




最近呆着无聊,尝试一下使用搜狗数据集的文本自动分类。
- 读取数据集中的文件
- 使用结巴分词去除停用词
- 计算每种分类CHI
图中N,A+C,B+D保持不变,可以省略。
- 取出CHI最高的词汇作为特征词
- 计算TF-ITF,作为特征词的权重
- TF(term frequency)就是分词出现的频率:该分词在该文档中出现的频率,算法是:(该分词在该文档出现的次数)/(该文档分词的总数),这个值越大表示这个词越重要,即权重就越大。
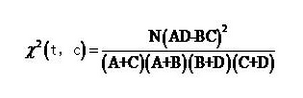
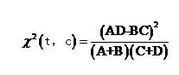
例如:一篇文档分词后,总共有500个分词,而分词”Hello”出现的次数是20次,则TF值是: tf =20/500=2/50=0.04
IDF(inversedocument frequency)逆向文件频率,一个文档库中,一个分词出现在的文档数越少越能和其它文档区别开来。算法是: log((总文档数/出现该分词的文档数)+0.01) ;(注加上0.01是为了防止log计算返回值为0)。
例如:一个文档库中总共有50篇文档,2篇文档中出现过“Hello”分词,则idf是:
Idf = log(50/2 + 0.01) = log(25.01)=1.39811369
TF-IDF结合计算就是 tf*idf,比如上面的“Hello”分词例子中:
TF-IDF = tf* idf = (20/500)* log(50/2 + 0.01)= 0.04*1.39811369=0.0559245476
7. 贝叶斯分类,使用nltk分类库,取70个训练集,30个测试集。
8. 计算正确率,准确率,召回率
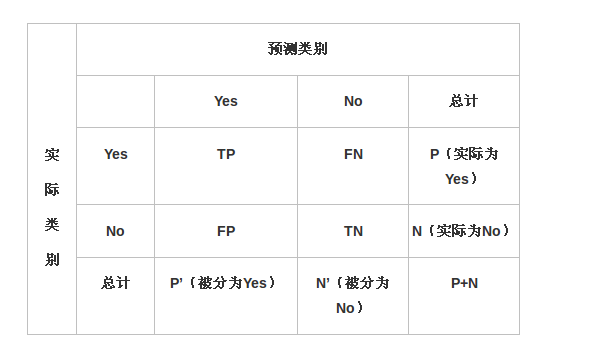
准确率precision:TP/(TP+FP)
召回率recall:TP/(TP+FN)
# -*- coding: utf-8 -*-
import jieba
import nltk
import os
import time
from math import log
import json
import collections
floder_path = '/home/zhangbo/SogouC.reduced/Reduced'
#该文件夹下宗共有9个文件夹,分别存储9大类的新闻数据
floder_list = os.listdir(floder_path)
class_list = []
nClass = 0
N = 99
train_set = []
test_set = []
all_words = {}
#用于记录CHI公示中的A值
A = {}
#记录每个文件的处理事件
process_time = []
TFIDF = {}
#读取停词表
stop_words_file = open('stop_words_ch.txt', 'r')
stopwords_list = []
for line in stop_words_file.readlines():
stopwords_list.append(line.decode('gbk')[:-1])
#遍历每个类别文件夹
for i in range(len(floder_list)):
new_floder_path = floder_path + '/' + floder_list[i]
#files中保存每个类别文件的具体文件列表
files = os.listdir(new_floder_path)
#class_list用于保存0-8九个新闻类别
class_list.append(nClass)
A[nClass] = {}
TFIDF[nClass] = {}
j = 0
#最多读取100个文件,或者全部夺取
nFile = min([len(files), N])
for file in files:
if j > N:
break
starttime = time.clock()
#标志位,用于表示这个文件中是否已经出现过某个单词。以防止重复计算//取xiao
#读取文件内容
fobj = open(new_floder_path + '/' + file, 'r')
raw = fobj.read()
TFIDF[nClass][j] = {}
#使用结巴分词把文件进行切分
word_list = list(jieba.cut(raw, cut_all =False))
for word in word_list:
if word in stopwords_list:
word_list.remove(word)
#word_set用于统计A[nClass]
word_set = set(word_list)
for word in word_set:
if A[nClass].has_key(word):
A[nClass][word] += 1
else:
A[nClass][word] = 1
#统计所有类别所有文件出现的词频,并保存在all_words里面。
for word in word_list:
if word in TFIDF[nClass][j]:
TFIDF[nClass][j][word] += 1
else:
TFIDF[nClass][j][word] = 1
if all_words.has_key(word):
all_words[word] += 1
else:
all_words[word] = 1
#将每个类别中的nFile个文件进行训练/测试集划分,比例是3:7.分别存放于train_set/test_set
if j>0.3*nFile:
train_set.append((word_list, class_list[i], j))
else:
test_set.append((word_list, class_list[i], j))
fobj.close()
j+=1
end_time = time.clock()
#记录每个文件处理时间
process_time.append(end_time - starttime)
#打印中间结果信息。
print "Folder ", i, "-file-", j, "all_words length = ", len(all_words.keys()), \
"process time:", (end_time - starttime)
