







本篇文章是综合了几篇博主觉得写的不错的文字。唯一的原创是把它们挑出来组合在一起。
1、反向传播神经网络极简入门
我一直在找一份简明的神经网络入门,然而在中文圈里并没有找到。直到我看到了这份162行的Python实现,以及对应的油管视频之后,我才觉得这就是我需要的极简入门资料。这份极简入门笔记不需要突触的图片做装饰,也不需要赘述神经网络的发展历史;要推导有推导,要代码有代码,关键是,它们还对得上。对于欠缺的背景知识,利用斯坦福大学的神经网络wiki进行了补全。
单个神经元
神经网络是多个“神经元”(感知机)的带权级联,神经网络算法可以提供非线性的复杂模型,它有两个参数:权值矩阵{Wl}和偏置向量{bl},不同于感知机的单一向量形式,{Wl}是复数个矩阵,{bl}是复数个向量,其中的元素分别属于单个层,而每个层的组成单元,就是神经元。
神经元
神经网络是由多个“神经元”(感知机)组成的,每个神经元图示如下:

这其实就是一个单层感知机,其输入是由 和+1组成的向量,其输出为
和+1组成的向量,其输出为 ,其中f是一个激活函数,模拟的是生物神经元在接受一定的刺激之后产生兴奋信号,否则刺激不够的话,神经元保持抑制状态这种现象。这种由一个阈值决定两个极端的函数有点像示性函数,然而这里采用的是Sigmoid函数,其优点是连续可导。
,其中f是一个激活函数,模拟的是生物神经元在接受一定的刺激之后产生兴奋信号,否则刺激不够的话,神经元保持抑制状态这种现象。这种由一个阈值决定两个极端的函数有点像示性函数,然而这里采用的是Sigmoid函数,其优点是连续可导。
Sigmoid函数
常用的Sigmoid有两种——
单极性Sigmoid函数

或者写成

其图像如下

双极性Sigmoid函数

或者写成

把第一个式子分子分母同时除以ez,令x=-2z就得到第二个式子了,换汤不换药。
其图像如下

从它们两个的值域来看,两者名称里的极性应该指的是正负号。从导数来看,它们的导数都非常便于计算:
对于有 ,对于tanh,有
,对于tanh,有 。
。
视频作者Ryan还担心观众微积分学的不好,细心地给出了1/(1+e^-x)求导的过程:

一旦知道了f(z),就可以直接求f'(z),所以说很方便。
本Python实现使用的就是1/(1+e^-x)
- def sigmoid(x):
- """
- sigmoid 函数,1/(1+e^-x)
- :param x:
- :return:
- """
- return 1.0/(1.0+math.exp(-x))
-
-
- def dsigmoid(y):
- """
- sigmoid 函数的导数
- :param y:
- :return:
- """
- return y * (1 - y)
也可以使用双曲正切函数tanh
- def sigmoid(x):
- """
- sigmoid 函数,tanh
- :param x:
- :return:
- """
- return math.tanh(x)
其导数对应于:
- def dsigmoid(y):
- """
- sigmoid 函数的导数
- :param y:
- :return:
- """
- return 1.0 - y ** 2
神经网络模型
神经网络就是多个神经元的级联,上一级神经元的输出是下一级神经元的输入,而且信号在两级的两个神经元之间传播的时候需要乘上这两个神经元对应的权值。例如,下图就是一个简单的神经网络:

其中,一共有一个输入层,一个隐藏层和一个输出层。输入层有3个输入节点,标注为+1的那个节点是偏置节点,偏置节点不接受输入,输出总是+1。
定义上标为层的标号,下标为节点的标号,则本神经网络模型的参数是: ,其中
,其中 是第l层的第j个节点与第l+1层第i个节点之间的连接参数(或称权值);
是第l层的第j个节点与第l+1层第i个节点之间的连接参数(或称权值); 表示第l层第i个偏置节点。这些符号在接下来的前向传播将要用到。
表示第l层第i个偏置节点。这些符号在接下来的前向传播将要用到。
前向传播
虽然标题是《(误差)后向传播神经网络入门》,但这并不意味着可以跳过前向传播的学习。因为如果后向传播对应训练的话,那么前向传播就对应预测(分类),并且训练的时候计算误差也要用到预测的输出值来计算误差。
定义 为第l层第i个节点的激活值(输出值)。当l=1时,
为第l层第i个节点的激活值(输出值)。当l=1时, 。前向传播的目的就是在给定模型参数
。前向传播的目的就是在给定模型参数 的情况下,计算l=2,3,4…层的输出值,直到最后一层就得到最终的输出值。具体怎么算呢,以上图的神经网络模型为例:
的情况下,计算l=2,3,4…层的输出值,直到最后一层就得到最终的输出值。具体怎么算呢,以上图的神经网络模型为例:

