






(点击上方公众号,可快速关注)
来源: Python开发者 - 路易十四
http://python.jobbole.com/86328/
当你能够针对一个url进行请求,获取数据,继续请求的时候,说明你的爬虫已经可以自给自足的爬起来。但是这样的爬虫其效率将会严重限制在单进程效率极限之下,时间的主要消耗还是在请求返回的等待时间,如果想进一步提高效率那么多进程以及分布式就会你提高效率的最好手段。而且分布式并不意味着你一定要很多台电脑,只要你在本机测试通过一样可以方便迁移。构建分布式爬虫主要是构建分布式环境,至于写爬虫并不复杂。咱们一步步来。
小怪兽镇楼

目录:
redis简介
安装测试
多机测试
scrapy_redis
简单应用测试
多机协作的redis
1.redis简介:
redis是一个key-value存储系统,速度很快因为将数据存放在内存,在必要时可以转到硬盘。支持数据类型有string,lists,sets,zsets。这些数据类型都支持push/pop,add/remove以及取交集并集差集等操作,对这些操作都是原子性的,redis还支持各种不同的排序能力。
redis本身属于一个数据库类型的系统,不过在分布式中反而是他的队列性特别好用,就被开发成分布式的基石。所以今天我们测试的内容就是在多台机器上安装redis,然后让一台作为服务器别的机器开启客户端共享队列。
2.安装测试:
我就不搬砖了。下面的链接非常详细(重点博文):
http://blog.fens.me/linux-redis-install/
还有redis有大量的命令,详细可以查询此处
http://www.3fwork.com/b902/001557MYM005172/
还有修改配置打开远程访问之类的
http://www.ttlsa.com/redis/install-redis-on-ubuntu/
3.多机测试:
使用你的服务器(有远程服务器最好,没有的话也可以在自己本机安装),按照上面安装好环境后,先去除保护的开启服务器端(未来长久使用要改配置)
如果报错,请直接改配值,将127.0.0.1注释掉(系统的防火墙要关)
redis-server --protected-mode no
然后先再开一个终端链接到服务器,在服务器本机的环境也开一个客户端,(只是因为机器不多)
redis-cli -h ip地址 -p 6379
回车之后会看到进入一个交互命令行界面。
首先增加一个key对应的value
set key1 lala
其次查看这个值
get key1
然后返回你的个人电脑,也通过客户端链接过去然后查看这个值
get key1
如果出现同样的lala。那么说明分布式的环境已经搭建好了。
4.scrapy_redis
这个是如何运行的请看这里:
https://www.zhihu.com/question/32302268/answer/55724369
本次的测试项目就是运用了一个共享队列而已,还没有增加别的多种功能。
因为scrapy——redis使用起来需要环境配置的比较麻烦,还得改写其中中间件,想进一步学习在scrapy中用redis可以再找文章。
5.简单应用测试,分布式抓妹子图网
一般而言分布式至少需要两个程序:完整代码我放在github上:https://github.com/luyishisi/WebCrawlers/tree/master/request
一个用于捕捉待爬队列,并且加入到队列。如果待爬队列可以通过一定的规律算出来则可以轻松直接push到队列中
另外一个则是读取待爬队列进行新一轮的爬取工作
要实现捕捉待爬队列并且加入见下代码:
1:头文件:
requets用于发请求,re正则匹配,time控制速度,redis分布式。headers用于简单的反反爬
import requests
import re
import time
from redis import Redis
headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' }
2:加任务队列
计算并发送请求获取根页面的html从中匹配到img的地址发送到本地redis中。
def push_redis_list():
r = Redis()
print r.keys('*')
for i in range(100):
num = 5100+i;#抓取的取件仅在5100--5200之间
url ='http://www.meizitu.com/a/'+ str(num) +'.html'
img_url = requests.get(url,timeout=30)
#print img_url.text
#time.sleep(10)
img_url_list = re.findall('http://pic.meizitu.com/wp-content/uploads/201.*.jpg',img_url.text)
print img_url_list
for temp_img_url in img_url_list:
l = len(re.findall('limg',temp_img_url))
#print l
if(l == 0):
print "url: ",temp_img_url
r.lpush('meizitu',temp_img_url)
print r.llen('meizitu')
return 0
3:读任务队列
def get_big_img_url():
r = Redis()
print r.keys('*')
while(1):
try:
url = r.lpop('meizitu')
download(url)
time.sleep(1)
print url
except:
print "请求求发送失败重试"
time.sleep(10)
continue
return 0
4:download函数用于下载
def download(url):
try:
r = requests.get(url,headers=headers,timeout = 50)
name = int(time.time())
f = open('./pic/'+str(name)+'.jpg','wb')
f.write(r.content)
f.close()
except Exception,e:
print Exception,":",e
5:main
开一个客户端运行push_redis_list 函数,别的可以开启任意多个客户端运行get_big_img_url 函数,则简单的分布式就构建完成
if __name__ == '__main__':
url = 'http://www.meizitu.com/a/list_1_'
print "begin"
#push_redis_list(5100)#开启则加任务队列.其中的值请限制在5400以内。不过是用于计算页码的
#get_big_img_url()#开启则运行爬取任务
运行的过程中你可以看一下该文件夹下是否有一个pic的文件夹,所有图片存储其中。
运行截图:图一加入任务队列
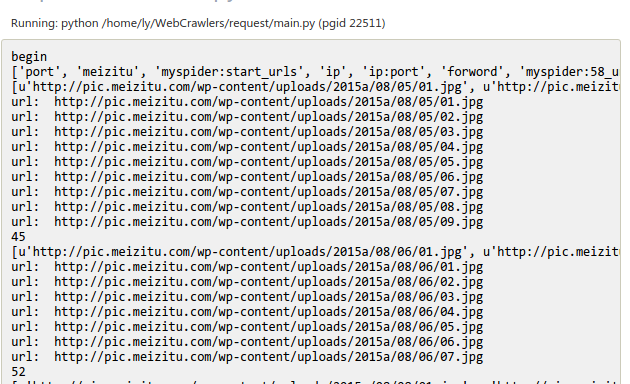
图二:单个客户端进行读取任务队列进行爬取

图三:截个图,比较模糊应该不会查水表吧。

6:多机协作的redis
要开启多机合作的redis分布式,也并不困难,最好将redis服务器放置在某服务器上,有固定ip。同时设定好安全密码或者固定的ip白名单,redis直接开放很容易被黑了。
然后修改代码建立redis连接的部分,。如下:
r=Redis(host=REDIS_HOST, port=REDIS_PORT,password=PASSWORD)
然后便是依旧一样的使用。
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









