







 这篇博客介绍了如何通过分析安卓微信聊天数据库,使用Python和ECharts进行数据可视化,从而创建一份“爱情报表”。内容包括获取聊天数据库、解密数据库、Python数据处理和使用ECharts制作聊天时段分布、字符云等图表。
这篇博客介绍了如何通过分析安卓微信聊天数据库,使用Python和ECharts进行数据可视化,从而创建一份“爱情报表”。内容包括获取聊天数据库、解密数据库、Python数据处理和使用ECharts制作聊天时段分布、字符云等图表。
微信聊天记录数据分析
或许每个人的微信列表里都有几个不舍删除的聊天记录,经年累月,这些聊天记录越积越多,终将成为你和这个人之间的美好回忆。这些回忆中有许多信息值得挖掘,尤其是情侣之间,将这些信息统计出来做一份“爱情报表”,一定会给自己的另一半带去一份惊喜。
工作内容
- 获取微信聊天数据库
- 解密数据库获取聊天数据
- 使用Python分析数据
- ECharts(或者pyecharts)做数据可视化
获取聊天数据库
这个教程主要是针对安卓手机用户的,对于IOS系统,不太清楚如何获取聊天数据库,毕竟IOS系统生态非常封闭。安卓用户获取微信聊天数据库的方法很简单:
-
首先需要获取手机root权限
-
安装RE文件管理器(Root Explorer)
-
打开RE文件管理器,在路径/data/data/com.tencent.mm/MicroMsg下找到一个由32位字符串命名的文件夹,比如我的文件夹如下,这个32位字符串是mm+uin码进行md5加密后得到的(uin码后面会说)
-
进入该文件夹,找到EnMicroMsg.db,即为你的微信聊天数据库,将其复制出来并传到电脑上