这没什么稀奇的,核心思想是这一层的输出乘上相应的权值加上偏置量代入激活函数等于下一层的输入,一句大白话,所谓中文伪码。
另外,追求好看的话可以把括号里面那个老长老长的加权和定义为一个参数: 表示第l层第i个节点的输入加权和,比如
表示第l层第i个节点的输入加权和,比如 。那么该节点的输出可以写作
。那么该节点的输出可以写作 。
。
于是就得到一个好看的形式:

在这个好看的形式下,前向传播可以简明扼要地表示为:

在Python实现中,对应如下方法:
- def runNN(self, inputs):
- """
- 前向传播进行分类
- :param inputs:输入
- :return:类别
- """
- if len(inputs) != self.ni - 1:
- print 'incorrect number of inputs'
-
- for i in range(self.ni - 1):
- self.ai[i] = inputs[i]
-
- for j in range(self.nh):
- sum = 0.0
- for i in range(self.ni):
- sum += ( self.ai[i] * self.wi[i][j] )
- self.ah[j] = sigmoid(sum)
-
- for k in range(self.no):
- sum = 0.0
- for j in range(self.nh):
- sum += ( self.ah[j] * self.wo[j][k] )
- self.ao[k] = sigmoid(sum)
-
- return self.ao
其中,ai、ah、ao分别是输入层、隐藏层、输出层,而wi、wo则分别是输入层到隐藏层、隐藏层到输出层的权值矩阵。在本Python实现中,将偏置量一并放入了矩阵,这样进行线性代数运算就会方便一些。
后向传播
后向传播指的是在训练的时候,根据最终输出的误差来调整倒数第二层、倒数第三层……第一层的参数的过程。
符号定义
在Ryan的讲义中,符号定义与斯坦福前向传播讲义相似但略有不同:
 :第l层第j个节点的输入。
:第l层第j个节点的输入。
 :从第l-1层第i个节点到第l层第j个节点的权值。
:从第l-1层第i个节点到第l层第j个节点的权值。
 :Sigmoid函数。
:Sigmoid函数。
 :第l层第j个节点的偏置。
:第l层第j个节点的偏置。
 :第l层第j个节点的输出。
:第l层第j个节点的输出。
 :输出层第j个节点的目标值(Target value)。
:输出层第j个节点的目标值(Target value)。
输出层权值调整
给定训练集 和模型输出
和模型输出 (这里没有上标l是因为这里在讨论输出层,l是固定的),输出层的输出误差(或称损失函数吧)定义为:
(这里没有上标l是因为这里在讨论输出层,l是固定的),输出层的输出误差(或称损失函数吧)定义为:

其实就是所有实例对应的误差的平方和的一半,训练的目标就是最小化该误差。怎么最小化呢?看损失函数对参数的导数 呗。
呗。
将E的定义代入该导数:

无关变量拿出来:

看到这里大概明白为什么非要把误差定义为误差平方和的一半了吧,就是为了好看,数学家都是外貌协会的。
将 =
= (输出层的输出等于输入代入Sigmoid函数)这个关系代入有:
(输出层的输出等于输入代入Sigmoid函数)这个关系代入有:

对Sigmoid求导有:

要开始耍小把戏了,由于输出层第k个节点的输入 等于上一层第j个节点的输出
等于上一层第j个节点的输出 乘上
乘上 ,即=,而上一层的输出是与到输出层的权值变量无关的,可以看做一个常量,是线性关系。所以对求权值变量
,即=,而上一层的输出是与到输出层的权值变量无关的,可以看做一个常量,是线性关系。所以对求权值变量 的偏导数直接等于,也就是说:
的偏导数直接等于,也就是说: =
= ()=。
()=。
然后将上面用过的=代进去就得到最终的:

为了表述方便将上式记作:

其中:

隐藏层权值调整
依然采用类似的方法求导,只不过求的是关于隐藏层和前一层的权值参数的偏导数:

老样子:

还是老样子:

还是把Sigmoid弄进去:

把=代进去,并且将导数部分拆开:

又要耍把戏了,输出层的输入等于上一层的输出乘以相应的权值,亦即=
 ,于是得到:
,于是得到:

把最后面的导数挪到前面去,接下来要对它动刀了:

再次利用=,这对j也成立,代进去:

