




 本文介绍了一种无监督学习算法——聚类算法的基本概念,并详细解释了K-Means算法的工作原理及其具体实现步骤。包括算法流程、初始化过程、质心选择与更新等关键环节。
本文介绍了一种无监督学习算法——聚类算法的基本概念,并详细解释了K-Means算法的工作原理及其具体实现步骤。包括算法流程、初始化过程、质心选择与更新等关键环节。
一、聚类算法的简介
聚类算法是一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。聚类算法与分类算法最大的区别是:聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
二、K-Means算法的概述
基本K-Means算法的思想很简单,事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,知道质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
三、K-Means算法的流程
- 初始化常数K,随机选取初始点为质心
- 重复计算一下过程,直到质心不再改变
- 计算样本与每个质心之间的相似度,将样本归类到最相似的类中
- 重新计算质心
- 输出最终的质心以及每个类
四、K-Means算法的实现
对数据集进行测试
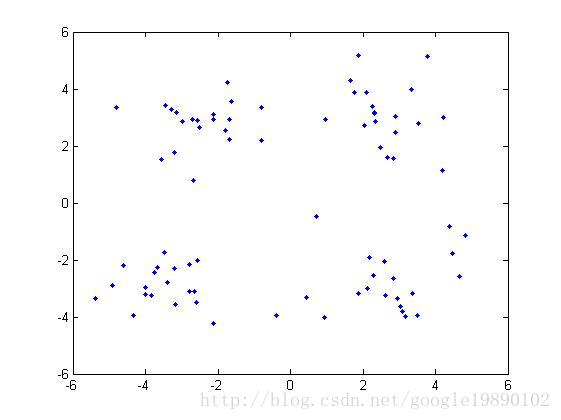
原始数据集
MATLAB代码
主程序
%% input the data
A = load('testSet.txt');
%% 计算质心
centroids = kMeans(A, 4);
随机选取质心
%% 取得随机中心
function [ centroids ] = randCent( dataSet, k )
[m,n] = size(dataSet);%取得列数
centroids = zeros(k, n);
for j = 1:n
minJ = min(dataSet(:,j));
rangeJ = max(dataSet(:,j))-min(dataSet(:,j));
centroids(:,j) = minJ+rand(k,1)*rangeJ;%产生区间上的随机数
end
end
计算相似性
function [ dist ] = distence( vecA, vecB )
dist = (vecA-vecB)*(vecA-vecB)';%这里取欧式距离的平方
end
kMeans的主程序
%% kMeans的核心程序,不断迭代求解聚类中心
function [ centroids ] = kMeans( dataSet, k )
[m,n] = size(dataSet);
%初始化聚类中心
centroids = randCent(dataSet, k);
subCenter = zeros(m,2);%做一个m*2的矩阵,第一列存储类别,第二列存储距离
change = 1;%判断是否改变
while change == 1
change = 0;
%对每一组数据计算距离
for i = 1:m
minDist = inf;
minIndex = 0;
for j = 1:k
dist= distence(dataSet(i,:), centroids(j,:));
if dist < minDist
minDist = dist;
minIndex = j;
end
end
if subCenter(i,1) ~= minIndex
change = 1;
subCenter(i,:)=[minIndex, minDist];
end
end
%对k类重新就算聚类中心
for j = 1:k
sum = zeros(1,n);
r = 0;%数量
for i = 1:m
if subCenter(i,1) == j
sum = sum + dataSet(i,:);
r = r+1;
end
end
centroids(j,:) = sum./r;
end
end
%% 完成作图
hold on
for i = 1:m
switch subCenter(i,1)
case 1
plot(dataSet(i,1), dataSet(i,2), '.b');
case 2
plot(dataSet(i,1), dataSet(i,2), '.g');
case 3
plot(dataSet(i,1), dataSet(i,2), '.r');
otherwise
plot(dataSet(i,1), dataSet(i,2), '.c');
end
end
plot(centroids(:,1),centroids(:,2),'+k');
end
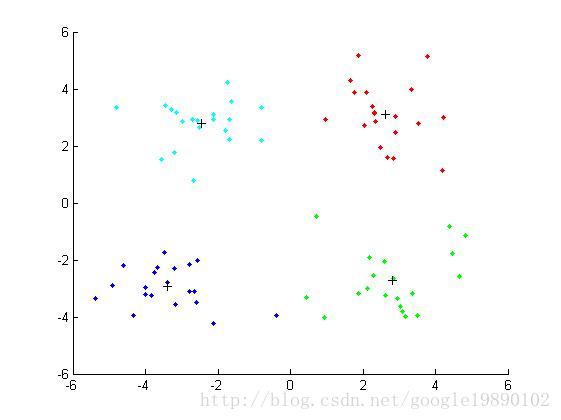
最终的聚类结果

















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









