







CSDN爬虫(五)——CSDN用户(所有)爬取+常用爬虫正则整理
说明
- 开发环境:jdk1.7+myeclipse10.7+win74bit+mysql5.5+webmagic0.5.2+jsoup1.7.2
- 爬虫框架:webMagic
- 建议:建议首先阅读webMagic的文档,再查看此系列文章,便于理解,快速学习:http://webmagic.io/
- 开发所需jar下载(不包括数据库操作相关jar包):点我下载
- 该系列文章会省略webMagic文档已经讲解过的相关知识。
概述
- 我们会从CSDN个人中心出发,首先爬取一个用户的个人信息。然后根据该用户的好友关系去爬取好友信息。依次类推,爬取所用用户。
- 爬取CSDN所有用户是根据“粉丝、关注”去爬取“粉丝、关注”,必然会涉及到“死循环”。到后期肯定会出现大量“脏数据”(重复数据),就要考虑到过滤脏数据的问题。
- 虽然用webMagic框架爬虫会用到大量的正则表达式,并且爬虫类的正则在网上也很少能找到资料,但是也是比较固定。
CSDN用户(所有)爬取代码预览
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
关键代码解释
- 正则
http://my.csdn.net/\\w+"表示过滤出以http://my.csdn.net/"开头的网址链接。不过该正则存在一定的问题,就是只对网址前面部分进行了限制,并没有对后面进行限制。只要以http://my.csdn.net/"开头的网址全部会被加入到爬虫队列,存在大量的“脏数据”网址。比较合理的是:http://my.csdn.net/"后面可以出现除了“/”的任意字符。正则的准确性直接影响到爬虫的效率,越准确越好。这里不再修改。 profileElements.get(0).getElementsByClass("person-detail").get(0).text();该代码片段是为了获取用户的个人资料,该资料比较多,包括行业、职业、地区(国、省、市、区等)、姓名等信息。经过分析没有好的依据对信息进行归类,这里只是获取粗略信息。经过分析,甚至说CSDN官方最开始对该块没有进行合理的安排,导致用户的信息没有统一的格式。-
以下代码片段是该部分的核心代码,实现了递归式的爬取所有用户。
relationElements元素来自于mainElements.get(2).getElementsByTag("div");,属于“关系模块”,包括关注的人和被关注的人以及访客信息。在这个模块中可以获取部分其它用户的id,只不过是部分的,最多只有6个人信息。CSDN官方没有提供获取所有粉丝或者关注者的信息。不过,只要这仅仅的用户信息,我们就可以爬取所有的用户。方便的是,顺便可以过滤掉“死鱼”用户(没有相互关系的用户)。- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
需要说明的是,爬取所有用户,其实不是一定要定位到“关系”模块。我们甚至可以简单粗暴的直接获取
http://my.csdn.net/user_id"中所用有效链接,直接加入到爬虫队列。到时候直接通过正则http://my.csdn.net/\\w+"过滤出有效链接即可。代码如下:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
正如前文概述中所说,递归时的爬取用户信息,会出现大量已经爬取过的页面,我们需要“过滤”掉这些信息。核心的代码是
page.setSkip(true);,爬取之后,直接设置为“跳过”,下次爬取会直接跳过该链接。webMagic的作者对该方法的解释如下:/**
- Set whether to skip the result.
- Result which is skipped will not be processed by Pipeline.
* - @param skip whether to skip the result
- @return this
*/
- Set whether to skip the result.