再次利用=,j换成i,k换成j也成立,代进去:

利用刚才定义的 ,最终得到:
,最终得到:

其中:
我们还可以仿照的定义来定义一个 ,得到:
,得到:

其中

偏置的调整
因为没有任何节点的输出流向偏置节点,所以偏置节点不存在上层节点到它所对应的权值参数,也就是说不存在关于权值变量的偏导数。虽然没有流入,但是偏置节点依然有输出(总是+1),该输出到下一层某个节点的时候还是会有权值的,对这个权值依然需要更新。
我们可以直接对偏置求导,发现:

原视频中说∂O/∂θ=1,这是不对的,作者也在讲义中修正了这个错误,∂O/∂θ=O(1–O)。
然后再求 ,
, ,后面的导数等于
,后面的导数等于 ,代进去有
,代进去有

其中,
。
后向传播算法步骤
-
随机初始化参数,对输入利用前向传播计算输出。
-
对每个输出节点按照下式计算delta:

-
对每个隐藏节点按照下式计算delta:

-
计算梯度
 ,并更新权值参数和偏置参数:
,并更新权值参数和偏置参数: 。这里的
。这里的 是学习率,影响训练速度。
是学习率,影响训练速度。后向传播算法实现
- def backPropagate(self, targets, N, M):
- """
- 后向传播算法
- :param targets: 实例的类别
- :param N: 本次学习率
- :param M: 上次学习率
- :return: 最终的误差平方和的一半
- """
- # http://www.youtube.com/watch?v=aVId8KMsdUU&feature=BFa&list=LLldMCkmXl4j9_v0HeKdNcRA
- # 计算输出层 deltas
- # dE/dw[j][k] = (t[k] - ao[k]) * s'( SUM( w[j][k]*ah[j] ) ) * ah[j]
- output_deltas = [0.0] * self.no
- for k in range(self.no):
- error = targets[k] - self.ao[k]
- output_deltas[k] = error * dsigmoid(self.ao[k])
- # 更新输出层权值
- for j in range(self.nh):
- for k in range(self.no):
- # output_deltas[k] * self.ah[j] 才是 dError/dweight[j][k]
- change = output_deltas[k] * self.ah[j]
- self.wo[j][k] += N * change + M * self.co[j][k]
- self.co[j][k] = change
- # 计算隐藏层 deltas
- hidden_deltas = [0.0] * self.nh
- for j in range(self.nh):
- error = 0.0
- for k in range(self.no):
- error += output_deltas[k] * self.wo[j][k]
- hidden_deltas[j] = error * dsigmoid(self.ah[j])
- # 更新输入层权值
- for i in range(self.ni):
- for j in range(self.nh):
- change = hidden_deltas[j] * self.ai[i]
- # print 'activation',self.ai[i],'synapse',i,j,'change',change
- self.wi[i][j] += N * change + M * self.ci[i][j]
- self.ci[i][j] = change
- # 计算误差平方和
- # 1/2 是为了好看,**2 是平方
- error = 0.0
- for k in range(len(targets)):
- error = 0.5 * (targets[k] - self.ao[k]) ** 2
- return error
注意不同于上文的单一学习率
,这里有两个学习率N和M。N相当于上文的,而M则是在用上次训练的梯度更新权值时的学习率。这种同时考虑最近两次迭代得到的梯度的方法,可以看做是对单一学习率的改进。另外,这里并没有出现任何更新偏置的操作,为什么?
因为这里的偏置是单独作为一个偏置节点放到输入层里的,它的值(输出,没有输入)固定为1,它的权值已经自动包含在上述权值调整中了。
如果将偏置作为分别绑定到所有神经元的许多值,那么则需要进行偏置调整,而不需要权值调整(此时没有偏置节点)。
哪个方便,当然是前者了,这也导致了大部分神经网络实现都采用前一种做法。
完整的实现
已开源到了Github上:https://github.com/hankcs/neural_net
这一模块的原作者是Neil Schemenauer,我做了些注释。
直接运行bpnn.py即可得到输出:
- Combined error 0.171204877501
- Combined error 0.190866985872
- Combined error 0.126126875154
- Combined error 0.0658488960415
- Combined error 0.0353249077599
- Combined error 0.0214428399072
- Combined error 0.0144886807614
- Combined error 0.0105787745309
- Combined error 0.00816264126944
- Combined error 0.00655731212209
- Combined error 0.00542964723539
- Combined error 0.00460235328667
- Combined error 0.00397407912435
- Combined error 0.00348339081276
- Combined error 0.00309120476889
- Combined error 0.00277163178862
- Combined error 0.00250692771135
- Combined error 0.00228457151714
- Combined error 0.00209550313514
- Combined error 0.00193302192499
- Inputs: [0, 0] --> [0.9982333356008245] Target [1]
- Inputs: [0, 1] --> [0.9647325217906978] Target [1]
- Inputs: [1, 0] --> [0.9627966274767186] Target [1]
- Inputs: [1, 1] --> [0.05966109502803293] Target [0]
IBM利用Neil Schemenauer的这一模块(旧版)做了一个识别代码语言的例子,我将其更新到新版,已经整合到了项目中。
要运行测试的话,执行命令
即可得到输出:
- ERROR_CUTOFF = 0.01
- INPUTS = 20
- ITERATIONS = 1000
- MOMENTUM = 0.1
- TESTSIZE = 500
- OUTPUTS = 3
- TRAINSIZE = 500
- LEARNRATE = 0.5
- HIDDEN = 8
- Targets: [1, 0, 0] -- Errors: (0.000 OK) (0.001 OK) (0.000 OK) -- SUCCESS!
值得一提的是,这里的HIDDEN = 8指的是隐藏层的节点个数,不是层数,层数多了就变成DeepLearning了。
2、一个反向传播的例子
向后传播误差:通过更新权重和反映网络预测误差的偏倚,向后传播误差。
(1)对于输出层单元j, 误差Errj用下式计算
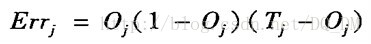
其中,Oj是单元j的实际输出,而 Tj是j给定训练元组的已知目标值。
(2)隐藏层单元j的误差是
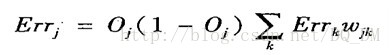
其中, wkj是由下一较高层中单元k到单元j的连接权, 而Errk是单元k的误差。
(3)更新权重和偏倚,以反映传播的误差。
权重由下式更新:

