






CNTK配置文件详解
逻辑回归配置
我们使用NDL配置我们的配置文件,我们要定义特征和标签,还有学习参数,根节点。这些要在NDLNetworkBuilder中定义,
我们在我们的.cntk中描述我们的网络。我们可以在这里得到LR数据 这里
NDLNetworkBuilder = [
run = ndlLR
ndlLR = [
# sample and label dimensions
SDim = 2
LDim = 1
features = Input(SDim, 1)
labels = Input(LDim, 1)
# parameters to learn
B = Parameter(LDim, 1)
W = Parameter(LDim, SDim)
# operations
t = Times(W, features)
z = Plus(t, B)
s = Sigmoid(z)
LR = Logistic(labels, s)
EP = SquareError(labels, s)
# root nodes
FeatureNodes = (features)
LabelNodes = (labels)
CriteriaNodes = (LR)
EvalNodes = (EP)
OutputNodes = (s)
]
]我们使用run=ndlLR 让我们CNTK网络运行
Input(SDim) SDim = 2 其实应该写Input(SDim,1),这里1可以省略 这个方法定义了两行一列的输入矩阵,
labels = Input(LDim) 因为我们是逻辑回归所以我们的标签只有 0 或 1
我们知道逻辑回归可以表示为:
y = W_0 + W_1 x_1 + W_2 x_2 + ...
同理我们使用Parameter定义权值 W 和 偏置B
对这些值进行操作,
用W乘features,再加上B 把得到的值压缩
t = Times(W, features)
z = Plus(t, B)
s = Sigmoid(z)当然也可以这么写
s = Sigmoid(Plus(Times(W, features), B)) LR = Logistic(labels, s) -sum(labels * log(s) + (1 - labels) * log(1 - s) ) EP = SquareError(labels, s) FeatureNodes = (features)
LabelNodes = (labels)
CriteriaNodes = (LR)
EvalNodes = (EP)
OutputNodes = (s)指定运行命令
在CNTK的配置文件中,第一行我们要设置运行命令
command=Train:Output:dumpNodeInfo:Test你可以设置很多命令用:分割,CNTK将按照顺序一个一个运行,让我们开始讲Train的配置
Train
# training config
Train = [
action="train"
NDLNetworkBuilder = [
...
]
SGD = [
...
]
reader = [
...
]这是我们第一个action ,我们在训练里添加NDLNetworkBuilder设置参数节点,SGD和reader我会在下面说到。
Output
Output命令在CNTK中是这样定义:
# output the results
Output=[
action="write"
reader=[
readerType="UCIFastReader"
file="Test.txt"
features=[
dim=$dimension$
start=0
]
labels=[
start=2
dim=1
labelType=regression
]
]
outputPath = "LR.txt" # dump the output as text
]Test
测试命令使用 action test 它要在输出命令之前
Test=[
action="test"
reader=[
readerType="UCIFastReader"
file="Test.txt"
features=[
dim=2
start=0
]
labels=[
start=$dimension$
dim=1
labelDim=2
]
]
]reader的设置我会在后面讲,这里这个测试使用来指导模型的参数更新 测试会把我们算出来的值和标签比较,并且把误差保存输出,我们在网络描述是定义过:
EP = SquareError(labels, s)
EvalNodes = (EP)
DumpNodeInof
dumpnodeinof被定义成这样:
dumpNodeInfo=[
action=dumpnode
printValues=true
]这个命令是用来输出在网络定义的参数的值的,在调试时或者再做进一步处理时这是很有用的,这个命令会把我们的参数输出到Models文件夹下的文件名叫LR.dnn.__AllNodes__.txt,通过我们的训练我们得到我们网络的参数
B=LearnableParameter [1,1] NeedGradient=true
-6.67130613
####################################################################
EP=SquareError ( labels , s )
features=InputValue [ 2 x 1 {1,2} ]
labels=InputValue [ 1 x 1 {1,1} ]
LR=Logistic ( labels , s )
s=Sigmoid ( z )
t=Times ( W , features )
W=LearnableParameter [1,2] NeedGradient=true
1.23924482 1.59913719
####################################################################
z=Plus ( t , B )E = x_1 w_1 + x_2 w_2 +B
标准方程y = mx + B线与y = x_2,x = x_1,斜率m =(- w_1 / w_2),和偏置b = b / w_2。如果我们再插值从节点文件B = -6.67130613,W1 = 1.23924482,和W2 = 1.59913719.使用python画图把数据也放进去我
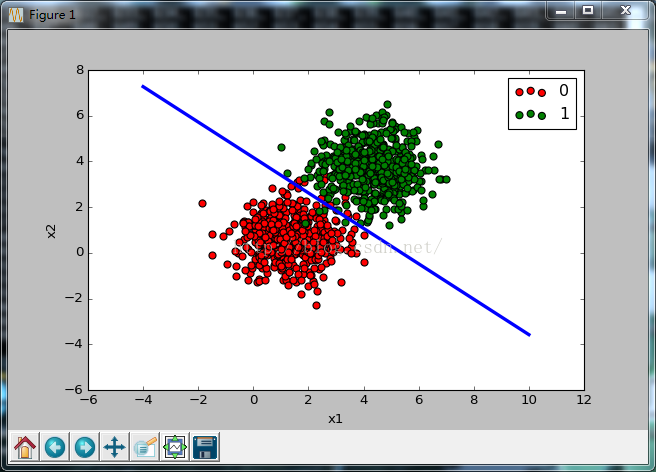
Set up the learning algorithm
我们现在设置我们的学习参数,CNTK需要使用一个学习算法,这里我们使用梯度下降算法(SGD),SGD使用一定数量的子集训练用平均值更新参数SGD = [
epochSize=0
minibatchSize=25
learningRatesPerMB=0.1
maxEpochs=50
