







 本文介绍了在Hadoop 2.7.1环境下运行WordCount程序的详细步骤,包括准备输入文件、运行MapReduce任务及查看输出结果。同时,对WordCount的源码进行了分析,展示了程序的基本结构和主要函数,指导读者理解并自实现WordCount程序。
本文介绍了在Hadoop 2.7.1环境下运行WordCount程序的详细步骤,包括准备输入文件、运行MapReduce任务及查看输出结果。同时,对WordCount的源码进行了分析,展示了程序的基本结构和主要函数,指导读者理解并自实现WordCount程序。
一、前言
在之前我们已经在 CenOS6.5 下搭建好了 Hadoop2.x 的开发环境。既然环境已经搭建好了,那么现在我们就应该来干点正事嘛!比如来一个Hadoop世界的HelloWorld,也就是WordCount程序(一个简单的单词计数程序)
二、WordCount 官方案例的运行
2.1 程序简介
WordCount程序是hadoop自带的案例,我们可以在 hadoop 解压目录下找到包含这个程序的 jar 文件(hadoop-mapreduce-examples-2.7.1.jar),该文件所在路径为 hadoop/share/hadoop/mapreduce。
我们可以使用 hadoop jar 命令查看该jar包详细信息。执行命令:hadoop jar hadoop-mapreduce-examples-2.7.1.jar
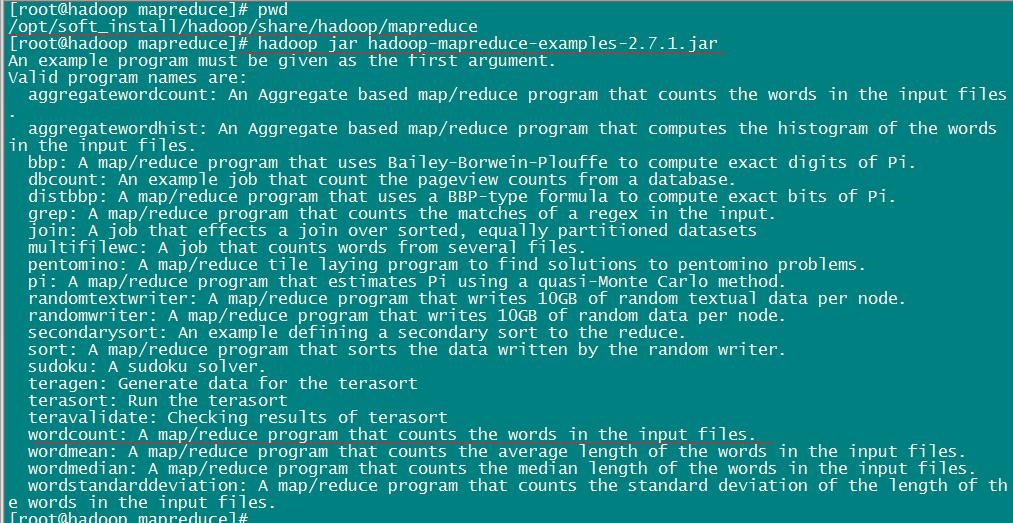
可以看到,该 jar 文件中并不止有一个案例,当然我们此时只想看看 WordCount 程序,其他的靠边边。那么我们按照提示,执行命令:hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount 看看有什么东西?

根据提示,它说是需要输入文件和输出目录,那么接下来,我们就准备以下输入文件和输出目录吧。
注:其实只需要准备输入文件,不需要准备输出目录。因为 MapReduce 程序的运行,其输出目录不能是已存在的,否则会抛出异常。
这是为了避免数据覆盖的问题。请看《Hadoop权威指南》
2.2 准备材料
为了方便使用该官方 jar 文件,我们在当前目录下创建一个 input 目录(你也可以在别的目录下创建目录,目录名也可以自己取,喜欢就好),用来存放输入文件。然后准备2个输入文件。如下所示:
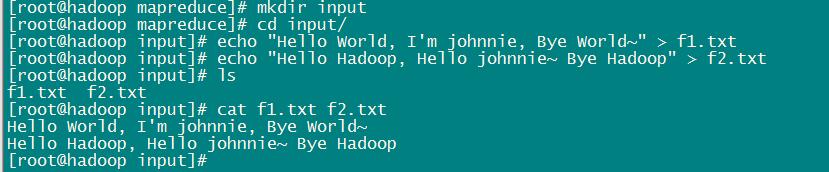
因为我们是使用 HDFS 文件系统的,所以我们要运行 WordCount 这个 MapReduce 程序的话,需要将文件放入 HDFS 上。因此我们使用 HDFS 的文件系统命令,在HDFS文件系统根目录下创建一个input目录,用来保存输入文件。执行命令:hadoop fs -mkdir /input

注:hadoop fs -mkdir 命令是用来在 HDFS 上创建目录的,类似于Linux下的 mkdir 命令
目录创建好后,我们需要把刚刚在本地文件系统上准备的输入文件拷贝到 HDFS 上。执行命令:h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