其中,Dwij是权wij的改变量, 变量l是学习率,通常取0.0和1.0之间的常数值。
学习率帮助避免陷入决策空间的局部极小(即权重看上去收敛,但不是最优解),并有助于找到全局最小。如果学习率太低,则学习将进行得很慢。如果学习率太高,则可能出现在不适当的解之间的摆动。
学习率调整规则: 将学习率设置为1/t. 其中t是已对训练样本集迭代的次数。
偏倚由下式更新:
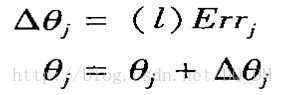
其中, Dqj是偏倚qj的改变
实例更新(case update): 每处理一个样本就更新权值和偏置。
周期更新(epoch update): 权重和偏倚的增量累积到变量中,处理完训练集中的所有样本之后再更新权值和偏置。
其中,扫描训练集的一次迭代是一个周期。
理论上,后向传播的数学推导使用周期更新,而在实践中,实例更新更常见,因为它通常产生更准确的结果。
终止条件:
(1)前一周期所有的Dwij都小于某个指定的阈值, 或
(2)前一周期未正确分类的元组百分比小于某个阈值, 或
(3)超过预先指定的周期数
实践中,权重收敛可能需要数十万个周期。
后向传播算法学习的样本计算(例子):
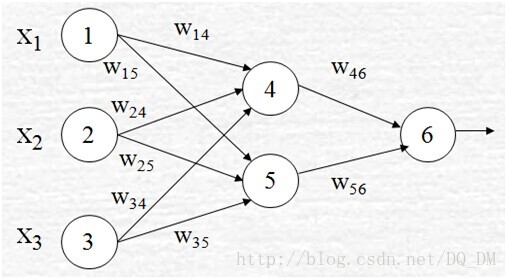
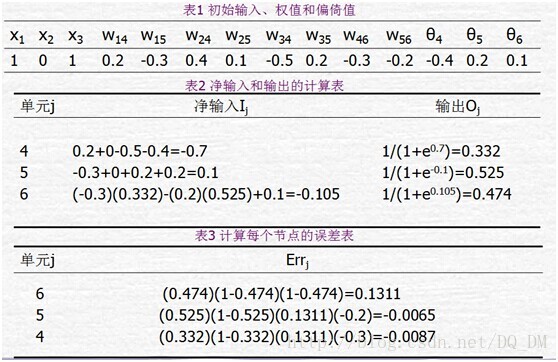
下图给出了一个多层前馈神经网路。令学习率l=0.9。该网络的初始权重和偏倚值在表1中给出,第一个训练元组为X={1,0,1},其类标号为1。
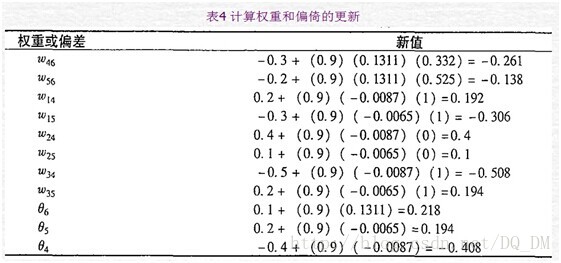
给定第一个训练元组X,,该例展示向后传播计算。首先把该元组提供给网络,计算每个单元的净输入和输出,这些值显示在表2中。计算每个单元的误差,并向后传播,误差值显示在表3中。权重和偏倚的更新显示在表4中。
3、CNN简介
cnn的系列文章可以参见 http://blog.csdn.net/u010555688/article/details/24848367
其中,LeNet-5的相关介绍,我摘抄如下:
在经典的模式识别中,一般是事先提取特征。提取诸多特征后,要对这些特征进行相关性分析,找到最能代表字符的特征,去掉对分类无关和自相关的特征。然而,这些特征的提取太过依赖人的经验和主观意识,提取到的特征的不同对分类性能影响很大,甚至提取的特征的顺序也会影响最后的分类性能。同时,图像预处理的好坏也会影响到提取的特征。那么,如何把特征提取这一过程作为一个自适应、自学习的过程,通过机器学习找到分类性能最优的特征呢?
卷积神经元每一个隐层的单元提取图像局部特征,将其映射成一个平面,特征映射函数采用 sigmoid 函数作为卷积网络的激活函数,使得特征映射具有位移不变性。每个神经元与前一层的局部感受野相连。注意前面我们说了,不是局部连接的神经元权值相同,而是同一平面层的神经元权值相同,有相同程度的位移、旋转不变性。每个特征提取后都紧跟着一个用来求局部平均与二次提取的亚取样层。这种特有的两次特征提取结构使得网络对输入样本有较高的畸变容忍能力。也就是说,卷积神经网络通过局部感受野、共享权值和亚取样来保证图像对位移、缩放、扭曲的鲁棒性。
文字识别系统LeNet-5
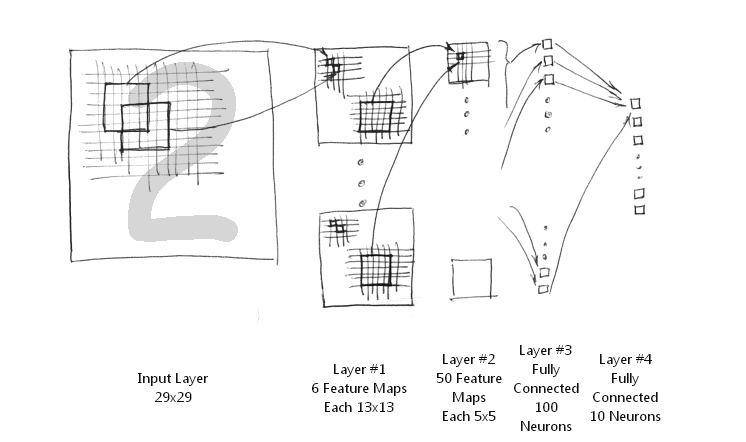
一种典型的用来识别数字的卷积网络是LeNet-5(效果和paper等见这)。当年美国大多数银行就是用它来识别支票上面的手写数字的。能够达到这种商用的地步,它的准确性可想而知。毕竟目前学术界和工业界的结合是最受争议的。
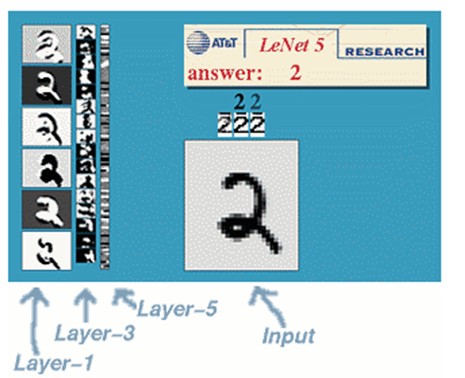
那下面咱们也用这个例子来说明下。
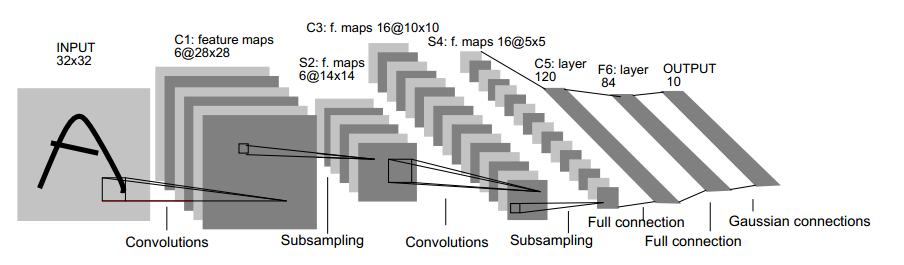
