







背景
没有用什么高大上的BI工具,一直在控制台操作,遂想看看作为分析师以及用户的话,什么样的结果展现形式比较明了。选了之前接触过的zeppelin.
角色分工
+------------------------------------------+------------------+-------------------+
| hadoop(hostname/IP:roler) | hive | zeppelin |
+------------------------------------------+------------------+-------------------+
| sv000/172.29.6.100:master | server | server |
+------------------------------------------+------------------+-------------------+
| sv001/172.29.6.101:slave | -------- | -------- |
+------------------------------------------+------------------+-------------------+
| sv002/172.29.6.102:slave | -------- | -------- |
+------------------------------------------+------------------+-------------------+
| sv003/172.29.6.103:slave | -------- | -------- |
+------------------------------------------+------------------+-------------------+
事前准备
- Hadoop-2.5.2
- Hive-1.2.1
- zeppelin-0.5.6
环境搭建
Hadoop和Hive的环境这里就不在累述了,之前的博文中都已经写过了。这里只写一些注意点:
zeppelin中要连接hive数据库,就必须使用远程连接,这样的话,就需要在hive这边设置用户名和密码,否则在zeppelin的web端去连接的时候,就直接报错了。
$HIVE_HOME/conf/hive-site.xml中追加:
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>ername to use against metastoredatabase</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastoredatabase</description>
</property>启动hive
./bin/hive --service metastore &
./bin/hiveserver2 &--add by 2016/09/09
实际上,我们只需要启动hiveserver2即可,只要beeline可以远程模式链接数据库即可。
即./bin/hiveserver2
搭建zeppelin
1.zeppelin-0.5.6-bin.tar.gz下载
2.解压
tar -zxvf zeppelin-0.5.6-bin.tar.gz3.conf/zeppelin-env.sh中配置参数
export JAVA_HOME=/usr/java/jdk1.8.0_66
export HADOOP_CONF_DIR=/etc/hadoop4.conf/zeppelin-site.xml修改参数
<property>
<name>zeppelin.server.addr</name>
<value>172.29.6.100</value>
<description>Server address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>8888</value>
<description>Server port.</description>
</property>5.启动
./bin/zeppelin-daemon.sh start6.web端查看确认
http://172.29.6.100:8888
问题
