







 本文讲述了一个初创企业从单一垂直架构逐步发展到分布式服务架构的过程,包括负载均衡、分库分表、读写分离等技术的应用,以及最终实现多活数据中心的挑战与解决方案。
本文讲述了一个初创企业从单一垂直架构逐步发展到分布式服务架构的过程,包括负载均衡、分库分表、读写分离等技术的应用,以及最终实现多活数据中心的挑战与解决方案。
本故事纯属虚构,如有雷同,实属巧合
程 是一个爱折腾,喜欢交朋友的程序员。
某一天,程一个朋友介绍了另外一个朋友 创 给他,创说他有个点子,可以改变世界,现在就差一个程序员。程看了创的PPT,觉得还不错,反正也没妹子,平时下班回家或者周末也没事干,就答应创,做他的合伙人,给他开发网站。
单一垂直架构
程把他自己在大学的时候做的基于Java的考试管理系统,拿来改了改,又自学了一些前端,三个月后,第一个版本的网站上线了。这个东西的后台大概这个样子,所有的东西都部署在一台服务器上。
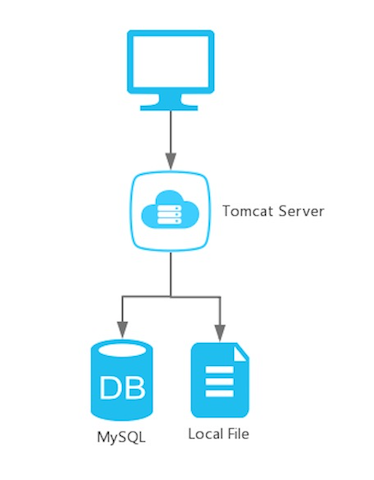
负载+垂直架构
上线后的半年,为了适应业务的变更,网站做了多次升级和新功能的研发。伴随着代码越来越庞大,注册用户越来越多,有时候要卡半天,才能刷出页面。创又多花几倍的预算在技术上,买了几台新服务器。然后这套系统变成了下面的样子,Mysql终于可以单独放在一台服务器上了,使用负载均衡后,可以把服务器实例(war)拷贝后部署到几台机器上了。
升级后,瞬间快了很多。
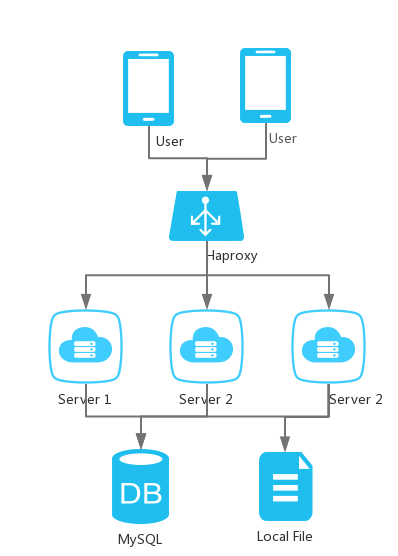
分布式服务架构
后来,这个公司拿到了天使投资,程也全职加入了,身份是CTO,而理所当然的,创做了CEO。陆续也有运营和市场的合伙人加入,日活有几万了。程也不用自己写前端了,因为招了2个专门的前端工程师,还有另外2个做服务器的小伙子。市场变化很多,每天都有新需求,每天都可能上线新功能。
但是,当前这样的服务器代码体系,让他越来越力不从心。
1. 这么一坨庞大的代码融在一起,维护成本和新人学习成本都是特别高的。 2. 想招一个实习生,但是如果开放给他权限就是所有代码,真担心这个实习生把代码拿去卖了。 3. 代码构建的时间越来越长,程序员最不喜欢的就是等了。 4. 发布成本也很高,因为每次发布都是全量发布。有些核心功能,需要全天服务用户,所以白天几乎不可能发布。即时发布一个无关紧要的功能,也要等到晚上,出了Bug还要赶紧修复,长期熬夜,真是觉得这个世界充满恶意。
不能再这样下去了......
