







语言模型(Language Model,LM),给出一句话的前k个词,希望它可以预测第k+1个词是什么,即给出一个第k+1个词可能出现的概率的分布p(xk+1|x1,x2,...,xk)。
在报告里听到用PPL衡量语言模型收敛情况,于是从公式角度来理解一下该指标的意义。
Perplexity定义
PPL是用在自然语言处理领域(NLP)中,衡量语言模型好坏的指标。它主要是根据每个词来估计一句话出现的概率,并用句子长度作normalize,公式为
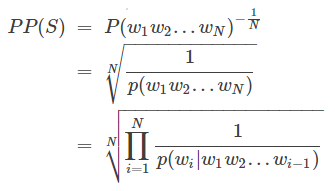
S代表sentence,N是句子长度,p(wi)是第i个词的概率。第一个词就是 p(w1|w0),而w0是START,表示句子的起始,是个占位符。
这个式子可以这样理解,PPL越小,p(wi)则越大,一句我们期望的sentence出现的概率就越高。
还有人说,Perplexity可以认为是average branch factor(平均分支系数),即预测下一个词时可以有多少种选择。别人在作报告时说模型的PPL下降到90,可以直观地理解为,在模型生成一句话时下一个词有90个合理选择,可选词数越少,我们大致认为模型越准确。这样也能解释,为什么PPL越小,模型越好。
Perplexity另一种表达
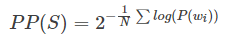
好像在讲到unigram时,常常用到PPL的这种形式,从表达式上看和前面的意义是一样的,只不过wi不再是单个词,它表示第i个bigram或其他单位量。
Perplexity的影响因素
这些是听报告了解的:
1. 训练数据集越大,PPL会下降得更低,1billion dataset和10万dataset训练效果是很不一样的;
2. 数据中的标点会对模型的PPL产生很大影响,一个句号能让PPL波动几十,标点的预测总是不稳定;
3. 预测语句中的“的,了”等词也对PPL有很大影响,可能“我借你的书”比“我借你书”的指标值小几十,但从语义上分析有没有这些停用词并不能完全代表句子生成的好坏。
所以,语言模型评估时我们可以用perplexity大致估计训练效果,作出判断和分析,但它不是完全意义上的标准,具体问题还是要具体分析。

















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