-
过滤代码如下:
- 1
- 2
- 3
- 4
- 5
爬取结果预览
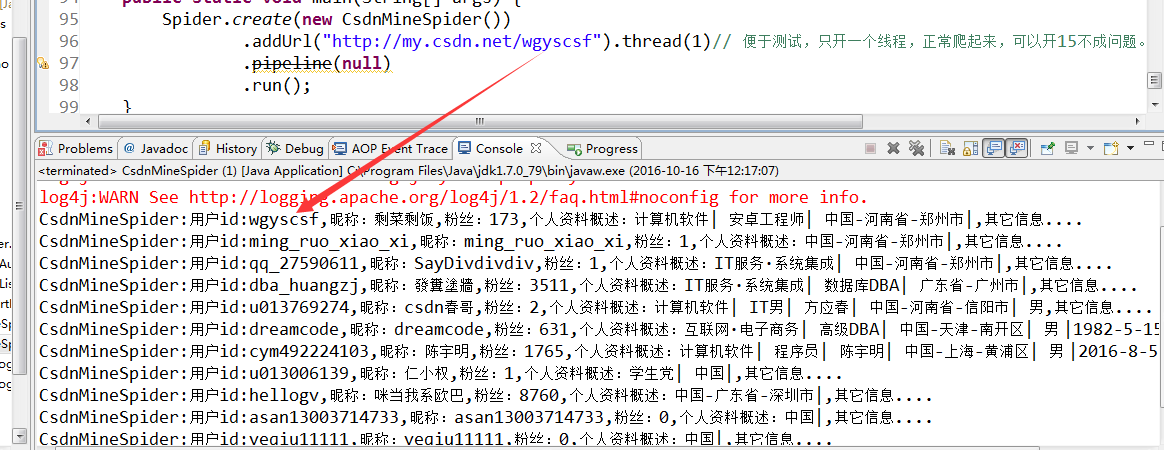
- 爬取所有用户
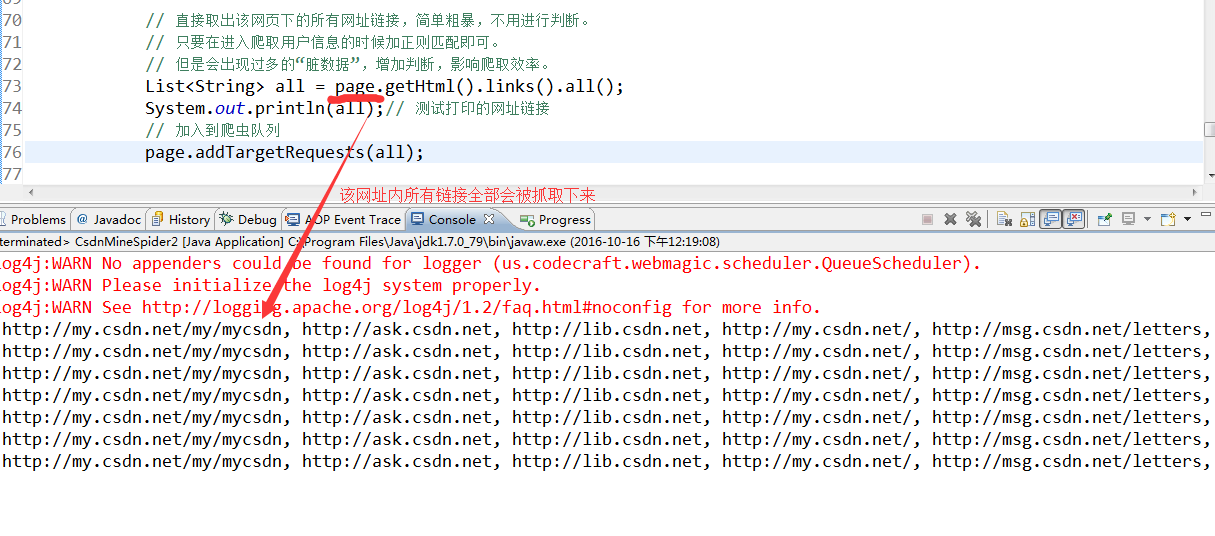
- 爬取所有
http://my.csdn.net/user_id"内网址
常用爬虫正则
http://my.csdn.net/\\w+":过滤出所有以http://my.csdn.net/开头的网址。^http://blog.csdn.net/((?!/).)*$:过滤出以http://blog.csdn.net/开头,并且后面不能再出现“/”的所有网址链接。^http://blog.csdn.net/\\w+/article/list/[0-9]*[1-9][0-9]*$:过滤出http://blog.csdn.net/后面是任意字符,并且紧接着/article/list/,且/article/list/后面只能是数字的所有网址链接。http://blog.csdn.net/\\w+/article/details/\\w+:效果同上,只是最后允许任意字符,不仅仅限于数字。
测试正则的方式
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8














 1428
1428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