nClass += 1
#用于存储CHI公式中的B值
B = {}
for key in A:
B[key] = {}
for word in A[key]:
B[key][word] = 0
for kk in A:
if kk != key and A[kk].has_key(word):
B[key][word] += A[kk][word]
'''
执行到这里我们就已经将所有文件进行了预处理。获得了以下几个重要的全局变量
1,process_time:存储所有文件的处理时间
2,train_set:存储训练文件样本集。每一个元素(word_list, class_list[i]),即一个文件的单词表(结巴分词之后)和其类别
3,test_set:存储测试文件样本集。每一个元素(word_list, class_list[i]),即一个文件的单词表(结巴分词之后)和其类别
4,all_words:所有出现过的单词及其出现频率。
'''
#根据词频对all_words进行排序
all_words_list = sorted(all_words.items(), key=lambda e:e[1], reverse=True)
word_dict = []
#def word_dict_with_CHI_use_stopwords():
for i in range(0, 9):
CHI = {}
for word in A[i]:
temp = (A[i][word]*(800 - B[i][word]) - (100 - A[i][word])*B[i][word])^2/((A[i][word]+B[i][word])*(900 - A[i][word] - B[i][word]))
CHI[word] = temp * log(900/(A[i][word] + B[i][word]))
a = sorted(CHI.iteritems(), key=lambda t: t[1], reverse=True)[:150]
b = []
for aa in a:
b.append(aa[0])
word_dict.extend(b)
word_features = set(word_dict)
print len(word_features)
def document_features_TFIDF(document, cla, num):
document_words = set(document)
features = {}
for word in word_features:
if word in document_words:
features['contains(%s)' %word] = TFIDF[cla][num][word]*log(900/(A[cla][word]+B[cla][word]))
else:
features['contains(%s)' % word] = 0
return features
def cal_pre_recall(test_data,classifier,index):
# 计算准确度 声明集合处理测试集和预测集
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
# 对于每一类测试集,分别计算其准穷率和召回率
# 计算方法:得到TP的个数:len(refsets[index].intersection(testsets[index]))
#得到TP+FP的个数:len(testsets[index])
#得到TP+FN的个数:len(refsets[index])
for i, (word_feats, label) in enumerate(test_data):
# print word_feats
refsets[label].add(i)
observed = classifier.classify(word_feats)
#print i
#print label #test实际分类
#print observed #test预测分类
testsets[observed].add(i)
pre = float(len(refsets[index].intersection(testsets[index]))) / len(testsets[index])
recall = float(len(refsets[index].intersection(testsets[index]))) / len(refsets[index])
f_value = 2 * pre * recall / (pre + recall)
return pre, recall,f_value
def TextClassification_TFIDF():
#计算训练/测试数据集中所有文档对应的特征向量和类别。
train_data = [(document_features_TFIDF(d, c, b), c) for (d, c, b) in train_set]
test_data = [(document_features_TFIDF(d, c, b), c) for (d, c, b) in test_set]
print "train number:", len(train_data), "\n test number:", len(test_data)
#训练分类器
classifier = nltk.NaiveBayesClassifier.train(train_data)
#调用cal_pre_recall函数得到准穷率召回率和F值
for i in range(0,8):
pre, recall, f_value = cal_pre_recall(test_data,classifier,i)
print "第",i,"种分类准穷率:",pre,",召回率:",recall,"F值为",f_value
test_accuracy = nltk.classify.accuracy(classifier, test_data)
print "test_accuracy:", test_accuracy
return test_accuracy
TextClassification_TFIDF()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









