









1.实验数据构建
首先构建实验所用的数据,这里我才用的是随机数生成的形式,生成1000个二
维空间的点,存储到特定文件与集合中,并在函数结束时将集合返回。代码如下:

2.K-means算法实现
有了数据之后,接下来要做的就是K-means算法本身的实现了,首先,先初始化
k个点作为初始中心点,这里的k值我设置为3。为了使得生成的初始中心点与实际的数据点分布相符,我采用了x_rand = min + (max-min)*random(1)的形式,其中min与max分别为当前维度取值的最大值与最小值,x_rand为当前维度的初始值。代码如下:

有了初始中心点后,便开始进行聚类。遍历所有的数据点,针对每一个数据点,找出距离该数据点距离最近的中心点,然后将该数据点与对应中心点归为一类。完成一次遍历后,针对每一个类别,计算类别中所有数据的每个维度的平均值,将所有维度平均值组合起来形成新的中心点,然后重复上述过程,直至所有数据点的类别不再变化为止。代码如下:


3.聚类结果写入文件
聚类完成后,将聚类所得信息写入相应文件中。代码如下:

4.聚类结果可视化
将聚类结果以散点图的形式输出,代码和效果如下:


注:其中红色的点为各类别的中心点。
#用户聚类
from numpy import *
import matplotlib.pyplot as plt
#生成随即数据并写文件
def rand_data(filename):
fw = open(filename,'w')
dataSet = random.rand(1000,2)
#print(dataSet)
for data in dataSet:
#print(data)
data = str(data).split()
fw.write(','.join(data) + "\n")
fw.close()
return dataSet
# #读数据
# def loadData(filename):
# data=[]
# fo=open(filename)
# for line in fo:
# line=line.replace('\n','')
# l1=line.split(',')
# ls=[]
# for i in range(1,2):
# ls.append(float(l1[i]))
# #print(ls)
# data.append(ls)
# fo.close()
# return data
#计算两个点之间的距离
def dist(va,vb):
return sqrt(nansum(power((va-vb),2)))
#生成随机中心,k为聚类个数,dataset为原始用于聚类的数据集
def randCents(dataSet,k):
#获取数据的列数,即每条数据有几个属性
n=shape(dataSet)[1]
#生成一个k行n列的全零矩阵
cents=mat(zeros((k,n)))
for i in range(n):
mini=min(dataSet[:,i])
maxi=max(dataSet[:,i])
rangei=float(maxi-mini)
#random.rand(k,1)生成一个k行一列的随机数组,
# 每个元素分布在(0,1)之间
cents[:,i]=mini+rangei*random.rand(k,1)
return cents
#k-means的主体方法
def kMeans(dataSet,k,getDist=dist,getCents=randCents):
#shape[0],数据的行数 shape[1],数据的列数
m=shape(dataSet)[0]
#print(m)
#生成一个m行两列的全零数组,并转化为矩阵
cluster=mat(zeros((m,2)))
#初始化K个聚类中心
cents=getCents(dataSet,k)
flag=True
while flag:
flag=False
#对每一个数据点,计算他与每个分类的中心点的距离中
# 最近的那一个中心点x,然后将它的类别设为x
for i in range(m):
minDist=10000000000000
minIdx=-1
for j in range(k):
dist=getDist(cents[j,:],dataSet[i,:])
if dist<minDist:
minDist=dist
minIdx=j
#只要有一个点的类别发生变化,就继续循环下去
if cluster[i,0]!=minIdx:
flag=True
#cluster中的数据为类别以及该点距离这一类中心点的距离
cluster[i,:]=minIdx,minDist**2
#print(cents)
#将所有的数据根据上面所分的类别进行处理,
# 计算每类数据当中的新的中心点,然后重新迭代k-means算法
for cent in range(k):
pts=[]
for data in range(m):
if cluster[data,0]==cent:
pts.append(dataSet[data,:])
#pts=mat(pts)
if(len(pts)!=0):
cents[cent,:]=nanmean(pts,axis=0)
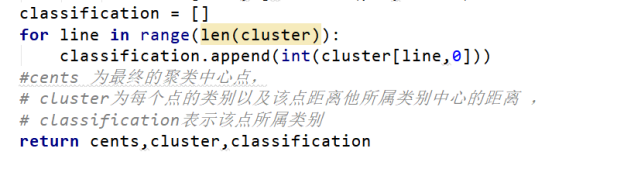
classification = []
for line in range(len(cluster)):
classification.append(int(cluster[line,0]))
#cents 为最终的聚类中心点,
# cluster为每个点的类别以及该点距离他所属类别中心的距离 ,
# classification表示该点所属类别
return cents,cluster,classification
#将结果i而文件输出
def writeMat(m,filename):
fw=open(filename,'w')
for i in range(shape(m)[0]):
row=[]
for j in range(shape(m)[1]):
row.append(str(m[i,j]))
fw.write(','.join(row)+'\n')
fw.close()
def draw_scatter(dataSet,classification,cents):
#所有的数据
x = []
y = []
type = []
#print(dataSet)
for line in range(len(dataSet)):
x.append(dataSet[line,0])
y.append(dataSet[line,1])
type.append(classification[line])
#中心点
cent_x = []
cent_y = []
for line in range(len(cents)):
cent_x.append(cents[line,0])
cent_y.append(cents[line,1])
plt.scatter(x, y, c=type, marker="o")
plt.colorbar()
plt.scatter(cent_x,cent_y,c='r')
plt.xlabel('x')
plt.ylabel('y')
plt.title('K-Means')
plt.show()
def main(filename,k):
data = rand_data(filename)
#data=loadData(filename)
#通过mat操作将data转化成矩阵
dataSet=mat(data)
cents,cluster,classification=kMeans(dataSet,k)
#print(cents0)
writeMat(cents,str(k)+'cents__'+filename)
writeMat(cluster,str(k)+'cluster__'+filename)
print(classification)
draw_scatter(dataSet,classification,cents)
main('K-means.csv',3)















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









