recommendation system. Apparently, our ultimate target is to dive into user portrait , especially the issues on your personality analysis.
All essays are created by myself, and copyright will be reserved by me. You can use them for non-commercical intention and if you are so kind to donate me, you can scan the QR code below. All donation will be used to the library of charity for children in Lhasa.
手机扫一扫,即可:

















 9521
9521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









