









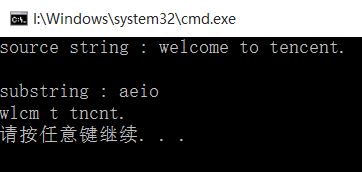
要求:输入一个主串X和模式串Y,要求删除主串X中在模式串Y中出现的所有字符。如:主串X:welcome to tencent. 模式串Y:aeio。则输出结果为:wlcm t tncnt.
思路:最直接的思路就是用两层for循环,外层for循环扫描主串X,内层for循环用来扫面当前主串X中的字符是否在模式串Y中出现,如果出现则去除该字符,即将从该字符往后到主串末尾全部字符往前移动一位。但这样每次得扫描模式串,我们可以考虑用哈希表存储模式串中出现的字符,即hashTable[*str]==1,然后只需在主串扫描时与哈希表中对应字符的下标中的值比较,若为1则表示应该去除。但这仅仅只降低了扫描模式串的复杂度.
接下来应该考虑减少在主串X中移动当前字符后面字符的次数。我们知道,事实上我们不需要每次删除主串X中某个字符时就移动余下的全部字符,当一个字符需要被删除的时候,我们把它所占的位置让它后面的字符来覆盖,也就相当于删除了这个字符。基于快速排序对冒泡排序改进的思路,我们可以用两个指针first,second,初始时都指向主串的起始位置,然后判断first指向的字符是否需要删除,是则first直接跳过,指向下一个字符。如果first指向的字符是不需要删除的字符,那么把first指向的字符赋值给second指向的字符,然后first和second同时向后移动指向下一个字符,直至first指针到达主串X的末尾。这样时间复杂度降低到了O(n).
基于上述思路代码如下:
#include<iostream>
using namespace std;
int hashtable[256];
void initTable(char *str)
{
memset(hashtable,0,sizeof(hashtable));
char *p = str;
while(*p!='\0')
{
hashtable[*p] = 1;
p++;
}
p = NULL;
}
char *Delete(char *source, char *substr)
{
char *first = source;
char *second = source;
while(*first != '\0')
{
if(hashtable[*first] != 1)//如果主串中的字符在模式串中未出现
{
*second = *first;
second++;
}
first++;
}
*second = '\0';
return source;
}
int main()
{
int N = 20;
char *source = (char *)malloc(sizeof(char)*N);
char *substr = (char *)malloc(sizeof(char)*N);
cout<<"source string : ";
gets(source);
cout<<endl<<"substring : ";
gets(substr);
initTable(substr);//初始化table数组
cout<<Delete(source,substr)<<endl;
return 1;
}















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