LeNet-5共有7层,不包含输入,每层都包含可训练参数(连接权重)。输入图像为32*32大小。这要比Mnist数据库(一个公认的手写数据库)中最大的字母还大。这样做的原因是希望潜在的明显特征如笔画断电或角点能够出现在最高层特征监测子感受野的中心。
首先,简要解释下上面这个用于文字识别的LeNet-5深层卷积网络:
1. 输入图像是32x32的大小,局部滑动窗的大小是5x5的,由于不考虑对图像的边界进行拓展,则滑动窗将有28x28个不同的位置,也就是C1层的大小是28x28。这里设定有6个不同的C1层,每一个C1层内的权值是相同的。
2. S2层是一个下采样层。简单的说,由4个点下采样为1个点,也就是4个数的加权平均。但在LeNet-5系统,下采样层比较复杂,因为这4个加权系数也需要学习得到,这显然增加了模型的复杂度。在斯坦福关于深度学习的教程中,这个过程叫做Pool。
3. 根据对前面C1层同样的理解,我们很容易得到C3层的大小为10x10. 只不过,C3层的变成了16个10x10网络! 试想一下,如果S2层只有1个平面,那么由S2层得到C3就和由输入层得到C1层是完全一样的。但是,S2层由多层,那么,我们只需要按照一定的顺利组合这些层就可以了。具体的组合规则,在 LeNet-5 系统中给出了下面的表格:
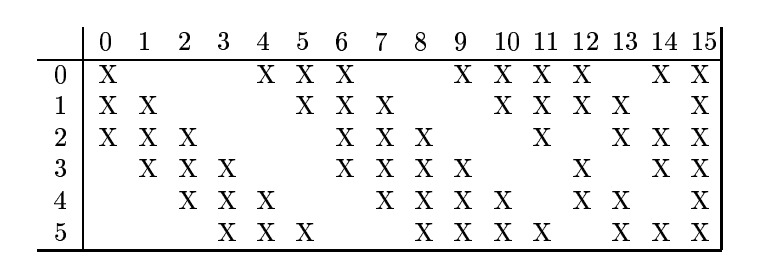
简单的说,例如对于C3层第0张特征图,其每一个节点与S2层的第0张特征图,第1张特征图,第2张特征图,总共3个5x5个节点相连接。后面依次类推,C3层每一张特征映射图的权值是相同的。
4. S4 层是在C3层基础上下采样,前面已述。在后面的层由于每一层节点个数比较少,都是全连接层,这个比较简单,不再赘述。
涉及问题:
1、每个图如何卷积:
(1)一个图如何变成几个?
(2)卷积核如何选择?
2、节点之间如何连接?
3、S2-C3如何进行分配?
4、16-120全连接如何连接?
5、最后output输出什么形式?
①各个层解释:
我们先要明确一点:每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。
(1) C1层是一个卷积层(为什么是卷积?卷积运算一个重要的特点就是,通过卷积运算,可以使原信号特征增强,并且降低噪音),由6个特征图Feature Map构成。特征图中每个神经元与输入中5*5的邻域相连。特征图的大小为28*28,这样能防止输入的连接掉到边界之外(是为了BP反馈时的计算,不致梯度损失,个人见解)。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。
(2) S2层是一个下采样层(为什么是下采样?利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息),有6个14*14的特征图。特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数计算。可训练系数和偏置控制着sigmoid函数的非线性程度。如果系数比较小,那么运算近似于线性运算,亚采样相当于模糊图像。如果系数比较大,根据偏置的大小亚采样可以被看成是有噪声的“或”运算或者有噪声的“与”运算。每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。S2层有12个可训练参数和5880个连接。
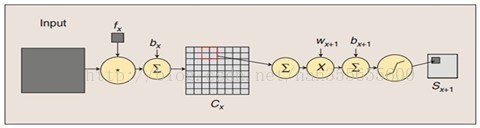
图:卷积和子采样过程:卷积过程包括:用一个可训练的滤波器fx去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征map了),然后加一个偏置bx,得到卷积层Cx。子采样过程包括:每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个大概缩小四倍的特征映射图Sx+1。