]learningRatesPerMB设置SGD的学习率,我们可以设置一个固定的学习率,也可以设置一个不断下降的学习率:
learningRatesPerMB=0.5:0.2*5:0.1
也可以写成这样:
learningRatesPerMB=0.5:0.2:0.2:0.2:0.2:0.2:0.1
学习率会不断下降直到到达0.1
maxEpochs 是一个早期停止阀值,一旦错误达到这个阀值,学习就会提前停止,CNTK还之前其他形式的早期停止。Reader
现在我们讲读写数据的模块, 每一个reader 被定义在配置文件中的,我们来看一个例子。
reader = [
readerType = "UCIFastReader"
file = "Train.txt"
features = [
start = 0
dim = 2
]
labels = [
start = 2
dim = 1
labelType = regression
]
]readerType: 我们的例子中我们使用UCIFastReader这是最简单的文件格式,每一行描述一个实例,有一个特征向量和标签,还有就是设置分割符默认是空格。可以自定义一个比如:
customdelimiter =“;”
file:包含数据的文件。
dim:是定义有多少这个标签或特征占多少行。
start:代表特征或便签从第几行开始。
labelMappingFile:第一个文件里面是每个便签的名字。每个标签占一行。
labelType:如果设置成regression可以不需要标签匹配文件,但我在使用的时候报了错误说缺少匹配文件。
整个文件
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE file in the project root for full license information.
# logistic regression cntk script -- Network Description Language
# which commands to run
command=Train:Output:dumpNodeInfo:Test
#required...
modelPath="Models/LR_reg.dnn" # where to write the model to
deviceId=-1 # CPU
dimension=2 # input data dimensions
# training config
Train=[
action="train"
NDLNetworkBuilder=[
run=ndlLR
ndlLR=[
# sample and label dimensions
SDim=$dimension$
LDim=1
features=Input(SDim, 1)
labels=Input(LDim, 1)
# parameters to learn
B = Parameter(LDim)
W = Parameter(LDim, SDim)
# operations
t = Times(W, features)
z = Plus(t, B)
s = Sigmoid(z)
LR = Logistic(labels, s)
EP = SquareError(labels, s)
# root nodes
FeatureNodes=(features)
LabelNodes=(labels)
CriteriaNodes=(LR)
EvalNodes=(EP)
OutputNodes=(s)
]
]
SGD = [
epochSize=0 # =0 means size of the training set
minibatchSize=25
learningRatesPerMB=0.1 # learning rates per MB
maxEpochs=50
]
# parameter values for the reader
reader = [
readerType = "UCIFastReader"
file = "Train.txt"
miniBatchMode = "partial"
verbosity = 1
features=[
dim = $dimension$
start = 0
]
labels=[
start = $dimension$ # skip $dimension$ elements before reading the label (i.e. the first two dimensions so we have "x1 x2 y" basically)
dim = 1 # label has 1 dimension
labelType=regression
labelMappingFile = "a.txt"
]
]
]
# test
Test=[
action="test"
reader=[
readerType="UCIFastReader"
file="Test.txt"
features=[
dim=$dimension$
start=0
]
labels=[
start = $dimension$ # skip $dimension$ elements before reading the label (i.e. the first two dimensions so we have "x1 x2 y" basically)
dim = 1 # label has 1 dimension
labelType=regression
labelMappingFile = "a.txt"
]
]
]
# output the results
Output=[
action="write"
reader=[
readerType="UCIFastReader"
file="Test.txt"
features=[
dim=$dimension$
start=0
]
labels=[
start = $dimension$
dim = 1 # label has 1 dimension
labelType=regression
labelMappingFile = "a.txt"
]
]
outputPath = "LR.txt" # dump the output as text
]
dumpNodeInfo=[
action=dumpnode
printValues=true
]
配置完CNTK,如果你的环境变量已经配好了
我们在有数据的文件夹下使用
cntk configFile=lr_ndl.cntk如果我们想用GPU我们可以,我么你需要在配置文件
# deviceId=-1 for CPU, >=0 for GPU devices, "auto" chooses the best GPU, or CPU if no usable GPU is available
deviceId = -1














 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









