




 KMP算法是一种高效的字符串匹配算法,避免了朴素匹配的冗余比较。本文提供KMP算法的基本思路和应用,适合初学者理解。通过构建预处理数组π,可以确定模式在不匹配时应移动的步数,降低时间复杂度。
KMP算法是一种高效的字符串匹配算法,避免了朴素匹配的冗余比较。本文提供KMP算法的基本思路和应用,适合初学者理解。通过构建预处理数组π,可以确定模式在不匹配时应移动的步数,降低时间复杂度。
KMP算法是迄今为止最为高效的字符串匹配算法。当然,在KMP算法出现之前,有关字符串的匹配问题当然经过了一个漫长的探索过程。从一开始最简单的朴素字符串匹配算法,到Rabin-Karp算法,再到有限自动机算法等等,可以说任何一个伟大算法的诞生都不可能是一朝一夕之功,在它之前一定有大量的理论及实验的基础。所以,想要彻底理解KMP算法最好是从头开始,对整个字符串的匹配问题有个完整的了解。
但是,我在这篇博文中讲的却是对KMP算法最简单的理解。只能帮助大家了解KMP最基本的思路和应用。若要详细了解,推荐《算法导论》中的“字符串匹配”一节。我没有见过比这一章讲解得更详细的资料了。
所谓字符串匹配,解决的问题就是在一段文本(text)之中寻找我们要匹配的模式(pattern)。文本和模式都是由字符串构成的,模式的长度<=文本的长度。例如,模式为”aba”,文本为”abcbaba”,所谓字符串匹配就是在文本中查找模式出现的位置(一般以文本成功匹配的字段的第一个字符的位置表示),这里应该返回4。
一种比较简单的办法是朴素字符串匹配,就是一个字符一个字符去匹配。比如上面这个例子,一开始对文本和模式都是从头开始匹配,效果如下图:
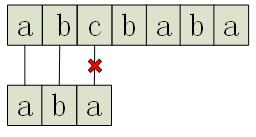
我们发现,第三个字符处文本为”c”,而模式为”a”,于是匹配失败。那么接下来,自然而然就能想到,把整个模式向右平移一位,再次进行匹配:
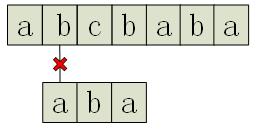
很遗憾,这次模式的第一个字符就没能匹配成功。这样,每次向后移动一位,依次匹配,若出现某一时刻模式的全部字符都能和它当时所对应的文本匹配,则匹配成功一次;继续向后,直到模式的第一个字符对应的是文本的第(n - m + 1)个字符为止(其中,n为文本长度,m为字符串长度),匹配结束。也就是说当模式的最后一个字符对应的是文本的最后一个字符时,就自然没有必要再进行匹配了。
通过时间复杂度分析,可知朴素匹配算法的时间复杂度为O((n−m+1)m)O((n−m+1)m). 但是这个里面有个问题,就是其实我们没有必要在一次匹配失败(成功)之后,向右移动一位继续。而可以向右移动不止一位。
为什么呢?还是看上面的例子,第一次匹配是,模式的第三个字符没有和文本匹配,那同时也就说明了模式的前两位和对应的文本是匹配的。我们可以确定模式未匹配的那一位所对应的文本的前一位(这里就是文本的第二位)是b。而模式的第一位是a,那么,显然,a与b不同,往后移动一位让a与b匹配就是多余的,没有必要的。
那么应该往后移动几位呢?可以想象,假如模式的第 i 位不能匹配,那么,就需要移动模式,使得模式的前k位成为模式前 i - 1 位的后缀(k在此是个小于 i 的)。
先说明一下字符串的前缀,后缀:比如字符串”abcde”中, “a”, “ab”, “abc”等等都是前缀,而”cde”, “de”, “e” 等等都是后缀。也就是说,从字符串头开始截任意小于等于字符串长度的字符,就是前缀,而从后开始截任意长度就是后缀。
回到刚才的问题,为了能够实现可能的匹配,需要模式向右偏移,使得模式以“最长的头”匹配上刚才已经匹配的文本字段的尾。也就是说寻找模式的前 i -1 项的后缀中能成为模式的最长前缀的部分。而如果后缀中找不到前缀,则将模式偏移 i 位即可。话有点抽象,看看这个例子:文本”ababababc”,模式”ababc”
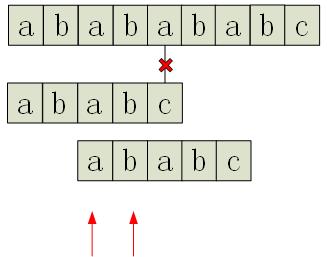
同样的,第一次匹配在模式的第5个字符处失败,但是此时并没有从后面一个字符开始重新匹配,而是向右移动两位,为什么是两位呢,我们可以观察一下红箭头指的两位,因为模式的第5位匹配失败,所以,现在我们看看能否在在模式前4位的后缀中找到模式的前缀,刚好,字符串”ab”可以作为模式前4位的后缀,同时也是模式的前缀(后缀中最长的前缀)。不难发现,只有这样,才能使得这一次匹配是“可能有意义”的。
换句话说,可以通过对模式本身的计算,得出一个数组ππ,其中π[index]π[index]告诉我们,如果模式的第indexindex位不能和文本匹配时,模式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