1.连接hive时,报java.lang.NoSuchMethodError: org.apache.hadoop.hive.shims.HadoopShims.isSecurityEnabled()Z
具体堆栈信息如下:
#zepplin/log/zeppelin-interpreter-hive-root-sv000.log
ERROR [2016-05-25 19:03:47,332] ({pool-2-thread-2} Job.java[run]:182) - Job failed
java.lang.NoSuchMethodError: org.apache.hadoop.hive.shims.HadoopShims.isSecurityEnabled()Z
at org.apache.hive.service.cli.CLIService.init(CLIService.java:82)
at org.apache.hive.service.cli.thrift.EmbeddedThriftBinaryCLIService.init(EmbeddedThriftBinaryCLIService.java:40)
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:148)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:105)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
at org.apache.zeppelin.hive.HiveInterpreter.getConnection(HiveInterpreter.java:189)
at org.apache.zeppelin.hive.HiveInterpreter.getStatement(HiveInterpreter.java:204)
at org.apache.zeppelin.hive.HiveInterpreter.executeSql(HiveInterpreter.java:233)
at org.apache.zeppelin.hive.HiveInterpreter.interpret(HiveInterpreter.java:328)
at org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)
at org.apache.zeppelin.scheduler.Job.run(Job.java:169)
at org.apache.zeppelin.scheduler.ParallelScheduler$JobRunner.run(ParallelScheduler.java:157)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)调查了一下,开始以为是缺少某个架包导致的,找了0.13.1的,这个问题没出现,但随后又出现新的问题了,如下
ERROR [2016-05-26 16:39:37,401] ({pool-2-thread-2} Job.java[run]:182) - Job failed
java.lang.AbstractMethodError: org.apache.hadoop.hive.shims.Hadoop23Shims.isSecurityEnabled()Z
at org.apache.hive.service.cli.CLIService.init(CLIService.java:82)
at org.apache.hive.service.cli.thrift.EmbeddedThriftBinaryCLIService.init(EmbeddedThriftBinaryCLIService.java:40)
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:148)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:105)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
at org.apache.zeppelin.hive.HiveInterpreter.getConnection(HiveInterpreter.java:189)
