







本文标题大纲:
前言
在上篇文章:Java 多线程—线程池(上) 中我们看了一下 Java 中的阻塞队列,我们知道阻塞队列是一种可以对线程进行阻塞控制的队列,并且在前面我们也使用了阻塞队列来实现 生产者-消费者模型 。在文章最后,我们还看了一下 Future 接口和其中对应的方法,如果你对这些不熟悉,建议先去看一下上一篇文章。有了前面的知识作为基础之后,我们来正式看一下 Java 中的线程池。
线程池的作用
首先来看一下线程池的作用:Java 已经给我们提供了多线程机制,那么线程池是为了解决什么问题呢?
我们设想一下:假设现在我们打算使用 Java 编写一个服务器端的程序,那么对于每个用户的请求,为了提高服务器资源的利用率和用户请求的响应速度,我们可能会采用给每一个用户请求都新建一个线程来处理这个请求并且在处理完成之后返回响应,那么这样的话可能会带来一个问题:假设用户的访问非常频繁,并且每次请求的资源都是比较简单的,即对于每个请求,服务器可能只需要很少的资源就可以处理好,那么此时频繁的创建新线程来处理用户请求就可能会导致创建和销毁线程所带来的服务器资源开销本身就大于处理用户请求的开销了。这样的话明显得不偿失。
那么使用线程池能够解决这个问题吗?答案是可以。线程池可以理解成一个处理任务的线程集合,其中的线程有一个特点是:在某个线程处理完成某个任务之后并不会立即被销毁,而是会保留一段时间(这个取决于不同种类的线程池的不同实现),而如果之后又有任务来了,那么线程就会处理之后来的任务。这样的话就避免了只通过一味的创建新线程来处理任务的缺陷。而线程池本身也是适用于处理那些任务繁多并且每个任务比较简单(相对而言)的情景。我们来通过一幅图来理解一下线程池工作的基本原理:
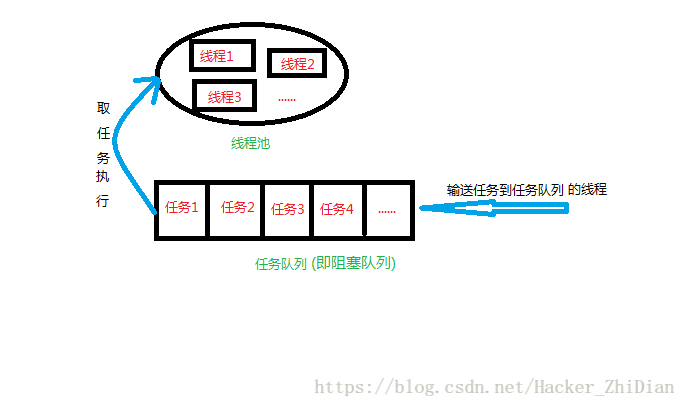
其中的任务队列即为阻塞队列,当然这只是代表线程池的基本原理,对于不同设计理念的线程池在具体实现上肯定会有所差异。下面来看一下 Java 中的线程池。
源码解析线程池
Java 中提供了一个 Executors 类,这个类类似于线程池的工厂,我们可以通过它来创建各类线程池,我们看看其中的一些方法:
public class Executors {
// ....
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
// ....
}我们会发现 Executors 提供了大多数创建线程池的方法最后都是返回一个新的 ThreadPoolExecutor 对象,我们来重点看一下 ThreadPoolExecutor 类:
public class ThreadPoolExecutor extends AbstractExecutorService {
// ...
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
// ...
}我截取了这个类中带有 7 个参数的构造方法,这个类提供了多个构造方法,但是终究是调用了这个带有 7 个参数的构造方法,我们来分析一下这个构造方法:
在此之前,我们还得再仔细了解一下 Java 中线程池的原理,相比在文章开头提供的那副图中解释的线程池原理,Java 提供的线程池原理更加复杂一些,Java 中线程池中的线程分为 核心线程 和 非核心线程 两种,两者有什么却别呢?
