







公司让做个cfs相关的培训,整理了个ppt,图片均来自网络,源作者在此不一一说明,深表歉意~~
The Outline
Basic concepts about Linux process & thread
Basic concepts about SMP
Linux bootup with BP and how to boot AP
Completely Fair Schedule(CFS) and RT Sched
How to load balance
How to debug smp issue with oprofile and other tools
0. Basic Concepts
Program
A program is a combination of intructions and data, which are put together to perform a task.
Process
A process is an abstraction created to embody the state of a program during its execution. Therefore, a process can also be viewed as an instance of a program, or called “a running program”.
API: fork(clone->do_fork->copy_process->copy_flag(CLONE_*: FILES, VM, FS, SIGHAND, NEWNS, NEWPID, NEWNET, NEWUTS(NEW* for namespace, LXC)...))
exec, wait(for freeing zombie child, have to wait, it is better to handle SIGCHLD from child process)
Thread
LWP. A process can have multiple execution contexts that work together to accomplish its goal. These different execution contexts are called “threads”. These threads share same virtual address space with the process.
API: pthread_create(fork), pthread_attr_init, pthread_attr_setschedpolicy, pthread_attr_setschedparam, pthread_attr_getschedparam, pthread_exit, pthread_cancel, pthread_join(like as wait, free child resource), pthread_detach(self free all resource)
Kernel Thread
A thread without user-mode virtual address space. All instructions and data of a kernel thread are in Kernel VA Space, and in Linux they are usually linked together with kernel as a part of kernel image, such as kswapd, kflushd and ksoftirqd.
API: kthread_run(create+wakeup), kthread_create, kthread_stop
task_struct{
state, pid, mm, active_mm, prio, se, cpus_allowed, children, sibling, fs, files, signal, cgroups}
((struct thread_info *)(sp & ~(THREAD_SIZE – 1)))->task
THREAD_SIZE=8K
init process 0
#define INIT_TASK(tsk) { \
.state = 0, \
.thread_info = &init_thread_info, \
……
.mm = NULL, \\\NULL for kernel task
.active_mm = &init_mm, \
……
}
In init_mm, pgd= swapper_pg_dir(0xC0004000)
Former 768 PGD entries for User VA Space
All User process shares the same kernel PGD.
init process 0 becomes “idle” process ( “idle” kernel thread).
1. Scheduler History
2.4 O(n)
One simple runqueue
nice and counter
2.6 O(1)
Kernel preemptible
Bitmap
runqueue(active/expire) for per-cpu and per-priority
static_prio and time slice
2. CFS Introduction
From kernel 2.6.23 versionFor task runtime balance
Sched policy:SCHED_NORMAL, SCHED_FIFO, SCHED_RR, SCHED_IDLE, SCHED_BATCH(for cpu consume type)
sched entity, sched class
sched domain , sched group
3.1 priority
Normal task Prioritystatic_prio(nice:-20~19->100~139), prio(dynamic for Priority Inversion): low value for high priority
RT task priority
rt_priority(0~99): high value for high priority
normal_prio(0~139): unify for nomarl and rt, low value for high priority
nice(), setpriority() for normal task
sched_setscheduler() for RT task
3.2 SCHED_FIFO and SCHED_RR
pick_next_rt_task: Find the highest rt_priority task list by bitmap; pick the first task of the highest rt_priority task list, after running, put it to tail of list
SCHED_FIFO: run till initiative schedule or be preempted by higher priority rt task
SCHED_RR: run till initiative schedule or be preempted by higher priority rt task, or out of timeslice.