所以从一个平面到下一个平面的映射可以看作是作卷积运算,S-层可看作是模糊滤波器,起到二次特征提取的作用。隐层与隐层之间空间分辨率递减,而每层所含的平面数递增,这样可用于检测更多的特征信息。
(3) C3层也是一个卷积层,它同样通过5x5的卷积核去卷积层S2,然后得到的特征map就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征map了。这里需要注意的一点是:C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合(这个做法也并不是唯一的)。(看到没有,这里是组合,就像之前聊到的人的视觉系统一样,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分)。
刚才说C3中每个特征图由S2中所有6个或者几个特征map组合而成。为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。第一,不完全的连接机制将连接的数量保持在合理的范围内。第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。
例如,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。这样C3层有1516个可训练参数和151600个连接。
(4) S4层是一个下采样层,由16个5*5大小的特征图构成。特征图中的每个单元与C3中相应特征图的2*2邻域相连接,跟C1和S2之间的连接一样。S4层有32个可训练参数(每个特征图1个因子和一个偏置)和2000个连接。
(5) C5层是一个卷积层,有120个特征图。每个单元与S4层的全部16个单元的5*5邻域相连。由于S4层特征图的大小也为5*5(同滤波器一样),故C5特征图的大小为1*1:这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层而非全相联层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1*1大。C5层有48120个可训练连接。
(6) F6层有84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有10164个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给sigmoid函数产生单元i的一个状态。
(7) 最后,输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
用这种分布编码而非更常用的“1 of N”编码用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。原因是大多数时间非分布编码的输出必须为0。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目标。因为与sigmoid不同,他们在输入空间的较好限制的区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大弯曲的点处。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。
②问题讲解
第一个问题:
(1)输入-C1
用6个5*5大小的patch(即权值,训练得到,随机初始化,在训练过程中调节)对32*32图片进行卷积,得到6个特征图。
(2)S2-C3
C3那16张10*10大小的特征图是怎么来?