解密数据库获取聊天数据
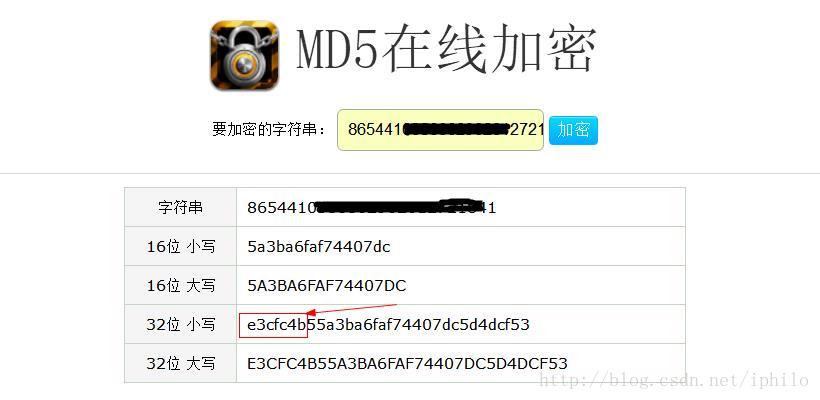
解密微信数据库,在网上有很多的教程,归结起来就是,数据库密码=md5(IMEI+uin)[0:7],意思就是,将你手机的IMEI码和你微信的uin码加起来用md5加密后得到一串32位的字符串,取其前7位即为数据库的密码。但是在操作的过程中会有一些坑。
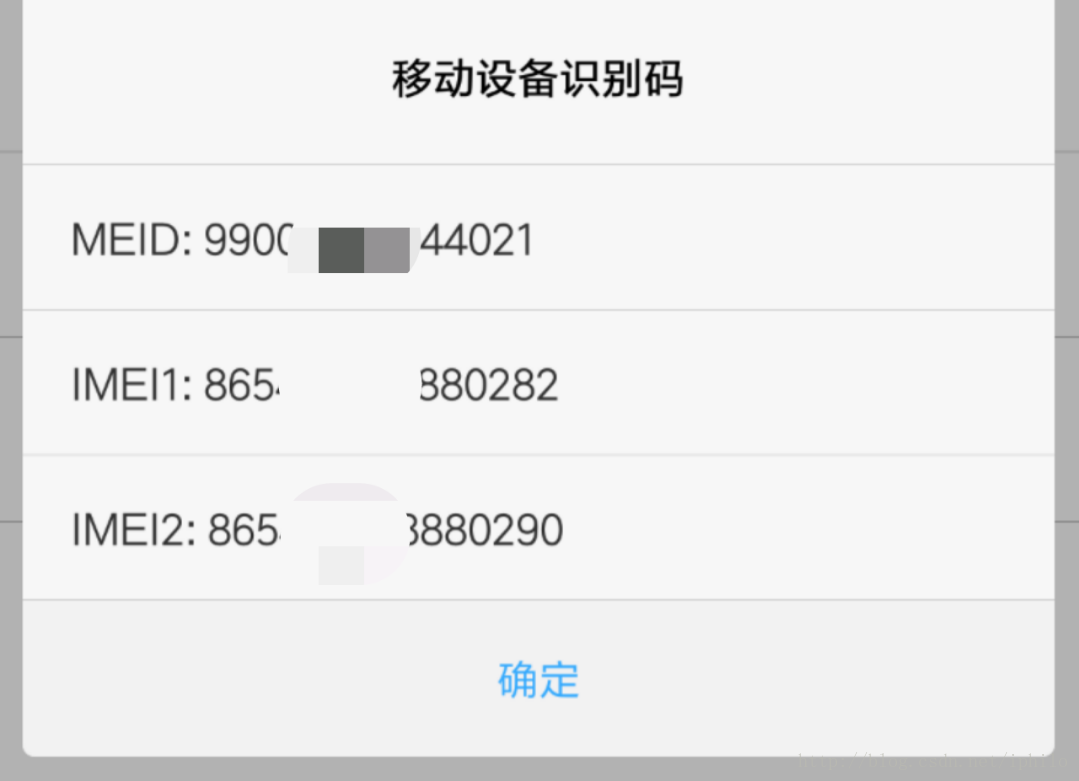
- 获取IMEI码,即打开手机的拨号界面,输入* #06#,这时就会自动弹出你的IMEI码,但是对于双卡用户,操作的时候会有些懵,比如我用的小米6,输入* #06#后会出来3个码……其实也不用懵,MEID码直接无视,下面两个IMEI码的话,一般都是取第一个,当然不放心的话可以两个都试试。
- 获取uin码,再次打开RE文件管理器,在路径/data/data/com.tencent.mm/shared_prefs下找到auth_infokey_prefs.xml文件并打开,找到如下文字,其中value后面跟着的就是你的uin码了,我的是8位,每个人uin码的位数可能不一样。
- 在获取到IMEI码和uin码之后就可以相加后使用md5加密得到密码了。加密可以使用在线md5工具,密码是小写32位md5值的前7位。
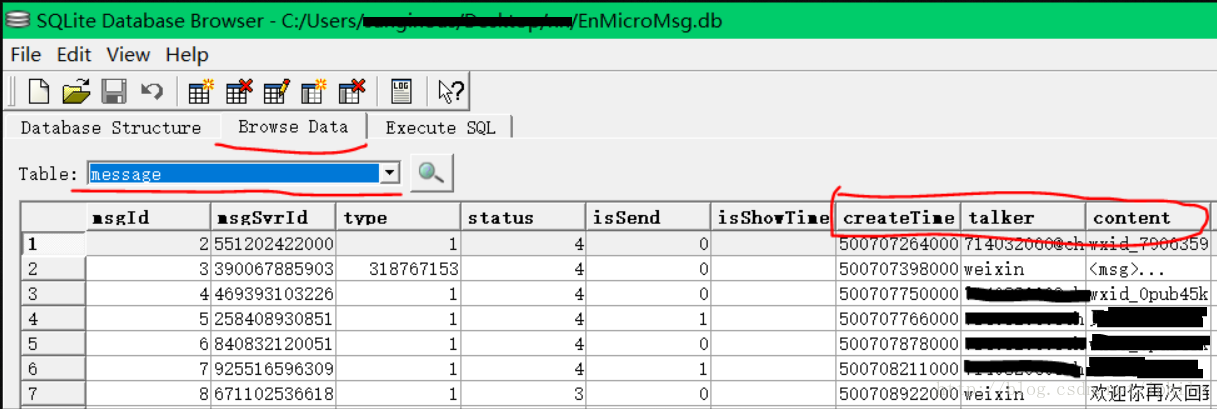
- 获取到密码后就是解密数据库了。工具是sqlcipher.exe,我在网上找了很多版本,这个是最好用的:https://pan.baidu.com/s/1pLlLOA6ZDV5Nl0beMFvM4A (密码:kfe2)。打开后找到message表,这里就是全部的聊天记录了,关键的信息就是createTime、talker以及content这三列了,值得注意的是,数据库中保存的时间数据是时间戳,并且每一个数据后面都多出了三位0,在进行数据分析时需要把这三个0剔除。然后我们依次点击File–>Export–>Table as CSV file,将message表导出,我们就可以开始进行数据分析了。导出的文件默认有.csv和.txt两种,后缀需要手动写上去。此外,如果直接读取这个文件的话可能会存在编码错误的问题,建议在保存csv文件以后,右键使用记事本打开,然后再另存为一个新的文件,编码使用utf-8。


使用Python分析数据
呼……终于进入正题了。聊天记录包含了非常丰富的数据,这里我只做了两个比较简单的例子,一个是针对时间做聊天时间段分布的统计;一个是针对内容做字符匹配,统计一些高频词汇出现的次数,比如“早安”、“晚安”、“想你”、“爱”等等(你懂的)。
读取数据
使用pandas读取csv文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2778
2778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