我们知道:一个线程池中提供的线程的数量是有限的,而在有新任务添加到线程池中时,如果线程中的核心线程数没有到达规定的核心线程最大数,那么便会创建新的核心线程来执行任务,否则的话就会把任务附加到 任务队列 的末尾,对于这个操作也有两种可能:如果任务队列未满,那么将任务添加到任务队列中,否则的话就会创建非核心线程来执行任务。那么如果非核心线程的数量也达到了最大值呢?这个时候线程池就会执行 饱和策略 了。这个过程可以通过下面的图来描述:
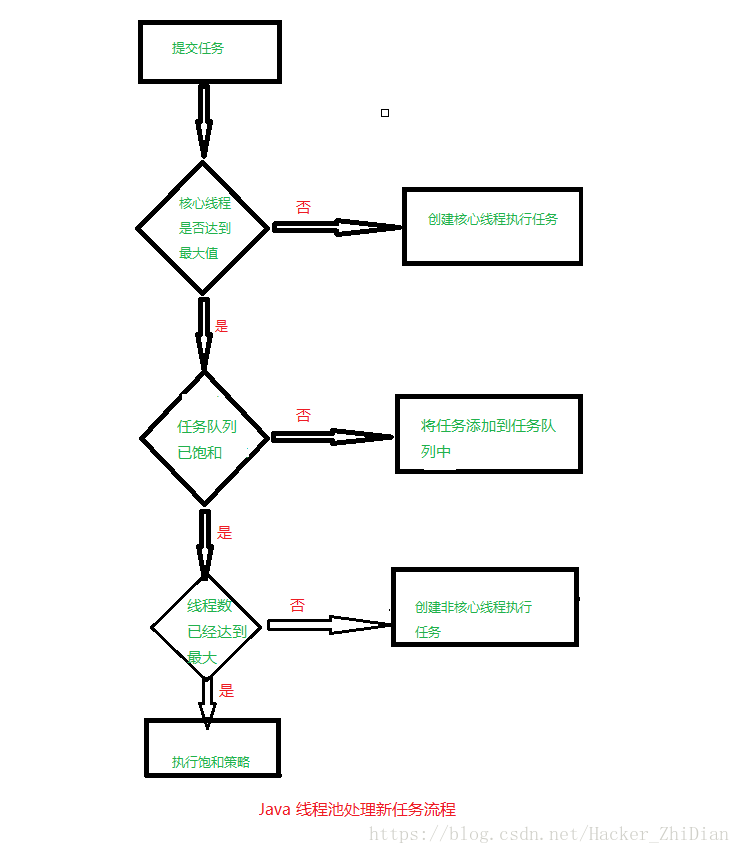
理解这个过程之后,下面回到这个类的构造方法中,我们再来看这个类的构造方法的参数:
corePoolSize:线程池中的最大核心线程数,默认情况下线程池是空的,没有线程,
只有在有任务提交到线程池中时才会创建线程,如果调用线程池对象的 prestartAllCoreThread() 方法,
那么线程池会提前创建好所有的核心线程。
maximumPoolSize:线程池中允许创建的最大线程数,
上文所说的非核心线程数为 maximumPoolSize - corePoolSize ,即为最大线程数减去核心线程数。
keepAliveTime:线程池中非核心线程允许闲置的最长时间,
超过这个时间的非核心线程将会被回收,对于任务很多并且每个任务处理时间较短的的情况,
可以适当提升 keepAliveTime 参数来提高线程利用率。
当设置 allowCoreThreadTimeOut 属性为 true时,keepAliveTime 参数也会作用到核心线程上。
unit:keepAliveTime 参数的时间单位
(天:DAYS、小时:HOURS、分钟:MINUTES、秒:SECONDS、毫秒:MILLISENDS 等)
workQueue:任务队列,储存任务的阻塞队列,上篇文章中有介绍
threadFactory:创建线程的工厂,一般情况使用默认的即可
handler:饱和策略,即为当任务队列和线程池中线程数均达到饱和时采取的应对策略,
默认是 AbordPolicy,表示无法处理新的任务,
并在有新任务提交时抛出 RejectedExecutionException 异常,此外还有 3 中策略:
1、CallerRunnsPolicy:使用提交该任务的线程来处理此任务
2、DiscardPolicy:不执行该任务,并将该任务删除
3、DiscardOldestPolicy:丢弃队列中最近的任务,并执行当前提交的任务除去看构造方法之外,在类的声明中,我们发现,ThreadPoolExecutor 继承于 AbstractExecutorService 类,我们先一步步向上追溯到本源,我们来看看 AbstractExecutorService 这个类:
public abstract class AbstractExecutorService implements ExecutorService {
// ......
}注意到这是个抽象类,这个类实现了 ExecutorService 接口,还是继续看一下这个接口吧:
public interface Execut 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1652
1652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