其实程很早就听过分布式架构(SOA),也知道主流的公司都在用这些。但是现在业务代码已经十分庞大了,至少十几万,并且有大量重复和“不敢动的”代码,重构成SOA,至少要两个月,公司新需求不断,怎么可能。
经过一个月的挣扎,真心觉得不能忍了,决定升级架构成SOA,调研后发现阿里的开源框架Dubbo (http://dubbo.io) 好像使用的蛮多,文档也挺全的,所以决定用它。
重构前,首先梳理了一下业务,按照业务相关性,拆分成若干的底层SOA服务和API层服务。这个重构大概进行了2个月,CEO没技术背景,完全不知道他们提的SOA是个啥,新需求不能被满足,已经处于崩溃边缘。
终于,新架构上线了,它大概长成这个样子。
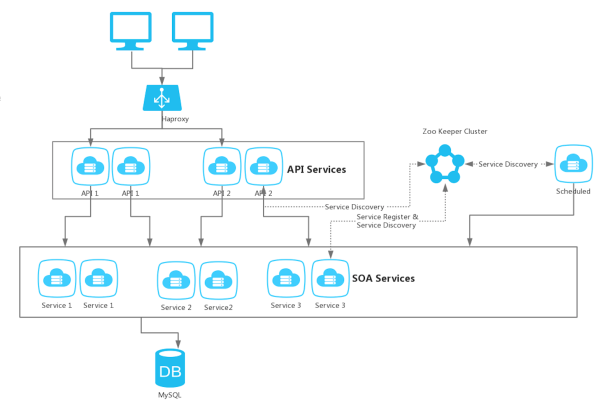
这里,每个服务包括API服务和基础的SOA服务都可以部署在不同的机器上,他们之间的发现是通过Zookeeper集群协调的。启动一个服务后,它就会注册自己到Zookeeper上,服务调用方被通知,新的服务实例上线。服务调用方持有一个服务的多个调用实例,采用某种策略进行负载。
可以按照业务需求,有选择的扩容指定服务,举个栗子,例如商城做双十一活动,有很多秒杀商品,那么只需要多部署几个和商城相关的服务即可。如果按照之前的架构设计,所有功能都在一个war中,只能对所有功能扩容,浪费计算资源。
当然,还有一些任务被改造成定时任务,就是图中的Scheduled模块,例如结算等,这样运营或者程序员就不用大半夜起来做事了。
分库分表,读写分离
半年后,公司又融了几千万的A轮,用户数进一步扩大。高峰时段越来越卡,各种Log分析系统时间和分析Mysql慢日志发现,因为数据量越来越多,并发数越来越大,主存储已经有点Hold不住了。并且程越来越担心万一哪天,那台Mysql机器硬盘出故障,废了,公司的所有的数据就都没了。
后来无意见,程发现了Mycat(http://mycat.io) 这个数据库中间件,原来还以利用它做分库分表,读写分离这些自己实践起来十分困难的高级Feature。
经过了差不多一个月的调研,实践,测试,升级后的Mysql集群变成了如下的样子。
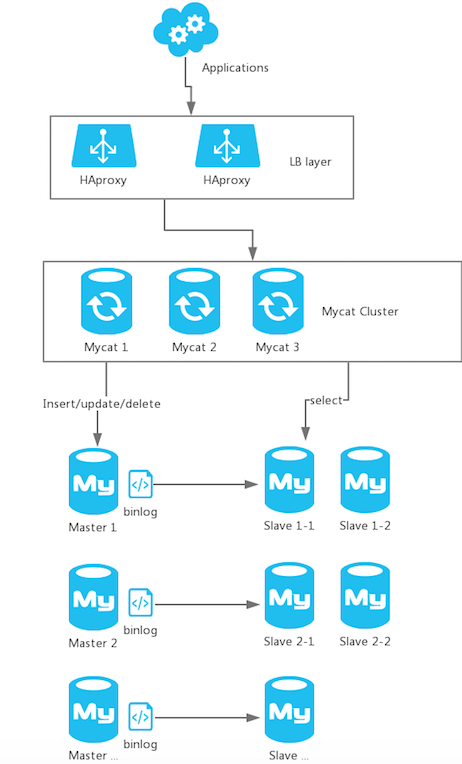
做了分库分表后,再也不用担心太多数据把单一Mysql服务器硬盘撑满的问题了,并且也更方便了权限管理。启用Slave从节点后,也不用担心单一主节点硬盘故障后,数据的丢失问题了。读写分离后,前端访问速度也快了很多,增删改查被分散到不同的机器,单节点的效率瓶颈有了很明显的缓解。
DRC(Data Replication Center)