at org.apache.zeppelin.hive.HiveInterpreter.getStatement(HiveInterpreter.java:204)
at org.apache.zeppelin.hive.HiveInterpreter.executeSql(HiveInterpreter.java:233)
at org.apache.zeppelin.hive.HiveInterpreter.interpret(HiveInterpreter.java:328)
at org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)
at org.apache.zeppelin.scheduler.Job.run(Job.java:169)
at org.apache.zeppelin.scheduler.ParallelScheduler$JobRunner.run(ParallelScheduler.java:157)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
INFO [2016-05-26 16:39:37,422] ({pool-2-thread-2} SchedulerFactory.java[jobFinished]:135) - Job remoteInterpretJob_1464248376371 finished by scheduler org.apache.zeppelin.hive.HiveInterpreter59906
7174确认后,觉得这个应该没有找到问题的原因,且同时在网上看到了,在0.13.1之后,就已经在hive的源码里将isSecurityEnabled()这些dead code删除了,所以应该就是我在zeppelin的interpreter里配置的hive JDBC有问题。
嵌入式:jdbc:hive2://
这个抛出了上面的问题。
修改成:jdbc:hive2://172.29.6.100:10000/default
事前需要在hive端使用beeline去测试,是否可行。只有beeline连接没问题的话,zeppelin这边才会没问题。
如果测试时出现下面的问题:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://server:10000/;principal=<Server_Principal_of_HiveServer2> java.net.ConnectException: Connection refused (state=08S01,code=0)请按照以下步骤进行修改确认,屡试不爽:
- Kill your hiveserver2 & metastore & Restart them again.
- check hiveserver2 & metastore are running using 'jps' command.
- Run "root@hostname~]# beeline -u jdbc:hive2://localhost:10000/" .
- if still getting this error then replace "localhost" with "hostname " of step 3
之前困扰了自己好久的问题终于解决了。
--add @2016/09/09
实质的原因可以参考之前的博文:hive问题集
下图中出现的%hive(default)中的default,并不是hive默认的数据库,而是在interpreters中设置的prefix而已。
即:default.driver.url
1.初次启动zeppelin Web UI界面显示信息:
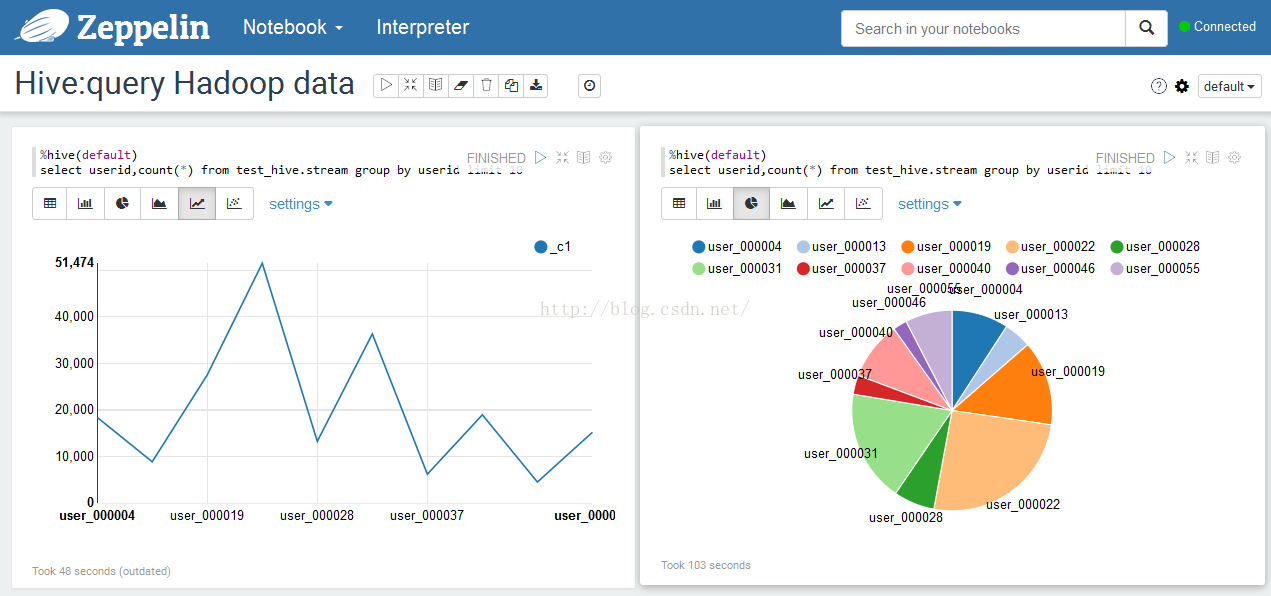
2.hive+hadoop数据查询结果显示:折线图对比饼图
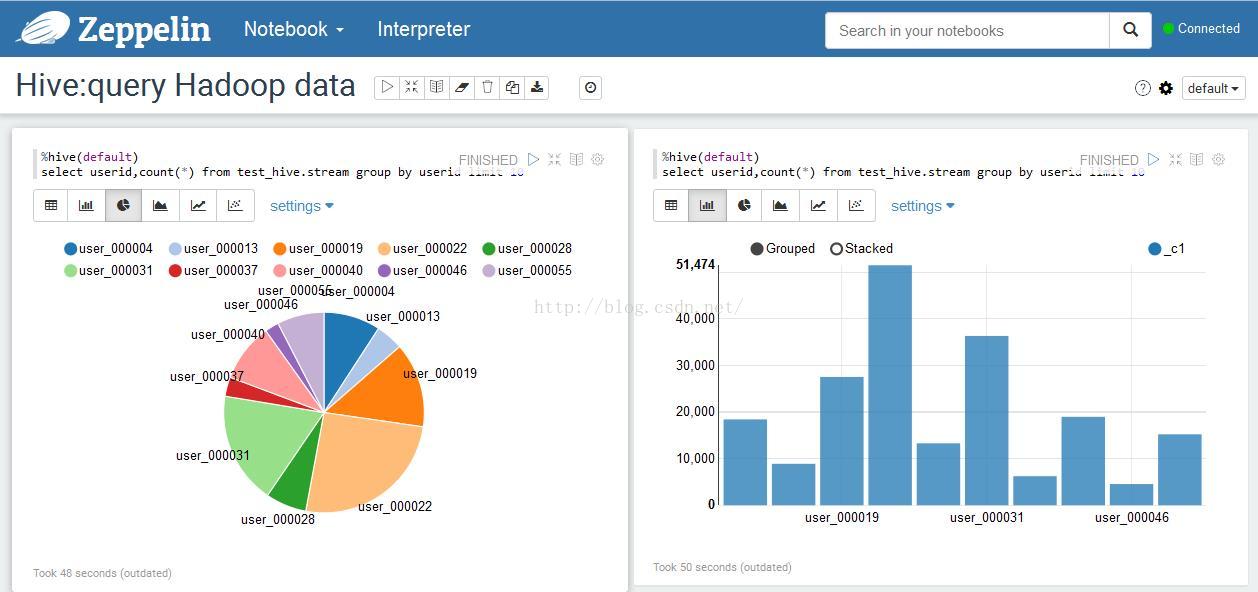
3.hive+hadoop数据查询结果显示:饼图和柱状图
看到网上有人使用R语言做出的数据统计图片,以及地图的相关图片,特别的炫。还是挺有视觉冲击力的 ,现阶段只能摆弄一下简单的图表了。
---over----














 3465
3465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