RT task(throttling): sched_rt_period_us(1000000us), sched_rt_runtime
4.1 RB Tree for Normal Task Organization
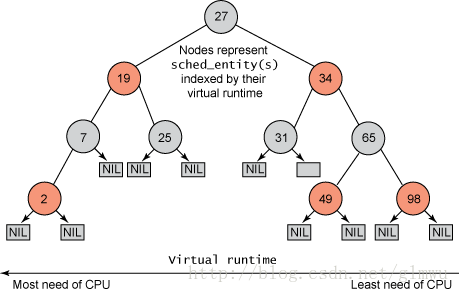
4.2 Node sequence of RB Tree
RB tree, O(log n)
The RB node sequence is determined by vruntime(The most left leaf is the lowest vruntime value)
The speed of Consuming vruntime is determined by prio
Constant arrary for static_prio to weight:
prio_to_weight[ ]/prio_to_wmult[ ](1 nice~10%weight)
vruntime = delta_exec * (NICE_0_LOAD / weight)
4.3 task_struct to RB tree in CFS
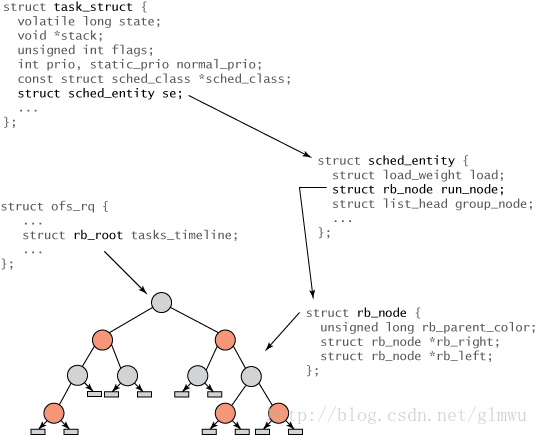
4.4 From rq to task
rq is per cpu variable

4.5 Sched_class for Sched Policy
fair_sched_class/rt_sched_class
struct sched_class
{
const struct sched_class *next;void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
struct task_struct * (*pick_next_task) (struct rq *rq);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
void (*pre_schedule) (struct rq *this_rq, struct task_struct *task);
void (*post_schedule) (struct rq *this_rq);
void (*task_waking) (struct rq *this_rq, struct task_struct *task);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*switched_from) (struct rq *this_rq, struct task_struct *task,
int running);
void (*switched_to) (struct rq *this_rq, struct task_struct *task,
int running);
...... }
4.6 Sched domain
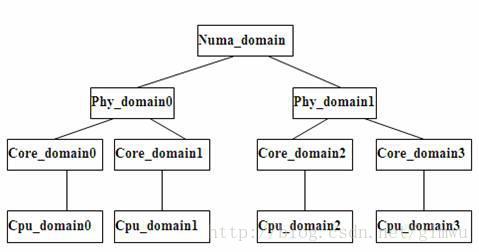
4.7 Group and Domain
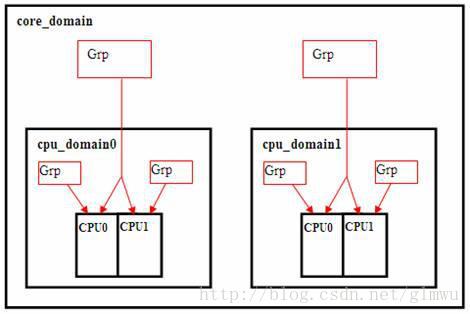
5. How to schedule
l Load Balance Rule
l 1) In cpu_domain level, all cpus share cache and cpu_power(power in cpu group), free to load balance
l 2) In core_domain level, all cpus share L2 cache, load balance when core domain is imbalance
l 3) In phys_domain level, must flush all cache
4) In numa_domain level, load balance costs much
5.1 Two Schedule Entry
l When no running task in current rq||initiative calling||sleep||from system space to user space, call schedule()
l When hrtimer(HZ) timeout, call scheduler_tick()
5.1.1 Schedule()
1) Disable preempt2) cancel hrtimer
3) clear flag of need resched
4.1) If task is in unrunnable&&preemptible
4.1.1) If has signal,set it to running state
4.1.2) Else remove the task from the runqueue
5) If no task on rq
5.1) idle load balance(for each domain from down to up)
6) put_prev_task
7) pick_next_task
7.1) if (rq->nr_running == rq->cfs.nr_running)//it is SCHED_NORMAL(fai sched class)
call fair_sched_class.pick_next_task
7.2) else
for each class in class list from sched_class_highest, call
class->pick_next_task, untill find task
8) sched_info_switch
9) context_switch
10) Enable preempt
11) Check if need resched, if so go to 1)
5.1.2 How to pick and put task for fair Sched
pick_next_task(fair scheduler) on rq
1) Find the rb_leftmost node on the cfs_rq
2) get sched entity from rb node with rb_entry()
3) if my_q of the se is null(it is a task)
3.1) find it and dequeue entity from rq
4) else, go to 1)
put_prev_task
6.1) if it belongs to sched group(parent != null)
it will be put in every iterator entity's rq from it to parent)
6.2) else(parent == null)
put it into current rq
pick_next_task_rt:
Find the highest rt_priority task list by bitmap; pick the first task of the highest rt_priority task list.
