









问题阐述:
对于很多应用而言,都需要搜集一些资讯内容充实自己的内容,这样可以丰富站点内容,增加用户停留的时间。
最原始的办法,莫过于复制粘贴,但是,当如果目标网站是几个,甚至几十个的时候,复制粘贴并不是长久之计,劳心劳力,又容易搞错。所以基于程序的数据爬取就十分重要。但是几乎每个网站,都有他独特的结构,看起来要针对每个网站独特的结构,来写一套东西,但是这样拓展性也很差。
这里我介绍一下,我所实现的资讯爬取程序。我的程序主要针对列表和详情结构这样的资讯内容。举个例子
如下网页是一个有列表目录的网页。当然这个页面可能是一个类型的资讯内容
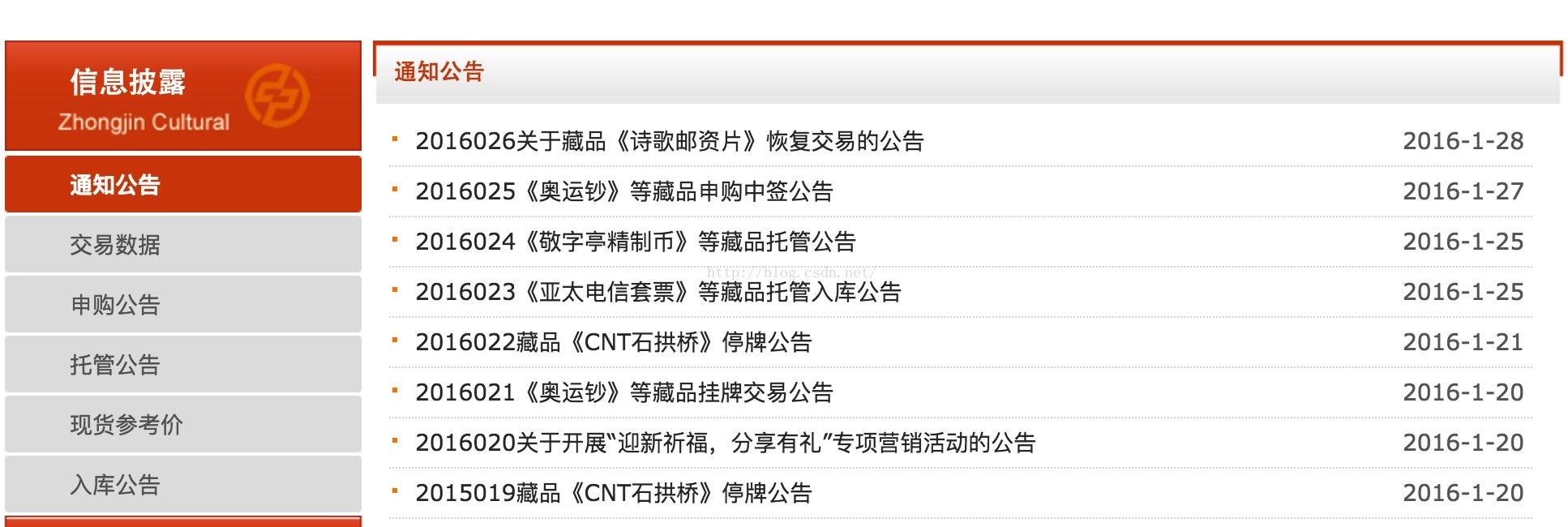
点击后,会进入详情页面
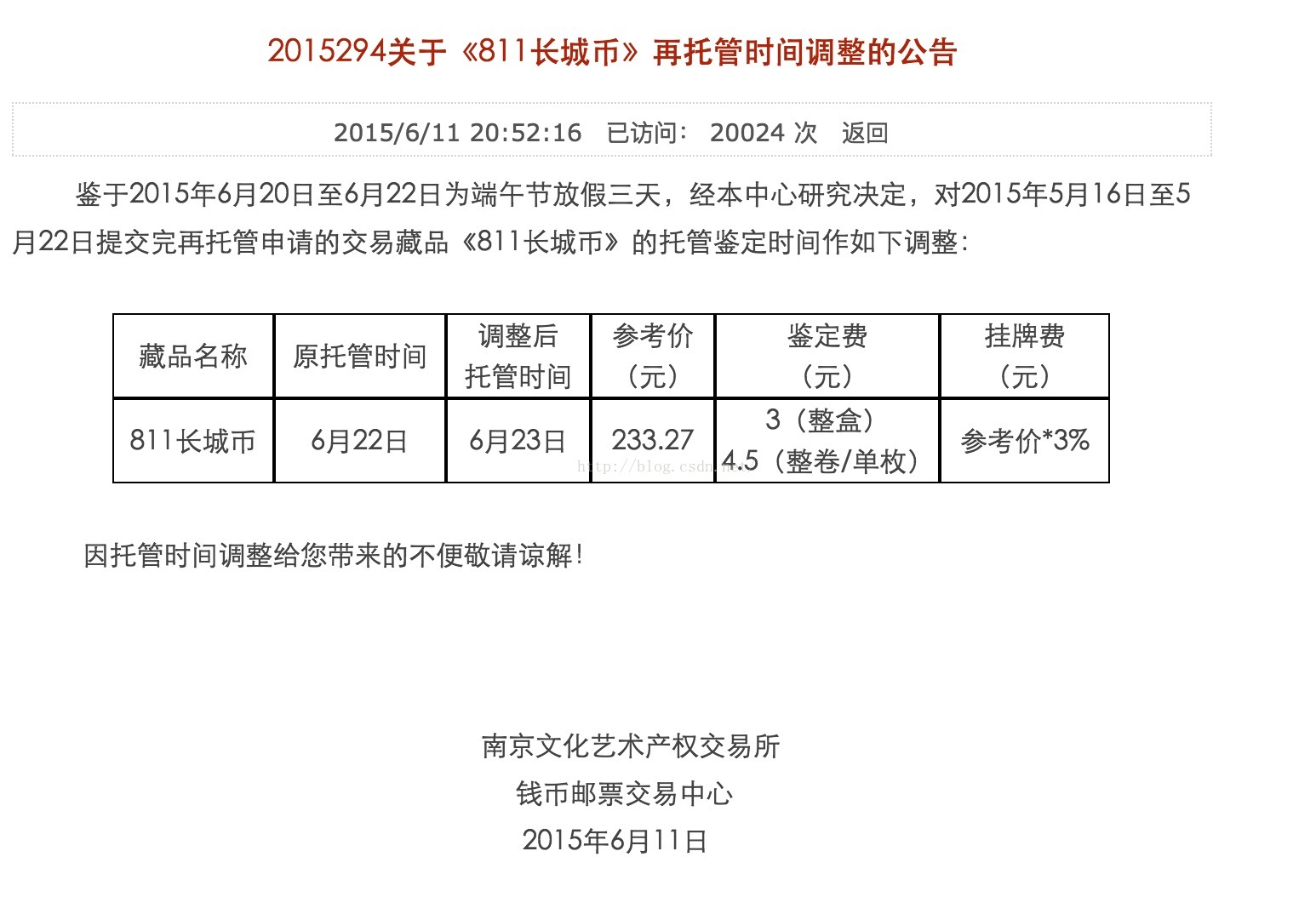
在实践中,我发现很多资讯内容网站都是这样的结构,所以我在想,是否,可以写一个通用的程序处理这一类的资讯爬取。当新的网站成为我们爬取的目标时,只需要在数据配置的地方,多几条配置数据,就可以爬到我需要多数据,那不是很赞 !
