







ML实验-KNN(续)
实验(3):社交网站魅力指数
import os
os.chdir('l:\python\csdnblog\ml_1')
os.getcwd()
import KNN
reload(KNN)
datingDataMat,datingLabels=KNN.file2matrix('datingTestSet2.txt')
import matplotlib
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(111)
from numpy import *
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],
15.0*array(datingLabels),15.0*array(datingLabels))
plt.xlabel('spend time on game')
plt.ylabel('ice cream per week')
plt.show()<img src="https://img-blog.csdn.net/20160407234648093?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);" />datingDataMat[:,1],datingDataMat[:,2]<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);">修改为:</span><pre name="code" class="python">datingDataMat[:,0],datingDataMat[:,1]<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);">再次运行脚本可以发现图像变为了如下</span>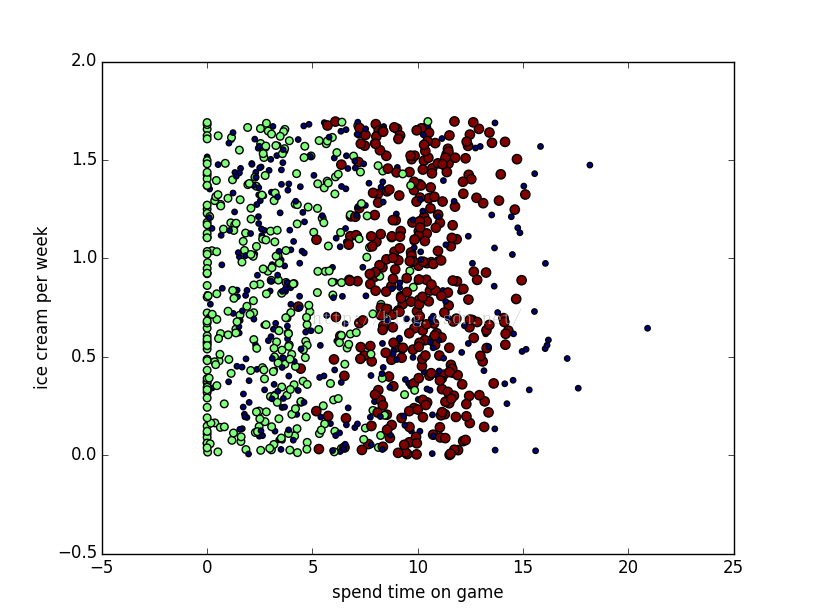
现在红色与绿色的已经可以清晰的区分开来,但是蓝色的特征夹杂在绿色和红色的特征之间,仍然不能很好的区分出来,现在我们尝试再把代码修改为如下
<pre name="code" class="python">#!/usr/bin/env python
# _*_ coding: utf-8 _*_
import os
os.chdir('l:\python\csdnblog\ml_1')
os.getcwd()
import KNN
reload(KNN)
import matplotlib
import matplotlib.pyplot as plt
matrix, labels = KNN.file2matrix('datingTestSet2.txt')
print matrix
print labels
plt.figure(figsize=(8, 5), dpi=80)
axes = plt.subplot(111)
type1_x = []
type1_y = []
type2_x = []
type2_y = []
type3_x = []
type3_y = []
print 'range(len(labels)):'
print range(len(labels))
for i in range(len(labels)):
if labels[i] == 1:
type1_x.append(matrix[i][0])
type1_y.append(matrix[i][1])
if labels[i] == 2:
type2_x.append(matrix[i][0])
type2_y.append(matrix[i][1])
if labels[i] == 3:
print i, ':', labels[i], ':', type(labels[i])
type3_x.append(matrix[i][0])
type3_y.append(matrix[i][1])
type1 = axes.scatter(type1_x, type1_y, s=20, c='red')
type2 = axes.scatter(type2_x, type2_y, s=40, c='green')
type3 = axes.scatter(type3_x, type3_y, s=50, c='blue')
plt.xlabel('max flying distance')
plt.ylabel('spend time in life')
axes.legend((type1, type2, type3), ('like', 'like-dislike', 'impressive'), loc=2)
plt.show()
运行上述代码可以得到如下结果
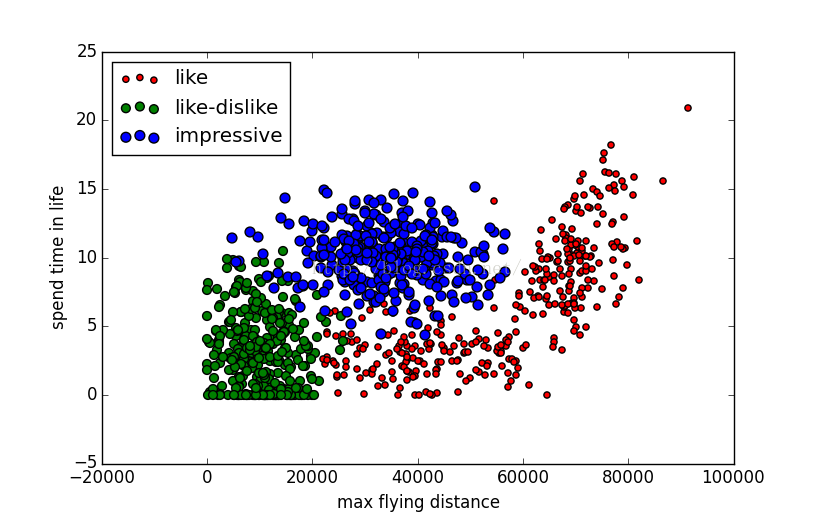
总结:现在数据的三维特征已经被较好的区分出来,参考这幅图,再联想一下自身条件,感觉自己魅力值还蛮高的啊,可是为什么……
实验(4):手写体识别
手写体的数据文件可以到我的Git上下载,地址为:()对不起,今天网络不好,没有上传上去,带我上传好了,再回来修改地址
#! __*__ coding:utf-8 __*__
from numpy import *
import operator
from os import listdir
# 建立分类器
def classifykNN(inX, dataset, labels, k):
"""
inX 是输入的测试样本,是一个[x, y]样式的
dataset 是训练样本集
labels 是训练样本标签
k 是top k最相近的
"""
dataSetSize = dataset.shape[0]
# 与样本的差分矩阵,用到了 tile 函数
diffMat = tile(inX, (dataSetSize, 1)) - dataset
# 差分矩阵求平方
sqDiffMat = diffMat ** 2
