







本文重点介绍JVM内存模型,对象标识算法以及垃圾回收算法的原理,至于一些实际JVM优化操作或遇到的问题会在后续其他文章进行讲解。
一、JVM分为那些区域?每个区域存储什么内容?
JVM运行时(例如运行一个main方法),在操作系统中是一个进程,该进程在物理内存中开辟一块空间,在这块空间中又划分了很多区域,有些区域是线程共享的,有些区域是线程独享的。如下图所示:
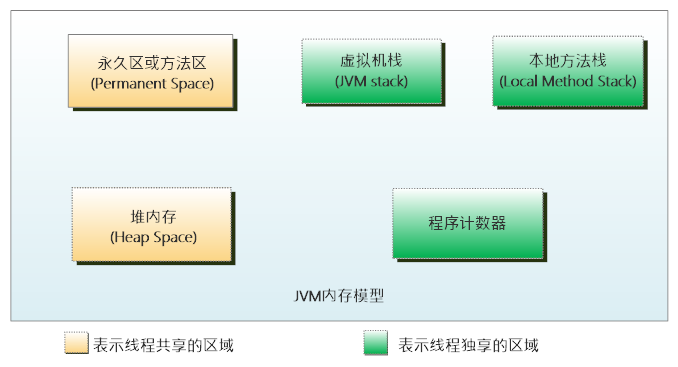
永久区或方法区:存储类的信息,例如类名,属性,方法名,常量等等,由于这些内容几乎不发生变化,所以该区可以称作永久区。当该区域加载了大量类的时候,是会发生oom的,例如tomcat启动时加载了web项目的大量jsp文件,或者通过动态代理创建了非常多的代理类。
堆内存(很重要):是JVM中最大的一块内存区域,存储所有的对象实例,堆又分为Eden,from survivor,to survivor和年老代,该区域会在后面做详细介绍。
虚拟机栈:存放在编译期可以预知的所有基本类型,例如int、boolean、char等,其次该区域还存放每个线程在执行方法时的嵌套深度,例如methodA调用methodB,然后结束,那么嵌套深度就是2,如果有一些递归操作,嵌套深度非常深,也可能导致oom。
本地方法栈:存放native的方法。
程序计数器:记录每一个线程执行代码的行号,此区域是jvm中唯一不会发生oom的区域。
二、为什么需要垃圾回收?JVM中哪些区域会进行垃圾回收?什么样的对象会被垃圾回收?
通过第一部分内容,描述了每个区域存储的内容,那么为什么需要垃圾回收?简单来说,如果创建的一个对象不在被任何变量所引用了,那么这个对象对后续程序已经没有存在的意义了,那么就要把这个对象占用的内存进行释放,这个过程就是所谓的垃圾回收。
哪些区域会进行垃圾回收?
虚拟机栈、本地方法栈和计数器会自动随着方法或者线程的结束而自然的被回收,所以以上三个区域不需要程序员来考虑垃圾回收的问题。堆内存和永久区是垃圾回收的重点区域,每个接口的多个实现类需要的内存是不一样的,每个方法嵌套的深度不同需要的内存也不一样,每个线程在执行过程中随时有变量不被引用,因此这两部分的垃圾回收是动态的,程序员可以通过JVM参数的设置来改变垃圾回收的频率和方式等。
什么样的对象会被判断为对后续程序无用可回收的?通俗来讲就是不被引用的,那么如何判断一个对象没有被引用有一下几种算法:
1.引用计数算法
在JDK1.2以前的版本采用这种算法,请参考以下代码:
`
User u1 = new User();
User u2 = u1;
User u3 = new User();