1. 公告数据的抽象
如何理解一个网站的结构,首先还是要抽象它的数据,在这里,我简单列出以下我抽象的数据。
public class NoticeCrawler implements Serializable{
/**
*
*/
private static final long serialVersionUID = 6562741735153521775L;
private Long noticeCrawlerId;
private String urlToCrawl; //要爬取的URL,以为一个类型的公告,可能存放在不同的页面,所以我这里对应的是用“;”分开的URL
private int noticeType; //公告类型
private String homeUrl; //Host 这个可以从 <span style="font-family: Arial, Helvetica, sans-serif;">urlToCrawl分析出来,不过为了方便,我直接指定了</span>
private String noticesUrlSelector; //获取 list 内容所需要的 selector,一般来说 select 列表里所有的<a 标签
private String titleSelector;//如何从 noticeUrlSelector中获取标题
private String contentSelector; //如何从细节页面 获取内容的selector
private String pageEncode; //网站编码,这个很关键,如果编码错误,会得不到正确的内容
private String adSelectors; //网站的内容中的广告selector,会被移除
private String dateSelector; //文章发布时间,
}当然这些数据,可以被定义在数据库中,程序启动的时候,从数据库中加载所有的数据,就可以开始数据爬取了。
2. 准备工作
我是用Jsoup做获取网页和解析网页的第三方库。Jsoup的是用入门,可以参考其他资料,在这里我就不多啰嗦了。
不过在是用Jsoup获取页面后,虽然我们定义了内部列表的Selector,但是却并不能保证我们正确获得URL,因为URL的格式可能是http开头,也可能是绝对目录,也可能是相对目录。所以还要做一些前处理,我的做法是把所有的URL替换成http开头的绝对路径,这样有助于我接下来解析。
public static void prepareAnalysis(Document document, String currentUrl, String homeUrl) {
Elements elements = document.select("[href]"); //找到所有img或者其他有href属性的标签
for (Element element : elements) {
String url = element.attr("href");
if (url != null && !url.startsWith("http")) { //URL已经是可以处理的URL
if (url.startsWith("/")) { // 如果使用绝对路径
url = homeUrl + url;
} else { // 如果使用相对路径
url = replaceUrl(currentUrl, url);
}
element.attr("href", url);
}
}
elements = document.select("[src]");
for (Element element : elements) {
String url = element.attr("src");
if (url != null && !url.startsWith("http")) { //http开头的目录可以直接解析,跳过
if (url.startsWith("/")) { // 绝对目录,则直接用 host 拼接起来
url = homeUrl + url;
} else { // 相对目录的处理要稍微复杂,要回退目录处理。
url = replaceUrl(currentUrl, url);
}
element.attr("src", url);
}
}
}
//当使用相对路径的时候,把路径中的 根据路径中的 ../来处理 爬取目标的URL,每遇到一个../则 回退到一个上级目录,最后得到真实的URL
public static final String replaceUrl(String toCrawl, String url) {
String base = toCrawl.substring(0, toCrawl.lastIndexOf('/'));
while (url.startsWith("../")) {
url = url.substring(3);
base = base.substring(0, base.lastIndexOf("/"));
}
return base + '/' + url;
}当用Jsoup获取到页面后,首先做的事情,就是预处理页面中存在的连接,使得所有连接可以直接通过程序GET到里面的内容。
3. 获取列表页面的详情页面地址
首先要自己分析页面结构,知道这些URL存在什么地方,如何用JQuery的Selector获取到,当然这需要一定的前端实践经验。
Elements elements = document.select(noticeCrawler.getNoticesUrlSelector());
List<String> noticeUrls = new ArrayList<>();
List<String> titles = new ArrayList<>();
for (Element element : elements) {
String url = element.attr("href");
String title = ""; //也可以在详情页爬Title,这里仅仅是参考
if (StringUtils.isEmpty(noticeCrawler.getTitleSelector())) {
title = element.text();
} else {
Elements titleEles = element.select(noticeCrawler.getTitleSelector());
if (!titleEles.isEmpty()) {
title = titleEles.get(0).text();
}
}
titles.add(title);
noticeUrls.add(url);
}
4. 获取文章内容
其实内容说到这里,剩余的东西已经很容易理解了,其实就是加上文章内容的Selector和时间Selector。
贴一份相对完整的代码吧,仅供参考~
package com.zx.spider.notice;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import com.zx.common.utils.NetworkUtil;
import com.zx.datamodels.content.bean.entity.Notice;
import com.zx.datamodels.content.bean.entity.NoticeCrawler;
import com.zx.datamodels.market.bean.entity.Exchange;
import com.zx.datamodels.utils.DateUtil;
import com.zx.datamodels.utils.StringUtils;
import com.zx.modules.content.service.NoticeService;
import com.zx.modules.content.service.NoticeSpiderService;
import com.zx.modules.content.service.PushService;
import com.zx.modules.market.service.ExchangeService;
import com.zx.spider.jobs.MyDetailQuartzJobBean;
public class NoticeSpider extends MyDetailQuartzJobBean {
private NoticeService noticeService;
private NoticeSpiderService noticeSpiderService;
public void setNoticeService(NoticeService noticeService) {
this.noticeService = noticeService;