put_prev_task_rt:
//if task is in running state&&has allowed cpu
if (p->se.on_rq && p->rt.nr_cpus_allowed > 1)
1) del it from current node of list
2) add it to tail of list
5.1.4 Scheduler_tick()
1) update rq clock and load2) notify sched_class to update process's vruntime
3) update timestamp of next load balance
4) raise softirq for load balance
5.1.5 How to load balance
1) find busiest group in the domain2) find busiest rq in the busiest group
3) if running tasks >1 on the busiest rq
3.1) Disable local irq and lock the rq
3.2) move task from the busiest rq to current rq
3.3) If this_cpu is not current cpu, send ipi to wake up this_cpu
3.4) If this_cpu is set to all_pinned(affinity), clear it from busiest cpu mask
3.5) Update schedule some flag and info
3.6) return
4) if running tasks <= 1 && moving task is fail
4.1) if the busiest cpu needs active_balance
4.2) set the busiest cpu's push_cpu with this_cpu
4.3) wake up the busiest cpu's migration_thread to move task to other cpu, then it can be in idle state.
4.4) update some info
5) if not active_balance for busiest cpu
5.1)bring forward hrtimer by set min_interval to sd->balance_interval
6) else
6.1)delay hrtimer by sd->balance_interval *= 2
5.2 How to find busiest group and rq
Condition:
avg_load>prev.max_load&&sum_nr_running>group_capacity||
group_imb
struct sg_lb_stats {
unsigned long avg_load; /*Avg load across the CPUs of the group */
unsigned long group_load; /* Total load over the CPUs of the group */
unsigned long sum_nr_running; /* Nr tasks running in the group */
unsigned long sum_weighted_load; /* Weighted load of group's tasks */
unsigned long group_capacity;
int group_imb; /* Is there an imbalance in the group ? */
};
find max rq->load.weight in group
6.1 Oprofile
Sampling: event based and time based
Two part:
Kernel module oprofile.ko: for saving sampling data in memory
get performance counter register_timer_hook
User daemon oprofiled: get sampling data, save it to file and parse.
6.2 config and compile
Kernel:
1) menuconfig:
enable Oprofile in profiling menu
enable Local APIC and IO-APIC in Processor type and features menu
2) .config: set CONFIG_PROFILING=y and CONFIG_OPROFILE=y
oprofile toolkit compile:
./configure --with-kernel-support
make
make install
6.3 oprofile toolkit
oprofiled
opcontrol: user interface
opannotate: comments source code for sampling data
opreport: binary and symble map
ophelp: list supported events
opgprof: generate gprof format data(a program analyzer)
opstack: generate call stack, with call-graph patch for kernel
oparchive: archive raw sampling data
op_import: change data format
6.4 How to use oprofile
# opcontrol --setup --ctr0-event=CPU_CLK_UNHALTED
--ctr0-count=600000 --vmlinux=/usr/src/linux-*/vmlinux
# opcontrol --start
# opcontrol --stop/--shutdown/--dump(/var/lib/oprofile/samples /oprofiled.log)
# opcontrol --status
# opcontrol --list-events
# opcontrol --event=L2_CACHE_MISS:500 --event=L1_DTLB_MISS_AND_L2_DTLB_HIT:500
# opreport -l ./testbinary
cat /proc/cpuinfo&meminfo
grep processor /proc/cpuinfo | wc -l
top/ps
sar -q 1 5(load)/sar -u 2 3(cpu utilization)/sar -r(mem)
vmstat all purpose performance tool yes(in kernel base version)
mpstat provides statistics per CPU no
sar all purpose performance monitoring tool no
iostat provides disk statistics no
netstat provides network statistics yes
dstat monitoring statistics aggregator no
iptraf traffic monitoring dashboard no
netperf Network bandwidth tool no
ethtool reports on Ethernet interface configuration yes
iperf Network bandwidth tool no
tcptrace Packet analysis tool no














 1071
1071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









