









直观来说,牛顿法因为使用了二阶导信息,比单纯的一阶导数的梯度下降法,其发现极值点回收敛得更快。
我个人的理解,梯度下降考虑了函数值下降最快的方向(梯度方向)。而在有些情况下,按这样的规则改变自变量取值,可能会走弯路。
其根本原因在于,梯度下降法,能够保证函数值在改点处的变化最快方向,但不能保证梯度本身向着最快变化方向变动。
大家经常见到的示意图长这样:
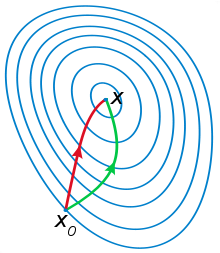
绿色的是梯度下降法,而红色的是牛顿法。这张示意图的目的就在于,说明牛顿法能够向极值点收敛得更快。
梯度下降法,就好比从当前所在位置往负梯度方向走,能够让函数变小的速度最快,但是这个方向却不一定是梯度本身往0变化最快的。
牛顿法的优势便在于,能够确保自变量取值变化的范围向着梯度本身向0变化最快的方向走,从而直捣黄龙。
想象一下,上图中的x0点处,绿线方向是坡度最大的方向,看起来往这个方向走能最快到达坑底。而红线方向,虽然现在看起来前面只是一个缓坡,但实际上过了这个缓坡,前面就是一个大的悬崖。说白了就是,梯度无法给出除了x0点周围一块地方以外更远处的信息,而二阶导却可以。这里不考虑悬崖可不可导和会不会摔死的问题……
当然了,更多的信息也有更大的代价:牛顿法要计算二阶导,这在高维数据时将非常耗费资源,额外信息的获取都是需要成本的。还有可能会碰到函数二阶导数不存在的问题。针对于这两个问题,拟牛顿法放松了假设,并以近似的方式取得二阶导(Hessian矩阵),具体的我将在后面的文章中再给到。















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