将S2的特征图用1个输入层为150(=5*5*6,不是5*5)个节点,输出层为16个节点的网络进行convolution。
该第3号特征图的值(假设为H3)是怎么得到的呢?
首先我们把网络150-16(以后这样表示,表面输入层节点为150,隐含层节点为16)中输入的150个节点分成6个部分,每个部分为连续的25个节点。取出倒数第3个部分的节点(为25个),且同时是与隐含层16个节点中的第4(因为对应的是3号,从0开始计数的)个相连的那25个值,reshape为5*5大小,用这个5*5大小的特征patch去convolution S2网络中的倒数第3个特征图,假设得到的结果特征图为h1。
同理,取出网络150-16中输入的倒数第2个部分的节点(为25个),且同时是与隐含层16个节点中的第5个相连的那25个值,reshape为5*5大小,用这个5*5大小的特征patch去convolution S2网络中的倒数第2个特征图,假设得到的结果特征图为h2。
最后,取出网络150-16中输入的最后1个部分的节点(为25个),且同时是与隐含层16个节点中的第5个相连的那25个值,reshape为5*5大小,用这个5*5大小的特征patch去convolution S2网络中的最后1个特征图,假设得到的结果特征图为h3。
最后将h1,h2,h3这3个矩阵相加得到新矩阵h,并且对h中每个元素加上一个偏移量b,且通过sigmoid的激发函数,即可得到我们要的特征图H3了。
第二个问题:
上图S2中为什么是150个节点?(涉及到权值共享和参数减少)
CNN一个牛逼的地方就在于通过感受野和权值共享减少了神经网络需要训练的参数的个数。
下图左:如果我们有1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话(每个隐层神经元都连接图像的每一个像素点),就有1000x1000x1000000=10^12个连接,也就是10^12个权值参数。然而图像的空间联系是局部的,就像人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样,我们就可以减少连接的数目,也就是减少神经网络需要训练的权值参数的个数了。如下图右:假如局部感受野是10x10,隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。比原来减少了四个0(数量级),这样训练起来就没那么费力了,但还是感觉很多的啊,那还有啥办法没?
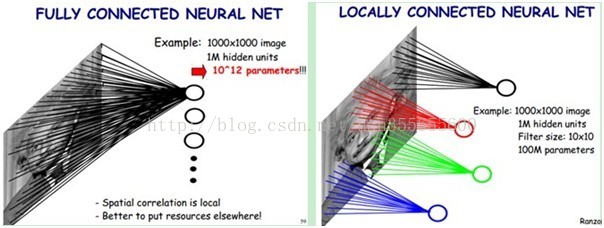
我们知道,隐含层的每一个神经元都连接10x10个图像区域,也就是说每一个神经元存在10x10=100个连接权值参数。那如果我们每个神经元这100个参数是相同的呢?也就是说每个神经元用的是同一个卷积核去卷积图像。这样我们就只有多少个参数??只有100个参数啊!!!亲!不管你隐层的神经元个数有多少,两层间的连接我只有100个参数啊!亲!这就是权值共享啊!亲!这就是卷积神经网络的主打卖点啊!亲!(有点烦了,呵呵)也许你会问,这样做靠谱吗?为什么可行呢?这个……共同学习。
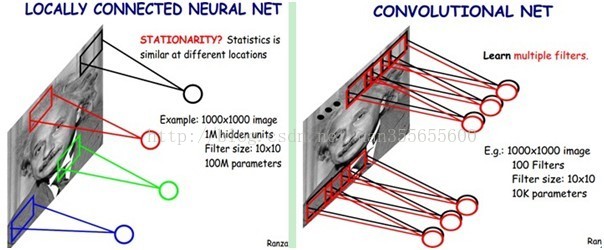
