







假设用机器学习方法解决某个二元分类问题,在分析比较不同模型时常看到这些指标。
四个概念:TP,FP,TN,FN
TP(True Positive):在判定为positive的样本中,判断正确的数目。
FP(False Positive):在判定为positive的样本中,判断错误的数目。
TN(True Negative):在判定为negative的样本中,判断正确的数目。
FN(False Negative):在判定为negative的样本中,判断错误的数目。
判断正误是根据样本的label或称之为标准答案,来计算的。模型或规则给出的判定P或N可以看作是二分类类别。
这些值计算一般是在验证集(validation set)上进行的。
计算 precision,recall,accuracy,F1 score
精确率(precision):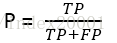
召回率(recall): 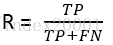
准确率(accuracy):
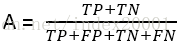
可见,精确率和召回率是相互影响的,理想情况下两者都高,但是一般情况下准确率高,召回率就低;召回率高,准确率就低;如果两者都低,应该是哪里算的有问题。
在两者都要求高的情况下,综合衡量P和R就用F值:
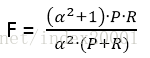
α为1时,就是常见的F1值(F1 score):
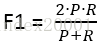
一般多个模型假设进行比较时,F1 score越高,说明它越好。
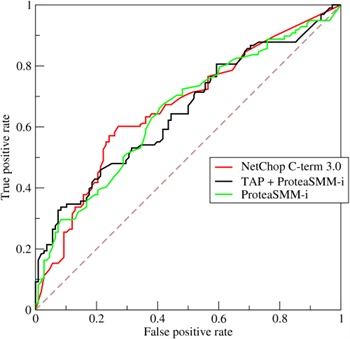
ROC曲线和AUC
ROC(Receiver Operating Characteristic)和AUC(Area UnderCharacteristic)常被用来评价一个二分类器的优劣。
ROC曲线一般横轴是FPR,纵轴是TPR。AUC为曲线下面的面积,一般AUC值越大,说明模型越好。
曲线示例:














 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