# 对平方矩阵进行累加
sqDistance = sqDiffMat.sum(axis=1)
# 取欧式距离作为度量
distance = sqDistance ** 0.5
# 对得到的测试数据与样本的距离进行排序,返回排序前索引
sortedDistIndicies = distance.argsort()
# 存放最终结果的字典
classCount = {}
# 统计前 k 个距离最近的样本的分类
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 把问件中的数据转化成矩阵
def file2matrix(filename):
"""
从文件中读入训练数据,并存储为矩阵
"""
fr = open(filename)
#获取 n=样本的行数
numberOfLines = len(fr.readlines())
#创建一个2维矩阵用于存放训练样本数据,一共有n行,每一行存放3个数据
returnMat = zeros((numberOfLines,3))
#创建一个1维数组用于存放训练样本标签
classLabelVector = []
fr = open(filename)
index = 0
for line in fr.readlines():
# 把回车符号给去掉
line = line.strip()
# 把每一行数据用\t分割
listFromLine = line.split('\t')
# 把分割好的数据放至数据集,其中index是该样本数据的下标,就是放到第几行
returnMat[index,:] = listFromLine[0:3]
# 把该样本对应的标签放至标签集,顺序与样本集对应。
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
# 数据的归一化
def autoNorm(dataSet):
"""
训练数据归一化
"""
# 获取数据集中每一列的最小数值
minVals = dataSet.min(0)
# 获取数据集中每一列的最大数值
maxVals = dataSet.max(0)
# 最大值与最小的差值
ranges = maxVals - minVals
# 创建一个与dataSet同shape的全0矩阵,用于存放归一化后的数据
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
# 减去最小值
normDataSet = dataSet - tile(minVals, (m,1))
# 把最大最小差值扩充为dataSet同shape,然后作商,是指对应元素进行除法运算,而不是矩阵除法。
# 矩阵除法在numpy中要用linalg.solve(A,B)
# 进行归一化
normDataSet = normDataSet/tile(ranges, (m,1))
return normDataSet, ranges, minVals
def img2vector(filename):
"""
将图片数据转换为01矩阵。
每张图片是32*32像素,也就是一共1024个字节。
因此转换的时候,每行表示一个样本,每个样本含1024个字节。
"""
# 每个样本数据是1024=32*32个字节
returnVect = zeros((1,1024))
fr = open(filename)
# 循环读取32行,32列。
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
# 加载训练数据
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
# 从文件名中解析出当前图像的标签,也就是数字是几
fileNameStr = trainingFileList[i]
#去掉格式名 .txt
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
# 加载测试数据
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
# 迭代整个数组
for i in range(mTest):
fileNameStr = testFileList[i]
#去掉格式名 .txt
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classifykNN(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d, The predict result is: %s" % (classifierResult, classNumStr, classifierResult==classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d / %d" %(errorCount, mTest)
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
if __name__== "__main__":
handwritingClassTest()
运行此脚本,可以看到,python 上显示的测试结果与实际结果对比,最后给出测试集的错误率
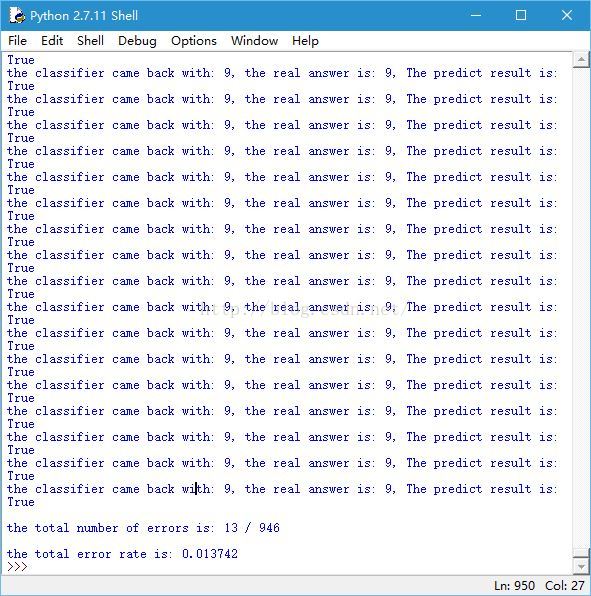
总结:共有 2000 个标签样本与 900 个测试数据,这 900 个测试数据要和 2000 个标签样本计算距离,每个数据为 32*32 =1024,可见
KNN 的计算速度是很慢的,需要存储标签数据与测试数据,内存开销也比较大,另外不能给出数据的直观在意识层面的解释也是 KNN 的缺点。














 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