好了,你就会想,这样提取特征也忒不靠谱吧,这样你只提取了一种特征啊?对了,真聪明,我们需要提取多种特征对不?假如一种滤波器,也就是一种卷积核就是提出图像的一种特征,例如某个方向的边缘。那么我们需要提取不同的特征,怎么办,加多几种滤波器不就行了吗?对了。所以假设我们加到100种滤波器,每种滤波器的参数不一样,表示它提出输入图像的不同特征,例如不同的边缘。这样每种滤波器去卷积图像就得到对图像的不同特征的放映,我们称之为Feature Map。所以100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元。到这个时候明了了吧。我们这一层有多少个参数了?100种卷积核x每种卷积核共享100个参数=100x100=10K,也就是1万个参数。才1万个参数啊!亲!(又来了,受不了了!)见下图右:不同的颜色表达不同的滤波器。
嘿哟,遗漏一个问题了。刚才说隐层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。那么隐层的神经元个数怎么确定呢?它和原图像,也就是输入的大小(神经元个数)、滤波器的大小和滤波器在图像中的滑动步长都有关!例如,我的图像是1000x1000像素,而滤波器大小是10x10,假设滤波器没有重叠,也就是步长为10,这样隐层的神经元个数就是(1000x1000 )/ (10x10)=100x100个神经元了,假设步长是8,也就是卷积核会重叠两个像素,那么……我就不算了,思想懂了就好。注意了,这只是一种滤波器,也就是一个Feature Map的神经元个数哦,如果100个Feature Map就是100倍了。由此可见,图像越大,神经元个数和需要训练的权值参数个数的贫富差距就越大。
所以这里可以知道刚刚14*14的图像计算它的节点,按步长为3计算,则一幅图可得5*5个神经元个数,乘以6得到150个神经元个数。
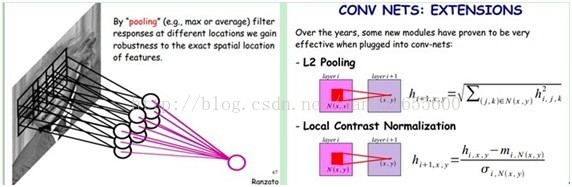
需要注意的一点是,上面的讨论都没有考虑每个神经元的偏置部分。所以权值个数需要加1 。这个也是同一种滤波器共享的。
总之,卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。
第三个问题:

如果C1层减少为4个特征图,同样的S2也减少为4个特征图,与之对应的C3和S4减少为11个特征图,则C3和S2连接情况如图:

第四个问题:
全连接:
C5对C4层进行卷积操作,采用全连接方式,即每个C5中的卷积核均在S4所有16个特征图上进行卷积操作。
第五个问题:
采用one-of-c的方式,在输出结果的1*10的向量中最大分量对应位置极为网络输出的分类结果。对于训练集的标签也采用同样的方式编码,例如1000000000,则表明是数字0的分类。
简化的LeNet-5系统
http://www.hankcs.com/ml/back-propagation-neural-network.html
http://blog.csdn.net/dq_dm/article/details/38382193
http://blog.csdn.net/xinzhangyanxiang/article/list/3
http://blog.csdn.net/u013007900/article/details/51419257
http://www.jeyzhang.com/cnn-learning-notes-1.html














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









