







一 概念及引入
贝叶斯定理由 Thomas Bayes名字命名,他是18世纪概率论和决策论的早期研究者。
在介绍贝叶斯定理前,我们需要先了解三个概念:
(1)条件概率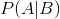
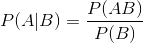
(以下注意:H为某种假设,X为某条件)
(2)后验概率(P(H|x)):在条件X下,H的后验概率。
如:X代表一位顾客:{"年龄"=35岁,"收入"=4万元},H为假设:{是否购买计算机}。则P(H|X)代表我们知道顾客年龄 和收入 后,其购买计算机的概率
(3)先验概率(P(H)):假设H的先验概率。
与上述实例对比,P(H)是任意顾客购买计算机的概率(源于总体的统计),而不管其收入和年龄,独立于X。
延伸:
P(X|H)是条件H下,X的后延概率,此时它代表:已知顾客已经购买计算机,估计其"年龄=35"且"收入=4万元"
使用贝叶斯定理的情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。贝叶斯定理如下:

二 朴素贝叶斯分类(Naive Bayesian)
2.1 数据说明:
1.数据描述:从某电器类商家获取的,根据顾客属性来判断其是否购买电脑。
2.数据属性及其取值 :
/******普通属性*********/
属性 取值
age {youth,middle_age,senior}
income {low,medium,high}
student {yes,no}
credit_rating {fair,excellent}
/******分类属性********/
属性 取值
buys_computer {yes,no}
youth,high,no,fair,no
youth,high,no,excellent,no
middle_aged,high,no,fair,yes
senior,medium,no,fair,yes
senior,low,yes,fair,yes
senior,low,yes,excellent,no
middle_aged,low,yes,excellent,yes
youth,medium,no,fair,no
youth,low,yes,fair,yes
senior,medium,yes,fair,yes
youth,medium,yes,excellent,yes
middle_aged,medium,no,excellent,yes
middle_aged,high,yes,fair,yes
senior,medium,no,excellent,no
2.2 分类过程如下:
(1)假定有m个类C1,C2,C3,...Cm(示例数据中C1=yes,C2=no))。给定元组X(如数据中第一行: X1= {age="youth",income="high",student="no",credit_rating="fair"}),分类法将预测X属于具有最高后验概率的类(在条件X下)。也即,判断某位顾客X1是否会买电脑(X1->buys_computer=yes或X1->buys_computer=no).朴素贝叶斯分类法预测X属于类Ci,当且仅当P(Ci|X)>P(Cj|X) (j!=i)(也即:X属于分类i的概率比属于其他分类的概率高)。根据贝叶斯定理有:

(2)由于P(X)对所有类为常数,所以只需要P(X|Ci)P(Ci)最大即可。如果类的先验概率未知,则通常假定这些类是等概率的。
(3)给定具有许多属性的数据集,计算P(X|Ci)的开销十分大,可以做类条件独立的朴素假定,也即属性间相互独立。因此可以求得:
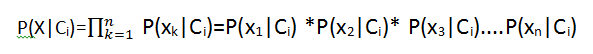
其中xk代表元组X在第k个属性上的取值,如实例中为:x1:age=youth,x2:income=high......
2.3 实例
P(age=youth|buys_computer=no) =3/5=0.600
P(income=medium|buys_computer=yes) =4/9=0.444
P(income=medium|buys_computer=no) =2/5=0.400
P(student=yes|buys_computer=yes) =6/9=0.667
P(student=yes|buys_computer=no) =1/5=0.200
P(credit_rating=fair|buys_computer=yes) =6/9=0.667
P(credit_rating=fair|buys_computer=no) =2/5=0.400
使用以上,得到:
P(X|buys_computer=yes)=P(age=youth|buys_computer=yes)*P(income=medium|buys_computer=yes)*
P(student=yes|buys_computer=yes) *P(credit_rating=fair|buys_computer=yes)
=0.222*0.444*0.667*0.667=0.044
同理可得
P(X|buys_computer=no)=0.600*0.400*0.200*0.400=0.019
为得到最大化P(X|Ci)P(Ci)的类,计算:
P(X|buys_computer=yes)*P(buys_computer=yes)=0.044*0.643=0.028
P(X|buys_computer=no)*P(buys_computer=no)=0.019*0.357=0.007
最后可以看到:
P(X|buys_computer=yes)*P(buys_computer=yes)> P(X|buys_computer=no)*P(buys_computer=no)
因此,结论是:预测分组X的类为buys_computer=yes















 2554
2554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









