






java中数据类型分为两大类”:基本类型与引用类型。Java的9种基本类型的变量称为基本类型变量,而类、接口、数组、枚举和注解5种是引用类型变量。这两种类型变量的结构和含义不同,系统对他们的处理也不相同。
基本类型(primitive type)
long l=2L;
double d =1.0
基本类型(primitive type)
基本数据类型的变量包含了单个值,这个值的长度和格式符合变量所属数据类型的要求,可以是一个数字、一个字符或一个布尔值,例如一个整型值是32位的二进制补码格式的数据,而一个字符型的值是16位的Unicode字符格式的数据等,逻辑性(boolean)文本型(char)整型(byte,short,int,long)浮点型(double,float),还有一个类似基本类型的void,其对应的的包装类为Void。
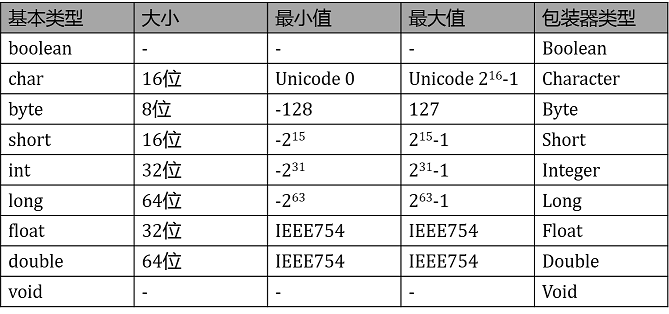
注意1:在字符型变量中又存在代码点和代码单元的概念 。如果基本的数据整数和浮点数精度不能够满足需求,那么可以使用java.math包中的两个很有用的类:BigInteger和BigDecimal。
注意2:其他的如相互计算,会低范围先转换为高范围,这个转换的过程是在表达式中依次转换。见此文
int i = 1;long l=2L;
double d =1.0
double result = i+l+d;这个过程是i+l的时候i先转换为long类型,结果为long类型,再转换为double类型。
注意3:三目运算符的后两个表达式需要类型相同。
int a=4;System.out.println(a>5?9.9:9)输出的是9.0。
注意4:Java之所以没有放弃基本数据类型,而全面使用对象的原因主要还是在效率的考虑上。
注意5:其中double和long型,在运算时是拆成两个32位进行运算的,所以像如下语句在多线程情况下,无法保证原子性。
int i = 10;//原子性
long l = 100L;//非原子性
注意6:介绍一下拆箱和装箱的问题。
Integer ia47 = new Integer(47);
Integer ib47 = new Integer(47);
System.out.println(ia47 == ib47);
ia47 = Integer.valueOf(47);
ib47 = Integer.valueOf(47);
System.out.println(ia47 == ib47);
上面这段代码的输出是false true。第一个输出为false很显然,第二个输出为true的原因是因为jvm做了缓存,因为Integer是不可变类。做缓存不会带来什么副作用。从源码来剖析更容易明白。见源码
/**
* Returns an {@code Integer} instance representing the specified
* {@code int} value. If a new {@code Integer} instance is not
* required, this method should generally be used in preference to
* the constructor {@link #Integer(int)}, as this method is likely
* to yield significantly better space and time performance by
* caching frequently requested values.
*
* This method will always cache values in the range -128 to 127,
* inclusive, and may cache other values outside of this range.
*
* @param i an {@code int} value.
* @return an {@code Integer} instance representing {@code i}.
* @since 1.5
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}














 8589
8589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