伴随着业务种类越来越多,数据越来越多,依赖Mysql的索引的搜索早就显得力不从心。为了性能,只能支持某个字段的StartWith搜索。包含和模糊搜索都不能做,所以就用了Elastic Search做通用搜索引擎。为了进一步提升读效率,也把很多登录信息和用户好友关系这些经常读的数据,放入Redis中做缓存。
同一份数据,既要放入ES,还要放入Redis,早期这个功能实现大概如下:
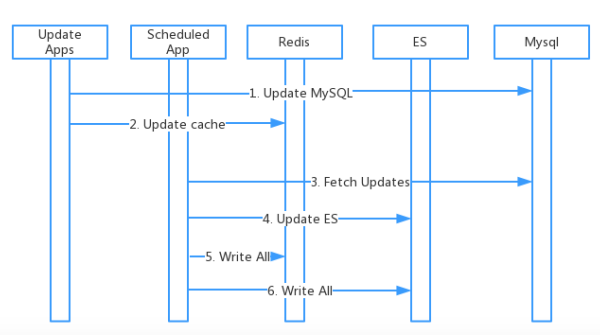
更新代码往往要关心缓存,同步ES数据,如果同步间隙过长,会有数据延迟,如果同步间隙太短,还要增加DB负担。并且伴随这个业务变多,越来越多这样的操作:从一个表中全量拉取更新数据,做进一步业务处理,给业务库造成很多额外的压力。
如果主数据变动,就把变动发送到一个中心,感兴趣的一·方只要订阅这些消息,就可以实现自己的逻辑,实时性高的同时,不会给业务库造成任何压力。于是DRC诞生了:
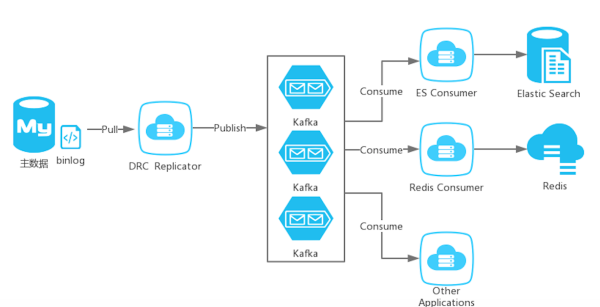
可以理解DRC Replicator模拟了一个Mysql Slave,从主节点拉binlog,然后解析binlog,并将结果发送到消息队列中。
而感兴趣的程序,可以去订阅消息,然后执行相应的更新,这样就把更新缓存的事情和业务代码解耦了,更新ES这种操作也可以做到既实时性高,也不用经常去Mysql库中扫描表了。当然DRC还有一个重要的应用,它也是多活的核心组件之一。
多活
伴随用户体量进一步提高,交易量的暴增,简单的数据备份,已经不能很好的满足需求了。如果机房宕机,依然会导致服务不可用。
另外,所有的流量都打到机房的服务集群,也会导致一定的系统瓶颈。可能更理想的方式是:一个北京的用户下单,他的整个业务流都落在北京的机房;上海的用户下单,也希望所有的数据落在上海的机房,两个机房的主数据互备,同时满足数据的一致性。其中某个机房挂掉后,所有的流量切到另外一个机房。
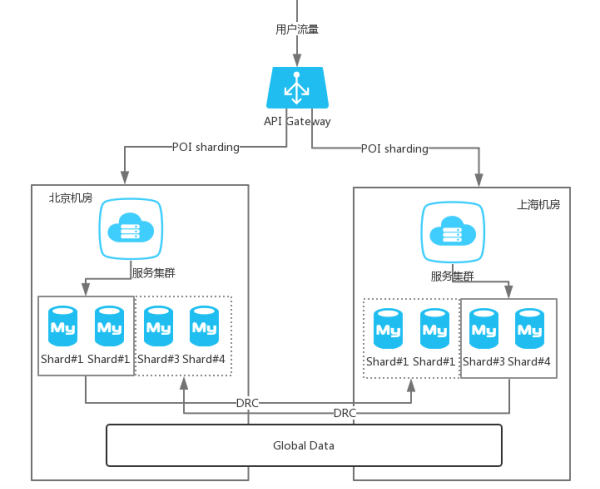
而对于强一致性的数据,例如用户表存在用户名的uniq索引,对于这类数据,可以放在一个倍成为全局数据的机房,所有写落在这里,其他机房只是执行备份。
就这样,随着用户的逐渐增多,融资一次一次到来,团队越来越多,业务线越来越多,架构的也一次一次升级演化。路已经走了很远,并且伴随着越走越远,未来可能还有更多的升级和演化。
这个架构演化的故事,讲完了。如有陈述不当或错误,欢迎留言讨论~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