}
public void setNoticeSpiderService(NoticeSpiderService noticeSpiderService) {
this.noticeSpiderService = noticeSpiderService;
}
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
List<NoticeCrawler> noticeCrawlers = noticeSpiderService.getAllOpenNoticeSpiders();
for (int i = 0; i < noticeCrawlers.size(); i++) {
try {
NoticeCrawler noticeCrawler = noticeCrawlers.get(i);
String[] toScrawlUrls = noticeCrawler.getUrlToCrawl().split(";");
List<Notice> notices = new ArrayList<>();
for (String toScrawUrl : toScrawlUrls) {
String homePage = NetworkUtil.get(toScrawUrl, noticeCrawler.getPageEncode());
Document document = Jsoup.parse(homePage);
prepareAnalysis(document, toScrawUrl, noticeCrawler.getHomeUrl());
Elements elements = document.select(noticeCrawler.getNoticesUrlSelector());
List<String> noticeUrls = new ArrayList<>();
List<String> titles = new ArrayList<>();
for (Element element : elements) {
String url = element.attr("href");
String title = "";
if (StringUtils.isEmpty(noticeCrawler.getTitleSelector())) {
title = element.text();
} else {
Elements titleEles = element.select(noticeCrawler.getTitleSelector());
if (!titleEles.isEmpty()) {
title = titleEles.get(0).text();
}
}
titles.add(title);
noticeUrls.add(url);
}
for (int j = 0; j < noticeUrls.size(); j++) {
String noticeUrl = noticeUrls.get(j);
String title = titles.get(j);
Notice notice = crawlContent(noticeUrl, noticeCrawler);
Notice toInsert = new Notice(noticeCrawler.getMarket(), title, notice.getNoticeContent(),
noticeUrl, noticeCrawler.getNoticeType(), from, notice.getCreateDate());
notices.add(toInsert);
}
}
noticeService.addNewBatch(notices);
} catch (Exception e) {
continue;
}
}
}
public static Notice crawlContent(String url, NoticeCrawler noticeCrawler) {
String noticeDocString = NetworkUtil.get(url, noticeCrawler.getPageEncode());
Document noticeDoc = Jsoup.parse(noticeDocString);
prepareAnalysis(noticeDoc, url, noticeCrawler.getHomeUrl());
Elements contentElements = new Elements();
String[] selectors = noticeCrawler.getContentSelector().split(";");
for (String selector : selectors) {
Elements contents = noticeDoc.select(selector);
contentElements.addAll(contents);
}
// remove adds inside
removeAds(contentElements, noticeCrawler);
StringBuilder contentBuilder = new StringBuilder();
for (Element contentPatch : contentElements) {
contentBuilder.append(contentPatch.html());
}
Notice notice = new Notice();
notice.setNoticeContent(contentBuilder.toString());
String publishDate = null;
if (!StringUtils.isEmpty(noticeCrawler.getDateSelector())) {
Elements dateElements = noticeDoc.select(noticeCrawler.getDateSelector());
String dateString = dateElements.text();
publishDate = StringUtils.extractLastDate(dateString);
} else {
publishDate = StringUtils.extractLastDate(notice.getNoticeContent());
}
String hourPart = DateUtil.toString(new Date(), DateUtil.hmsDash.get());
Date date = publishDate != null ? DateUtil.toDate(publishDate + ' ' + hourPart, DateUtil.ymdHmsDash.get())
: new Date();
notice.setCreateDate(new Timestamp(date.getTime()));
return notice;
}
public static void removeAds(Elements elements, NoticeCrawler noticeCrawler) {
String adSelectors = noticeCrawler.getAdSelectors();
if (StringUtils.isEmpty(adSelectors)) {
return;
}
String[] adSelectorsArray = adSelectors.split(";");
for (Element element : elements) {
for (String selector : adSelectorsArray) {
Elements ads = element.select(selector);
ads.empty();
}
}
}
public static void prepareAnalysis(Document document, String currentUrl, String homeUrl) {
Elements elements = document.select("[href]");
for (Element element : elements) {
String url = element.attr("href");
if (url != null && !url.startsWith("http")) { // the url is never
// started by -1
if (url.startsWith("/")) { // use absolute path
url = homeUrl + url;
} else { // use relative path.