`
User对象创建了两次,他们被引用的数量分别为2,1,如下图:
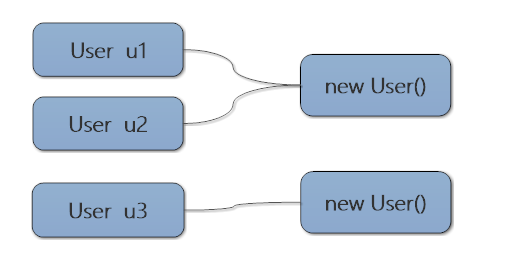
如果此时,u3=null ; u1 = null;那么如果此时正好垃圾回收,那么两个对象的引用数为1,0,则第二个对象被回收,这种简单的通过统计对象被引用的数量的算法就是引用计数法。改方法虽然简单,但是无法解决循环应用的问题,如一下代码:
User u = new User();
Car c = new Car();
u.setCar(c);
c.setUser(u);
关系如下图:
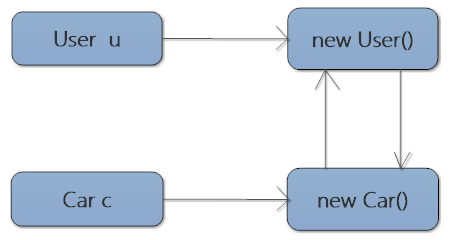
此时,即使u = null; c = null; 那么在垃圾回收时User和Car对象也不会被垃圾回收,因为对于User对象,除了u变量引用之外,还有Car对象里面的属性在引用,同理Car对象也如此,基于此问题,在jdk1.2以后,采用了可达性算法。
2. 可达性算法
可达性算法也叫做根搜索算法,官方给出的定义是判断 每个对象的引用是否可达到根,根这个东西比较抽象,读者不必纠结它具体是什么,可以理解为一个对象引用链路的头节点,可以参考以下代码:
public static void main(String[] args){
User u = new User();
Car c = new Car();
Wheel w = new Wheel();
u.setCar(c);
c.setWheel(w);
}
他们的关系图如下:
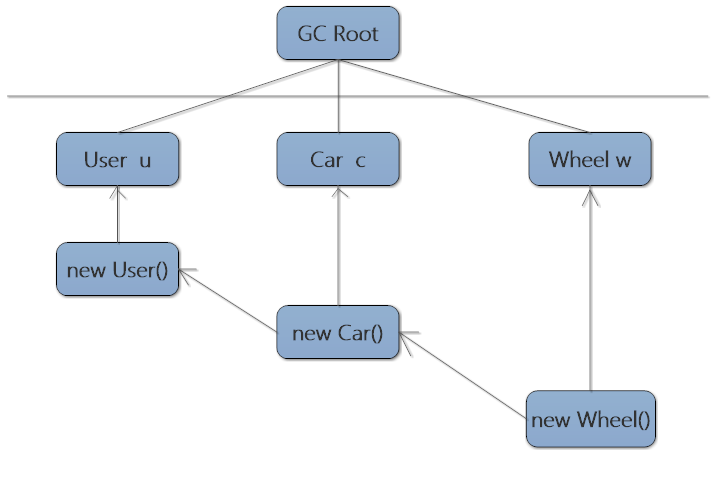
如上图所示,new User(),new Car(),new Wheel()对象都可达Root节点,那么此时如果我们把c =null,w=null,new Car(),new Wheel()仍然不会被回收,因为他们都可以通过User 这个对象的链路来达到Root,但是此时如果再把u.setCar(null),那么new Car(),new Wheel()将被回收,因为User这条链路也断了,这就解决了所谓的循环引用的问题。
3.finalize方法的作用
这里在顺便提一下finalize方法,这个放在在java开发中已经很少被用到了。当一个对象被标记为不可达将要被回收了,在回收前JVM会去执行当前对象的finalize方法,如果此时在finalize方法中,又用了一个引用指向了当前对象,是当前对象编程可达,那么当前对象就不会被回收,也就是当前对象被解救了,但是一个对象的finalize方法只能被执行一次。
三、垃圾回收是如何执行的?有哪些算法?
