







 本文介绍了使用CRNN(卷积循环神经网络)结合CTC(连接istime分类器)进行文字识别的实践过程,涵盖了数据集构造、模型训练以及如何加载模型识别图片。提供了完整的代码资源,适用于处理不定长文字的识别任务。
本文介绍了使用CRNN(卷积循环神经网络)结合CTC(连接istime分类器)进行文字识别的实践过程,涵盖了数据集构造、模型训练以及如何加载模型识别图片。提供了完整的代码资源,适用于处理不定长文字的识别任务。
前言
提示:这里可以添加本文要记录的大概内容:
文字识别可根据待识别的文字特点采用不同的识别方法,一般分为定长文字、不定长文字两大类别。
- 定长文字(例如验证码),由于字符数量固定,采用的网络结构相对简单,识别也比较容易;
- 不定长文字(例如印刷文字、广告牌文字等),由于字符数量是不固定的,因此需要采用比较复杂的网络结构和后处理环节,识别也具有一定的难度。
提示:以下是本篇文章正文内容,下面案例可供参考
环境
- ubuntu 18.05
- pytorch 最新版
- CUDA 11.2
- 其他基本环境配置 (pandas、numpy、opencv、PILLow)
一、数据集
我们需要的数据集是这样的,他是一个txt文本,里面是以image,str(图片内容文本)
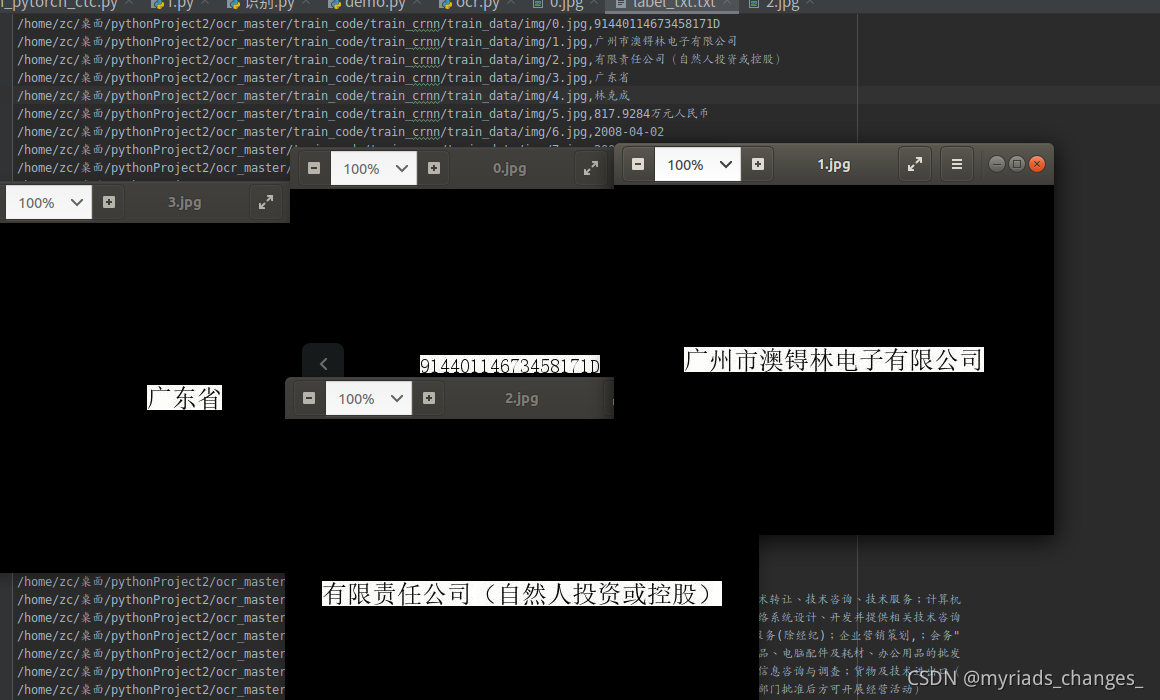
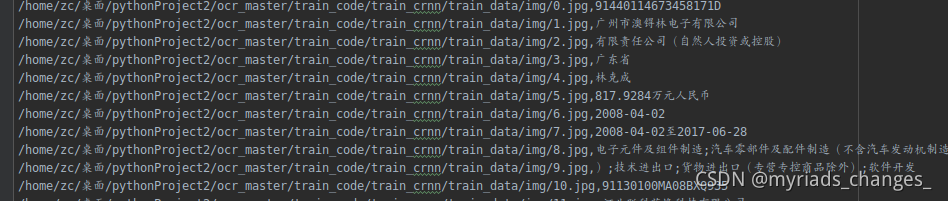
二、数据集构造
对于数据构造的话,就需要在原始的图片上面去截取,保存
在这里我们需要创建两个数据集训练集和验证集
代码如下(示例):
import os
import cv2
import pandas as pd
import csv
img_list= os.listdir('imgs')#图片路径
"""
这里可能就有些不一样了,本人是一张图片对应一个坐标文件
"""
txt_list = os.listdir('/home/zc/桌面/pythonProject2/坐标')
f = open('/home/zc/桌面/pythonProject2/ocr_master/train_code/train_crnn/train_data/val_txt/label_txt.txt','a',newline='')
wi = csv.writer(f)
num = 0
for i in txt_list[:50]:
a = i[:-4]
data = pd.read_csv('/home/zc/桌面/pythonProject2/坐标/{}'.format(i),header=None)
img = cv2.imread('imgs/{}.jpg'.format(a))
for j in range(len(data)):
x1,y1 = data.loc[j][0],data.loc[j][1]
x2,y2 = data.loc[j][6],data.loc[j][7]
txt_str = data.loc[j][8]
im = img[y1:y2,x1:x2]
if num==750:
print(im.shape)
if im.shape==(0, 0, 3):
continue
cv2.imwrite('/home/zc/桌面/pythonProject2/ocr_master/train_code/train_crnn/train_data/val_img/{}.jpg'.format(num),im)
wi.writerow(['/home/zc/桌面/pythonProject2/ocr_master/train_code/train_crnn/train_data/val_img/{}.jpg'.format(num),txt_str])
num += 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2467
2467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