url = replaceUrl(currentUrl, url);
}
element.attr("href", url);
}
}
elements = document.select("[src]");
for (Element element : elements) {
String url = element.attr("src");
if (url != null && !url.startsWith("http")) { // the url is never
// started by -1
if (url.startsWith("/")) { // use absolute path
url = homeUrl + url;
} else { // use relative path.
url = replaceUrl(currentUrl, url);
}
element.attr("src", url);
}
}
}
public static final String replaceUrl(String toCrawl, String url) {
String base = toCrawl.substring(0, toCrawl.lastIndexOf('/'));
while (url.startsWith("../")) {
url = url.substring(3);
base = base.substring(0, base.lastIndexOf("/"));
}
return base + '/' + url;
}
}
5. 效果展示
我在数据库中,配置了如下信息
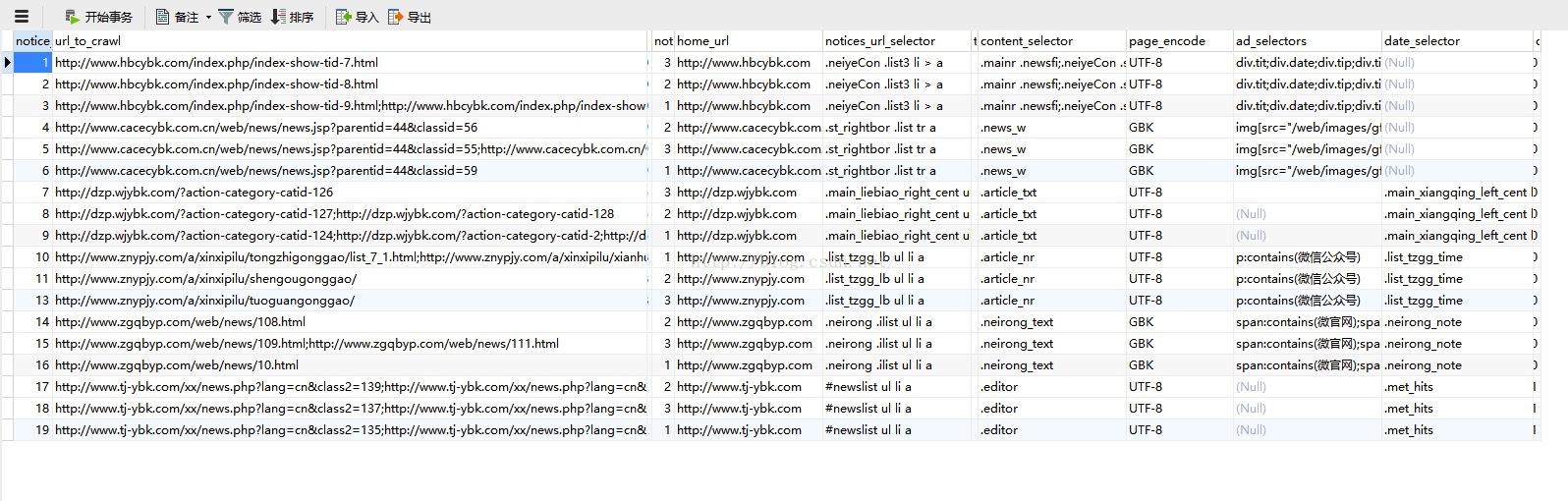
真的几乎就是配置一下,就立即生效。
抓去到的数据效果如下

详情页面:

文件和连接都没有问题~














 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