通过第二部分,我们已经知道判断一个对象是否可以被回收的规则,那么本节详细说明JVM是如何对不可达对象进行回收。
在第二部分中我提到,虚拟机栈、本地方法栈和计数器会自动随着方法或者线程的结束而自然的被回收,他们的垃圾回收不需要我们考虑,而永久区被占满后会出发Full GC,他的垃圾回收也不需要我们考虑,所以这里重点介绍堆的垃圾回收算法。
在第一部分提到,堆分为eden,to survivor,form survivor和年老代,其中eden,to survivor,form survivor这三部分称作年轻代,他们三者的默认大小比例是8:1:1,至于为什么是8:1:1,是因为在堆的年轻代采用的垃圾回收算法是–复制算法。
1.复制算法
在堆的年轻代存放的对象都是生命周期很短的对象,在任何时刻来看堆上的对象,其实存活的对象在2%左右(这个不难理解,例如运行一个非常大的main方法,在运行过程中我们看这个main方法,在运行过的代码中,有大量的临时变量已经没有了引用不可达,都是已经死了的)。当堆新创建一个对象时,对象会创建在eden 和 from survivor中,一旦满了之后就要进行垃圾回收,在进行垃圾回收的时候,上面已经说到,活着的对象在2%左右,jvm会把这2%的对象复制到to survivor中,因为三者的比例为8:1:1,也就是说to survivor的大小为10%,这足以存下2%的对象,然后jvm会清空eden 和 from survivor,此后再创建的对象就会放在eden 和 to Survivor中,满了以后再重复上述动作。如果一个对象从from survivor到to survivor复制了几次,那么这个对象就是生命周期很长的对象,就会被扔到年老代。复制算法过程如下图:
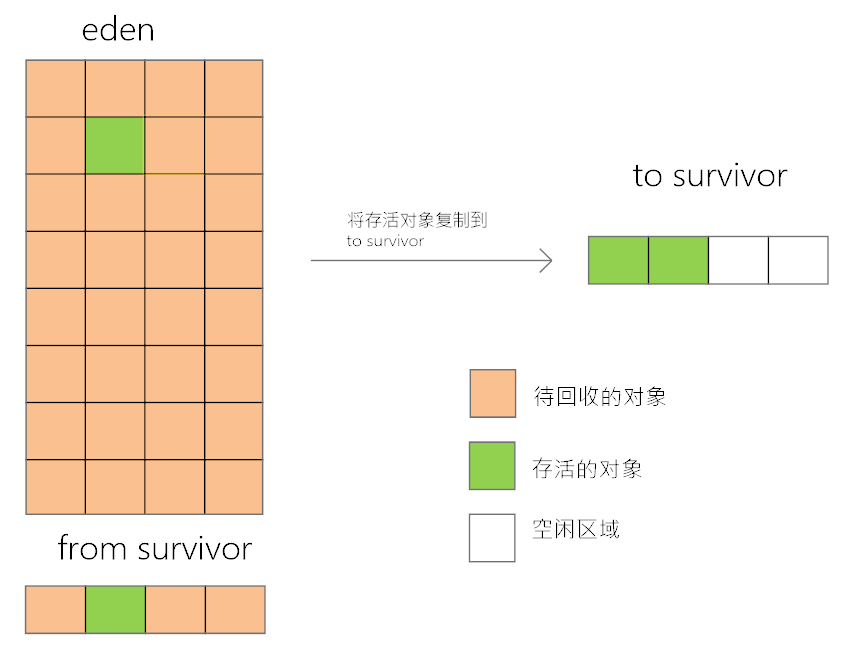
由于年轻代的对象生命周期短,每次复制对象仅有2%,仅开辟10%的to survivor空间,就可以完成复制,所以可以采用复制算法,那么年老带的对象由于对象的生命周期很长,如果也采用复制算法,那么每次复制的对象可能占到90%左右,这会浪费非常大的空间同时消耗cpu资源,所以在年老代采用的是整理算法。
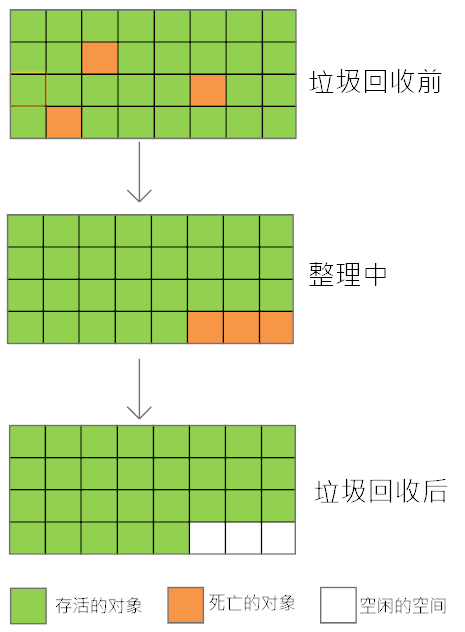
2.整理算法:
整理算法过程就是在年老代的内存中,把存活对象的内存进行整理,保证存活和死亡的空间都是连续的,然后在对死亡的部分进行清空,过程如下:
3. 标记算法
这种算法缺点比较明显,主要过程就是把内存中的死亡对象进行释放,从而会导致脆片较多,空闲区域不连续,如果创建大对象,例如大数组,那么仍然可能导致oom。















 5404
5404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









