






 本文解决了Spark程序在使用saveAsTextFile时遇到的错误,该错误源于Spark版本与Hadoop版本不匹配。提供了两种解决方案:一是重新下载并配置对应版本的Spark;二是自行编译Spark源码。
本文解决了Spark程序在使用saveAsTextFile时遇到的错误,该错误源于Spark版本与Hadoop版本不匹配。提供了两种解决方案:一是重新下载并配置对应版本的Spark;二是自行编译Spark源码。
环境: Spark1.3-Hadoop2.6-bin 、Hadoop-2.5
在运行Spark程序写出文件(savaAsTextFile)的时候,我遇到了这个错误:
java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeVerifyChunkedSums(IILjava/nio/ByteBuffer;ILjava/nio/ByteBuffer;IILjava/lang/String;J)V
at org.apache.hadoop.util.NativeCrc32.nativeVerifyChunkedSums(Native Method)
at org.apache.hadoop.util.NativeCrc32.verifyChunkedSums(NativeCrc32.java:57)
at org.apache.hadoop.util.DataChecksum.verifyChunkedSums(DataChecksum.java:291)
at org.apache.hadoop.hdfs.BlockReaderLocal.doByteBufferRead(BlockReaderLocal.java:338)
at org.apache.hadoop.hdfs.BlockReaderLocal.fillSlowReadBuffer(BlockReaderLocal.java:388)
at org.apache.hadoop.hdfs.BlockReaderLocal.read(BlockReaderLocal.java:408)
at org.apache.hadoop.hdfs.DFSInputStream$ByteArrayStrategy.doRead(DFSInputStream.java:642)
at org.apache.hadoop.hdfs.DFSInputStream.readBuffer(DFSInputStream.java:698)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:752)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:793)
at java.io.DataInputStream.read(DataInputStream.java:149)
at org.apache.hadoop.io.IOUtils.readFully(IOUtils.java:192)
at org.apache.hadoop.hbase.util.FSUtils.getVersion(FSUtils.java:495)
at org.apache.hadoop.hbase.util.FSUtils.checkVersion(FSUtils.java:582)
at org.apache.hadoop.hbase.master.MasterFileSystem.checkRootDir(MasterFileSystem.java:460)
at org.apache.hadoop.hbase.master.MasterFileSystem.createInitialFileSystemLayout(MasterFileSystem.java:151)
at org.apache.hadoop.hbase.master.MasterFileSystem.<init>(MasterFileSystem.java:128)
at org.apache.hadoop.hbase.master.HMaster.finishInitialization(HMaster.java:790)
at org.apache.hadoop.hbase.master.HMaster.run(HMaster.java:603)
at java.lang.Thread.run(Thread.java:744)查到的还是什么window远程访问Hadoop的错误,最后查阅官方文档HADOOP-11064
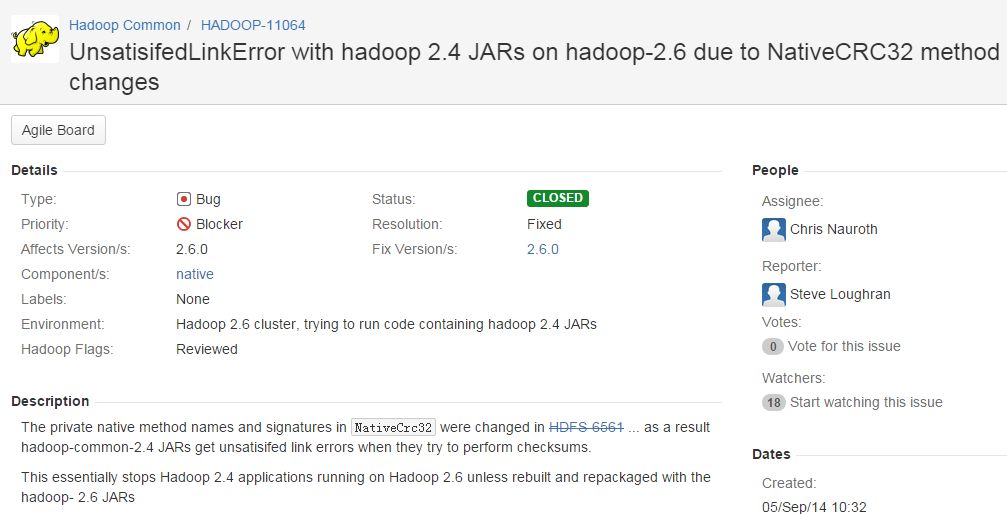
看描述可以清楚这是Spark版本与Hadoop版本不适配导致的错误,遇到这种错误的一般是从Spark官网下载预编译好的二进制bin文件。
因此解决办法有两种:
1. 重新下载并配置Spark预编译好的对应的Hadoop版本
2. 从官网上下载Spark源码按照预装好的Hadoop版本进行编译(毕竟Spark的配置比Hadoop轻松不少)。

















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









